CI05: Rozdiel medzi revíziami
(→Prvá idea: aproximácia vzorkovaním) |
(→Aproximácia Jaccardovej miery: MinHash) |
||
| Riadok 155: | Riadok 155: | ||
=== Aproximácia Jaccardovej miery: MinHash === | === Aproximácia Jaccardovej miery: MinHash === | ||
| − | Budeme mať náhodné hašovacie funkcie <math>h_1, h_2, \dots, h_s</math>. O každej | + | Budeme mať náhodné hašovacie funkcie <math>h_1, h_2, \dots, h_s</math>. |
| + | |||
| + | O každej hašovacej funkcii predpokladáme, že ak ju použijeme na nejakú množinu <math>A = \{a_1, a_2, \ldots, a_n\}</math>, tak <math>h(a_1), h(a_2), \ldots, h(a_n)<-math> bude náhodná permutácia množiny <math>A</math>. | ||
Pre množinu <math>A = \{a_1, a_2, \ldots, a_n\}</math> a hašovaciu funkciu ''h'' je <math>minHash_{h}(A)</math> je definovaný nasledovne: | Pre množinu <math>A = \{a_1, a_2, \ldots, a_n\}</math> a hašovaciu funkciu ''h'' je <math>minHash_{h}(A)</math> je definovaný nasledovne: | ||
| Riadok 162: | Riadok 164: | ||
Keďže <math>h</math> je náhodná hašovacia funkcia, tak sa na hodnotu <math>minHash(A)</math> môžeme pozerať ako na náhodnú premennú, ktorá reprezentuje rovnomerne náhodný výber prvku z množiny <math>A</math>. | Keďže <math>h</math> je náhodná hašovacia funkcia, tak sa na hodnotu <math>minHash(A)</math> môžeme pozerať ako na náhodnú premennú, ktorá reprezentuje rovnomerne náhodný výber prvku z množiny <math>A</math>. | ||
| − | Nech <math>X_i</math> je náhodná premenná, ktorá nadobúda hodnotu 1, ak <math>minHash_{h_i}(A) = minHash_{h_i}(B)</math>, a inak hodnotu 0. Potom <math>E[X_i] = J(A, B)</math> | + | Nech <math>X_i</math> je náhodná premenná, ktorá nadobúda hodnotu 1, ak <math>minHash_{h_i}(A) = minHash_{h_i}(B)</math>, a inak hodnotu 0. Potom <math>E[X_i] = J(A, B)</math>, lebo celkovo máme <math>|A\cup B|</math> prvkov a <math>J(A,B) = |A\cap B|/|A\cup B|</math> značí, aké percento z nich je v prieniku. |
| − | Takýmito hodnotami X_i teda nahradíme náhodné vzorky. | + | Takýmito hodnotami X_i teda nahradíme náhodné vzorky diskutované vyššie. |
Algoritmus: | Algoritmus: | ||
| − | * Pre kazdy dokument hasuj kazde slovo ''s'' funkciami, najdi minHash pre kazdu funkciu a uloz vektor tychto hodnot ako "sketch" dokumentu | + | * Pre kazdy dokument hasuj kazde slovo ''s'' funkciami, najdi minHash pre kazdu funkciu a uloz vektor tychto hodnot ako "sketch" dokumentu. Cas vypoctu pre dokument s n slovami je O(ns) |
| − | * Pre dva dokumenty | + | * Pre dva dokumenty porovname vektor po zlozkach a ak najdeme x zhod, J(A,B) odhadneme ako x/s. Cas vypoctu O(s) |
| − | * Vieme si tiez pre kazdu hasovaciu funkciu spravit slovnik, ktory mapuje minHash do zoznamu dokumentov a budeme porovnavat iba dvojice dokumentov, ktore sa niekde dostali do toho isteho zoznamu | + | * Vieme si tiez pre kazdu hasovaciu funkciu spravit slovnik, ktory mapuje minHash do zoznamu dokumentov a budeme porovnavat iba dvojice dokumentov, ktore sa niekde dostali do toho isteho zoznamu (t.j ich odhad J(A,B) bude nenulovy) |
