Strojové učenie
Domáca úloha 1 - regresia
V tejto úlohe je cieľom nájsť funkciu, ktorá dobre odhaduje výstupnú hodnotu na základe vstupného vektora pomocou lineárnej a polynomiálnej regresie. Úlohou je nájsť vhodnú polynomiálnu transformáciu, vďaka ktorej bude regresná funkcia dobre odhadovať dáta, ale nebude dochádzať k javu "overfitting" - čiže k situácii, keď funkcia príliš dobre sleduje trénovaciu množinu aj na úkor toho, že už nesleduje samotný trend v dátach.
Úlohou teda je postupne vyskúšať rozličné transformačné funkcie 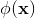 - teda rozličné polynómy a zistiť ktoré ešte dobre fitujú dáta a kde už dochádza k overfittingu. Aby sme presnejšie zistili, čo znamená "ešte dobre" - vyhodnocovať to budeme tak, že trénovacie dáta rozdelíme na trénovacie a validačné a vo vyhodnotení nás bude zaujímať akú celkovú chybu (súčet štvorcov chýb) robí natrénovaný model na validačnej množine. Použijeme pritom k-fold cross-validation. Riešením úlohy bude teda taký natrénovaný model, s takými parametrami, ktoré v k-fold crossvalidácii bude najlepší.
- teda rozličné polynómy a zistiť ktoré ešte dobre fitujú dáta a kde už dochádza k overfittingu. Aby sme presnejšie zistili, čo znamená "ešte dobre" - vyhodnocovať to budeme tak, že trénovacie dáta rozdelíme na trénovacie a validačné a vo vyhodnotení nás bude zaujímať akú celkovú chybu (súčet štvorcov chýb) robí natrénovaný model na validačnej množine. Použijeme pritom k-fold cross-validation. Riešením úlohy bude teda taký natrénovaný model, s takými parametrami, ktoré v k-fold crossvalidácii bude najlepší.
Bonusový bod: môžete zistiť, či má nejaký vplyv využitie všeobecných polynómov (všetky členy typu 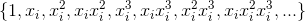 ), alebo iba jednoduché mocniny
), alebo iba jednoduché mocniny 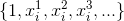 , prípadne kombinácia rozličných mocnín jednotlivých vstupných atribútov vstupného vektora (napr.
, prípadne kombinácia rozličných mocnín jednotlivých vstupných atribútov vstupného vektora (napr. 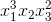 ).
).
Odovzdať treba:
- program, ktorý ste použili (v akomkoľvek jazyku, matlab je odporúčaný)
- trénovciu množinu, ktorú ste použili
- výstupné dátové súbory, ktoré ste použili na vyhodnotenie výsledku
- krátky dokument s popisom, čo ste robili, obsahujúci tabuľku, ktorá sumarizuje priemernú validačnú chybu pri k-fold crossvalidácii pre rozličné funkcie
- poteší aj graf nafitovaných funkcií ak náhodou budú dáta len jednorozmerné alebo dvojrozmerné (ak sú viacrozmerné a nejde to vizualizovať, tak graf netreba)
Trénovacie dáta: súčasťou úlohy je aj nájsť vhodné dáta, na ktorých bude polynomiálna regresia fungovať lepšie ako lineárna. Váš kolega navrhol tieto: data1/, nejaké príklady nájdete tu: datasets, alebo môžete použiť akékoľvek z predmetu Praktikum strojového učenia, alebo aj iné vlastné, ak sú vhodné (vhodnosť si môžete overiť u mňa, ak si chcete byť istí, že ich za vhodné budem považovať).
Riešenie prosím odovzdajte ako jeden zip-súbor do systému LIST do 31.10.2016.