| − | Alternativa: namiesto ''s'' roznych funkcii pouzijeme iba jednu a vezmeme nielen minimum, ale ''s'' najmensich prvkov. To usetri cas pri vypocte sketchu. | + | Alternativa: namiesto ''s'' roznych funkcii pouzijeme iba jednu a vezmeme nielen minimum, ale ''s'' najmensich prvkov. Potom J(A,B) odhadneme pomocou J(s_A, s_B) kde s_A je mnozina hodnot v sketchi mnoziny A. To usetri cas pri vypocte sketchu. |
Verzia zo dňa a času 12:30, 20. október 2022
Obsah
Vzorec na výpočet senzitivity jadra
- Uvažujme jadro dĺžky w (ako v programe BLAST pre nukleotidy)
- Uvažujme pravdepodobnostný model zarovnania, v ktorom má každá pozícia pravdepodobnosť p, že bude zhoda a (1-p), ze bude nezhoda alebo medzera, zarovnanie ma dlzku L
- Nahodna premenna X_i = 1 ak na pozicii i je zhoda, 0 inak
- Nahodna premenna Y_i = 1 ak na pozicii i zacina jadro, t.j. ak
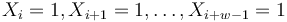
-
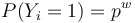 , nakolko X_i su navzajom nezavisle
, nakolko X_i su navzajom nezavisle
- Nech
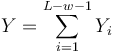
- Z linearity strednej hodnoty vieme lahko odhadnut
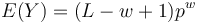
- Nas ale zaujima P(Y>0) = 1-P(Y=0)
- Ako by sme vedeli odhadnut simulaciou? My ale chceme rychlejsi sposob.
-
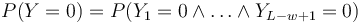
- Preco neplati,
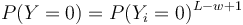 ?
?
- Jednotlive Y_i nie su nezavisle, napr.

- V postupnosti Y_i sa jednotky maju tendenciu zhlukovat spolu
- Jednotlive Y_i nie su nezavisle, napr.
- Pravdepodobnost nepritomnosti jadra P(Y=0) ale vieme spocitat dynamickym programovanim
- Nech A[n] je pravdepodobnost nepritomnosti jadra v prvých n stlcoch zarovnania (0<=n<=L)
- Budeme rozlisovat pripady podla toho, kolko je na konci X_1..X_n jednotiek
- Tento pocet moze byt 0..w-1 (ak by bol >=w, mali by sme vyskyt jadra)
-
![A[n]=\left\{{\begin{array}{ll}1&{\mbox{ak }}n<w\\\sum _{{i=0}}^{{w-1}}p^{i}(1-p)A[n-i-1]&{\mbox{ak }}n\geq w\\\end{array}}\right.](/vyuka/mbi/images/math/7/2/9/729e56b2edc35e00cbaa9a0e01b5787f.png)
V druhom riadku 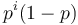 zodpoveda P(X_1...X_n konci presne i jednotkami).
zodpoveda P(X_1...X_n konci presne i jednotkami).
Minimizery: ako ušetriť pamäť a čas
- k-merom nazveme k za sebou iducich pismen v nejakom retazci (nukleotidov DNA)
- Zakladne pouzite jadier: pri porovnavani dvoch sekvencii (alebo mnozin sekvencii) uloz vsetky k-mery jednej sekvencie do slovnika (napr. hash tabulky), potom prechadzaj vsetky k-mery druhej sekvencie a hladaj ich v slovniku
- Priklad k=5,
- DB vľavo, k-mery a ich pozície uložené do slovníka,
- query vpravo, k-mery hľadané v slovníku, šípkou vyznačené nájdené k-mery (jadrá)
AGTGGCTGCCAGGCTGG cGaGGCTGCCtGGtTGG
AGTGG,0 CGAGG
GTGGC,1 GAGGC
TGGCT,2 AGGCT <-
GGCTG,3 GGCTG <-
GCTGC,4 GCTGC <-
CTGCC,5 CTGCC <-
TGCCA,6 TGCCT
GCCAG,7 GCCTG
CCAGG,8 CCTGG
CAGGC,9 CTGGT
AGGCT,10 TGGTT
GGCTG,11 GGTTG
GCTGG,12 GTTGG
- Trik na znizenie potrebnej pamate (napr. program BLAT): ukladaj iba kazdy s-ty k-mer z prvej sekvencie, potom hladaj vsetky k-mery z druhej
- Trochu znizi aj senzitivitu, ale kedze jadra sa zhlukuju, mame sancu aspon jedno jadro zo zhluku najst
- Zarucene najdeme jadro, ak mame aspon k+s-1 zhod za sebou
- Mohli by sme v query tiež hľadať iba každý s-ty k-mer?
- Čo ak by db a query boli to isté, iba v query ba chýbalo prvé písmeno?
Priklad w=5, s=3, k-mery nalavo sa ulozia, k-mery napravo sa hladaju, najde sa jedno jadro
AGTGGCTGCCAGGCTGG cGaGGCTGCCtGGtTGG
AGTGG,0 CGAGG
GGCTG,3 GAGGC
TGCCA,6 AGGCT
CAGGC,9 GGCTG <-
GCTGG,12 GCTGC
CTGCC
TGCCT
GCCTG
CCTGG
CTGGT
TGGTT
GGTTG
GTTGG
- Prefikanejsia idea je minimizer: uvazuj vsetky skupiny s po sebe iducich k-merov (sliding window), v kazdej skupine najdi abecedne najmensi k-mer (minimizer) a uloz do slovnika
- Pri posune okna o jedno doprava casto najmensi k-mer zostava ten isty a netreba ho znovu ukladat, cim sa usetri pamat (a čas)
- Rozdiel je pri hladani: v slovniku nehladame vsetky k-mery druhej sekvencie, ale tiez len minimizery, co moze usetrit cas
- Zarucene najdeme jadro, ak mame aspon k+s-1 zhod za sebou
- Priklad k=5, s=3, vlavo: do slovnika sa ulozia k-mery s cislom; vpravo: v slovniku sa hladaju k-mery s hviezdickou, najde sa jedna zhoda
AGTGGCTGCCAGGCTGG cGaGGCTGCCtGGtTGG
AGTGG,0 CGAGG
GTGGC GAGGC
TGGCT AGGCT*
GGCTG,3 GGCTG
GCTGC,4 GCTGC
CTGCC,5 CTGCC* <--
TGCCA TGCCT
GCCAG GCCTG
CCAGG,8 CCTGG*
CAGGC,9 CTGGT*
AGGCT,10 TGGTT
GGCTG GGTTG*
GCTGG GTTGG
- Obzvlast vyhodne ak prva a druha mnozina sekvencii su ta ista, napr. pri hladani prekryvov v citaniach pri skladani genomu. Kazde citanie ma mnozinu minimizerov, ktore sa pouziju ako kluce v slovniku, hodnoty su zoznamy citani. Dvojice citani zdielajuce nejaky minimizer (binning) sa dostanu do jedneho zoznamu a budu uvazovane pri vypocte vzajomneho prekryvu
- V praxi sa do slovnika neuklada lexikograficky najmensi k-mer, ale kazdy k-mer sa prehasuje nejakou funkciou f a zoberie sa ten s minimalnou hodnotou
- Dovod je, ze sa chceme vyhnut, aby minimizermi boli casto sekvencie typu AAAAA, ktore su v biologickych sekvenciach nadreprezentovane a casto nie su funkcne zaujimave
- Priemerna hustota minimizerov v sekvencii pri nahodnom hashovani je cca 2/(s+1) (v BLATe bola nizsia, 1/s)
- Minimizery vyuziva napr. aj minimap2, velmi popularny nastroj na zarovnavanie citani navzajom a ku genomom
- na zarovnanie nanoporovych citani ku genomu pouziva k=15, s=10, prekryvy v nanoporovych citaniach k=15, s=5, porovnanie genomov s identitou nad 80% k=19, s=10
- Li, Heng. "Minimap and miniasm: fast mapping and de novo assembly for noisy long sequences." Bioinformatics 32.14 (2016): 2103-2110. [1]
- Roberts M, Hayes W, Hunt BR, Mount SM, Yorke JA. Reducing storage requirements for biological sequence comparison. Bioinformatics. 2004 Dec 12;20(18):3363-9. [2]
- Marçais, G., Pellow, D., Bork, D., Orenstein, Y., Shamir, R., & Kingsford, C. (2017). Improving the performance of minimizers and winnowing schemes. Bioinformatics, 33(14), i110-i117. [3]
MinHash
Odbočka do analýzy web-stránok: Podobnosť textov
Majme množinu webových stránok (webová stránka je postupnosť slov). Chceme nájsť medzi nimi dvojice podobných. Ako môžeme definovať podobnosť dvoch textov?
Jeden zo spôsobov ako to spraviť je pozrieť sa na množstvo slov, spoločných pre jednotlivé dvojice stránok. Očakávame, že čím viac spoločných slov majú, tým sú podobnejšie. Túto mieru podobnosti formalizuje matematický pojem Jaccardovej miery podobnosti.
Nech 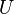 je univerzum slov a nech
je univerzum slov a nech 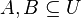 sú jeho podmnožinami (t.j. množiny slov dvoch textov). Potom Jaccardova miera podobnosti
sú jeho podmnožinami (t.j. množiny slov dvoch textov). Potom Jaccardova miera podobnosti 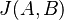 je definovaná nasledovne:
je definovaná nasledovne:
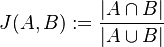
Táto miera nadobúda hodnotu 0 iba v prípade, ak množiny sú disjunktné, a hodnotu 1 iba v prípade, že množiny sú totožné. Inak sa jej hodnota nachádza na otvorenom intervale 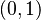 , a čím viac spoločných slov majú, tým je jej hodnota vyššia.
, a čím viac spoločných slov majú, tým je jej hodnota vyššia.
Potom otázku "Ktoré dvojice textov sú podobné?" môžeme preformulovať napríklad ako "Ktoré dvojice textov majú Jaccardovu mieru podobnosti vyššiu ako 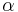 ?", kde
?", kde 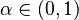 je nejaká prahová hodnota.
je nejaká prahová hodnota.
Exaktný výpočet Jaccardovej miery podobnosti nie je vždy dostatočne rýchly pre účely konkrétnej aplikácie, takže logickým riešením je pokúsiť sa jej hodnotu vypočítať iba približne (t.j. aproximovať).
Prvá idea: aproximácia vzorkovaním
- Ak by sme vedeli vzorkovať z
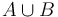 prvky u1, u2, ..., u_s (rovnomerne, nezavisle), a pre kazdy prvok u_i by sme vedeli rychlo zistit, ci patri do prieniku, mohli by sme odhadnut J(A, B) pomocou nahodnej premennej X
prvky u1, u2, ..., u_s (rovnomerne, nezavisle), a pre kazdy prvok u_i by sme vedeli rychlo zistit, ci patri do prieniku, mohli by sme odhadnut J(A, B) pomocou nahodnej premennej X
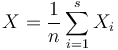 kde X_i=1 ak u_i patri do prieniku a X_i=0 inak
kde X_i=1 ak u_i patri do prieniku a X_i=0 inak
- Toto sa podoba na zistovanie oblubenosti politika prieskumom verejnej mienky, u1, u2, ..., u_s su "respondenti"
Pre kazde X_i
![E(X_{i})=0\cdot Pr[X_{i}=0]+1\cdot Pr[X_{i}=1]=Pr[X_{i}=1]=J(A,B)](/vyuka/mbi/images/math/4/7/b/47bdec1b5fa1ffbbfad85e347715b582.png) .
.
Z linearity strednej hodnoty
![E(X)=E({\frac {1}{n}}\sum _{{i=1}}^{n}X_{i})={\frac {1}{n}}\sum _{{i=1}}^{n}E[X_{i}]=J(A,B)](/vyuka/mbi/images/math/2/4/6/246ca646754ebd6dcf0b9d4bb9eea0b2.png) .
.
Z toho vyplýva, že náhodná premenná 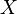 je nevychýleným odhadom Jaccardovej miery.
je nevychýleným odhadom Jaccardovej miery.
V štatistike základnou mierou kvality nevychýleného odhadu je jeho disperzia, odvodenie pozri nižšie
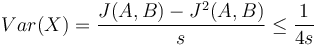
Pri zvyšujúcej veľkosti vzorky s teda klesá disperzia. Podobná situácia ako pri prieskumoch verejnej mierky, kde pri väčšom súbore respondentov dostaneme dôveryhodnejšie výsledky.
Problémy:
- nie je ľahké rovnomerne vzorkovať z
- na zisťovanie, či u_i je v prieniku potrebujeme mat reprezentaciu A a B v pamati, co moze byt problem pri velkej kolekcii dokumentov
- idea: chceme dostat nejake ine premenne X_i, ktore budu nezavisle a ich
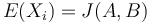 a ktore sa budu lahsie pocitat
a ktore sa budu lahsie pocitat
Aproximácia Jaccardovej miery: MinHash
Budeme mať náhodné hašovacie funkcie 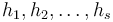 .
.
O každej hašovacej funkcii predpokladáme, že ak ju použijeme na nejakú množinu 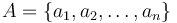 , tak
, tak  .
.
Pre množinu a hašovaciu funkciu h je 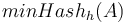 je definovaný nasledovne:
je definovaný nasledovne:
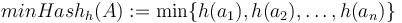
Keďže 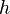 je náhodná hašovacia funkcia, tak sa na hodnotu
je náhodná hašovacia funkcia, tak sa na hodnotu 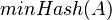 môžeme pozerať ako na náhodnú premennú, ktorá reprezentuje rovnomerne náhodný výber prvku z množiny
môžeme pozerať ako na náhodnú premennú, ktorá reprezentuje rovnomerne náhodný výber prvku z množiny 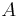 .
.
Nech 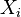 je náhodná premenná, ktorá nadobúda hodnotu 1, ak
je náhodná premenná, ktorá nadobúda hodnotu 1, ak 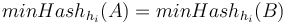 , a inak hodnotu 0. Potom
, a inak hodnotu 0. Potom ![E[X_{i}]=J(A,B)](/vyuka/mbi/images/math/f/a/c/facf28bbce93b2700f294f0e1ee151b4.png) , lebo celkovo máme
, lebo celkovo máme 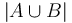 prvkov a
prvkov a 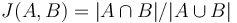 značí, aké percento z nich je v prieniku.
značí, aké percento z nich je v prieniku.
Takýmito hodnotami X_i teda nahradíme náhodné vzorky diskutované vyššie.
Algoritmus:
- Pre kazdy dokument hasuj kazde slovo s funkciami, najdi minHash pre kazdu funkciu a uloz vektor tychto hodnot ako "sketch" dokumentu. Cas vypoctu pre dokument s n slovami je O(ns)
- Pre dva dokumenty porovname vektor po zlozkach a ak najdeme x zhod, J(A,B) odhadneme ako x/s. Cas vypoctu O(s)
- Vieme si tiez pre kazdu hasovaciu funkciu spravit slovnik, ktory mapuje minHash do zoznamu dokumentov a budeme porovnavat iba dvojice dokumentov, ktore sa niekde dostali do toho isteho zoznamu (t.j ich odhad J(A,B) bude nenulovy)
Alternativa: namiesto s roznych funkcii pouzijeme iba jednu a vezmeme nielen minimum, ale s najmensich prvkov. Potom J(A,B) odhadneme pomocou J(s_A, s_B) kde s_A je mnozina hodnot v sketchi mnoziny A. To usetri cas pri vypocte sketchu.
- Broder AZ. On the resemblance and containment of documents. InProceedings. Compression and Complexity of SEQUENCES 1997 (Cat. No. 97TB100171) 1997 Jun 13 (pp. 21-29). IEEE. [4]
Hľadanie podobných sekvencií
Ako "slová" použijeme všetky k-mery danej sekvencie. Potom na hľadanie dvoch podobných čítaní z množiny čítaní môžeme použiť minhash.
- Napriklad Mash pouziva k=21, s=1000 na porovnavanie genomov, sketch ma asi 8kb na genom (genom ma miliony alebo mileardy nukleotidov)
- Ondov BD, Treangen TJ, Melsted P, Mallonee AB, Bergman NH, Koren S, Phillippy AM. Mash: fast genome and metagenome distance estimation using MinHash. Genome biology. 2016 Dec;17(1):1-4. [5]
Vypocet disperzie
Binarna premenna X_i, kde P(X_i=1)=p.
Disperzia 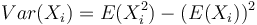 . Spočítajme si postupne obe hodnoty.
. Spočítajme si postupne obe hodnoty.
![E(X_{i}^{2})=0^{2}\cdot Pr[X_{i}=0]+1^{2}\cdot Pr[X_{i}=1]=Pr[X_{i}=1]=p](/vyuka/mbi/images/math/0/6/1/06139f81aa8b2c3c3ea826de354cfae2.png)
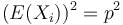
Čiže 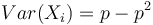 . Aká je maximálna možná hodnota disperzie?
. Aká je maximálna možná hodnota disperzie?
Táto otázka je ekvivalentná otázke "Aké je maximum funkcie 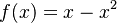 na intervale
na intervale ![[0,1]](/vyuka/mbi/images/math/c/c/f/ccfcd347d0bf65dc77afe01a3306a96b.png) ?". Pre určenie extrémov hladkých funkcií treba nájsť korene jej prvej derivácie. Derivácia tejto funkcie je
?". Pre určenie extrémov hladkých funkcií treba nájsť korene jej prvej derivácie. Derivácia tejto funkcie je 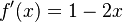 , jej koreň je hodnota
, jej koreň je hodnota 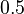 . Hodnota funkcie v tomto bode je rovná
. Hodnota funkcie v tomto bode je rovná 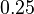 . Čiže
. Čiže 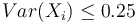 .
.
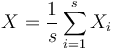 kde X_i su nezavisle premenne a každá z nich má strednú hodnotu
kde X_i su nezavisle premenne a každá z nich má strednú hodnotu 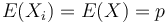 a rovnakú disperziu
a rovnakú disperziu 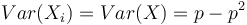 .
T.j. X je ich priemer.
.
T.j. X je ich priemer.
Pozrieme sa na jej varianciu: ![Var(X)=Var\left({\frac {X_{1}+X_{2}+\ldots +X_{s}}{s}}\right)={\dfrac {1}{k^{2}}}Var(X_{1}+X_{2}+\ldots +X_{s}){\overset {*}{=}}{\dfrac {1}{s^{2}}}[Var(X_{1})+\ldots Var(X_{s})]={\dfrac {1}{k^{2}}}s\cdot Var(X_{i})={\dfrac {Var(X_{i})}{s}}\leq {\dfrac {1}{4s}}](/vyuka/mbi/images/math/3/d/4/3d44e538e6e32d2d62f44fca2311ad7f.png)
(*) tento prechod je možný len kvôli tomu, že premenné sú nezávislé.
Vidíme teda, že varianciu (resp. kvalitu) môžeme potlačiť na ľubovoľne malú postupným zvýšením počtu hashov.
Všimnite si, že premenná 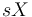 (t.j. nie priemer, ale súčet jednotlivých ) je súčtom nezávislých indikátorov s rovnakou distribúciou, a teda má binomické rozdelenie s parametrami
(t.j. nie priemer, ale súčet jednotlivých ) je súčtom nezávislých indikátorov s rovnakou distribúciou, a teda má binomické rozdelenie s parametrami 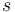 a
a 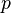 .
.