CI02: Rozdiel medzi revíziami
Z MBI
(→Počítanie pokrytia genómov) |
(→Počítanie pokrytia genómov) |
||
| Riadok 35: | Riadok 35: | ||
==Počítanie pokrytia genómov== | ==Počítanie pokrytia genómov== | ||
| − | * Pozrite | + | * Pozrite tiež grafy k pravdepodobnosti: {{pdf|Ci-coverage}} |
| − | * | + | * Náš problém: spočítanie pokrytia |
| − | ** G = | + | ** G = dĺžka genómu, napr. 1 000 000 (predpokladajme, že je cirkulárny) |
| − | ** N = | + | ** N = počet čítaní (readov), napr. 10 000 |
| − | ** L = dlzka | + | ** L = dlzka čítania, napr. 1000 |
| − | ** | + | ** Celková dĺžka čítaní NL, pokrytie (coverage) NL/G, v nasom pripade 10x |
| − | ** V priemere | + | ** V priemere každá báza pokrytá 10x |
| − | ** | + | ** Niektoré sú ale pokryté viackrát, iné menej. |
| − | ** | + | ** Zaujímajú nás otázky typu: koľko báz očakávame, že bude pokrytých menej ako 3x? |
| − | ** | + | ** Dôležité pri plánovaní experimentov (aké veľké pokrytie potrebujem na dosiahnutie určitej kvality) |
| − | * Pokrytie | + | |
| − | * | + | * Pokrytie genómu: predpokladáme, že každé čítanie začína na náhodnej pozícií zo všetkých možných G |
| + | * Takže ak premenná Y_i bude začiatok i-tého čítania, jej rozdelenie bude rovnomerné | ||
** P(Y_i=1) = P(Y_i=2) = ... = P(Y_i=G) = 1/G | ** P(Y_i=1) = P(Y_i=2) = ... = P(Y_i=G) = 1/G | ||
| − | * | + | * Aká je pravdepodobnosť že nejaké konkrétne i-te čítanie pokrýva konkrétnu pozíciu j? |
| − | ** P(Y_i>=j-L+1 and Y_i<=j) = P(Y_i=j-L+1)+...+P(Y_i=j) = L/G, | + | ** P(Y_i>=j-L+1 and Y_i<=j) = P(Y_i=j-L+1)+...+P(Y_i=j) = L/G, označme túto hodnotu p, v našom príklade p=0.001 (1 promile) |
* Uvazujme premennu X_j, ktora udava pocet čítaní pokryvajucich poziciu j | * Uvazujme premennu X_j, ktora udava pocet čítaní pokryvajucich poziciu j | ||
Verzia zo dňa a času 14:40, 30. september 2022
Úvod do pravdepodobnosti
- Myšlienkový experiment, v ktorom vystupuje náhoda, napr. hod ideálnou kockou/mincou
- Výsledkom experimentu je nejaká hodnota (napr. číslo, alebo aj niekoľko čísel, reťazec)
- Túto neznámu hodnotu budeme volať náhodná premenná
- Zaujíma nás pravdepodobnosť, s akou náhodná premenná nadobúda jednotlivé možné hodnoty
- T.j. ak experiment opakujeme veľa krát, ako často uvidíme nejaký výsledok
Príklad 1: hodíme idealizovanou kockou, premenná X bude hodnota, ktorú dostaneme
- Možné hodnoty 1,2,..,6, každá rovnako pravdepodobná
- Pišeme napr. Pr(X=2)=1/6
Príklad 2: hodíme 2x kockou, náhodná premenná X bude súčet hodnôt, ktoré dostaneme
- Možné hodnoty: 2,3,...,12
- Každá dvojica hodnôt (1,1), (1,2),...,(6,6) na kocke rovnako pravdepodobná, t.j. pravdepodobnosť 1/36
- Súčet 5 môžeme dostať 1+4,2+3,3+2,4+1 - t.j. P(X=5) = 4/36
- Súčet 11 môžeme dostať 5+6 alebo 6+5, t.j. P(X=11) = 2/36
- Rozdelenie pravdepodobnosti: (tabuľka udávajúca pravdepodobnosť pre každú možnú hodnotu)
hodnota i: 2 3 4 5 6 7 8 9 10 11 12 Pr(X=i): 1/36 2/36 3/36 4/36 5/36 6/36 5/36 4/36 3/36 2/36 1/36
- Overte, ze súčet pravdepodobností je 1
Stredná hodnota E(X):
- priemer z možných hodnôt váhovaných ich pravdepodobnosťami
- v našom príklade
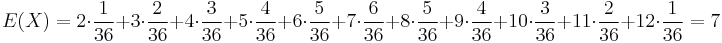
- Ak by sme experiment opakovali veľa krát a zrátali priemer hodnôt X, ktoré nám vyšli, dostali by sme číslo blízke E(X)
- Iný výpočet strednej hodnoty:
- X=X1+X2, kde X1 je hodnota na prvej kocke a X2 je hodnota na druhej kocke
-
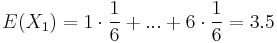 , podobne aj E(X2) = 3.5
, podobne aj E(X2) = 3.5
- Platí, že E(X1+X2)=E(X1) + E(X2) a teda E(X) = 3.5 + 3.5 = 7
- Pozor, pre súčin a iné funkcie takéto vzťahy platiť nemusia, napr.
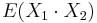 nie je vždy
nie je vždy 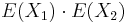
Počítanie pokrytia genómov
- Pozrite tiež grafy k pravdepodobnosti: pdf
- Náš problém: spočítanie pokrytia
- G = dĺžka genómu, napr. 1 000 000 (predpokladajme, že je cirkulárny)
- N = počet čítaní (readov), napr. 10 000
- L = dlzka čítania, napr. 1000
- Celková dĺžka čítaní NL, pokrytie (coverage) NL/G, v nasom pripade 10x
- V priemere každá báza pokrytá 10x
- Niektoré sú ale pokryté viackrát, iné menej.
- Zaujímajú nás otázky typu: koľko báz očakávame, že bude pokrytých menej ako 3x?
- Dôležité pri plánovaní experimentov (aké veľké pokrytie potrebujem na dosiahnutie určitej kvality)
- Pokrytie genómu: predpokladáme, že každé čítanie začína na náhodnej pozícií zo všetkých možných G
- Takže ak premenná Y_i bude začiatok i-tého čítania, jej rozdelenie bude rovnomerné
- P(Y_i=1) = P(Y_i=2) = ... = P(Y_i=G) = 1/G
- Aká je pravdepodobnosť že nejaké konkrétne i-te čítanie pokrýva konkrétnu pozíciu j?
- P(Y_i>=j-L+1 and Y_i<=j) = P(Y_i=j-L+1)+...+P(Y_i=j) = L/G, označme túto hodnotu p, v našom príklade p=0.001 (1 promile)
- Uvazujme premennu X_j, ktora udava pocet čítaní pokryvajucich poziciu j
- mozne hodnoty 0..N
- i-te čítanie pretina poziciu j s pravdepodobnostou p=L/G
- to iste ako keby sme N krat hodili mincou, na ktorej spadne hlava s pravd. p a znak 1-p a oznacili ako X_j pocet hlav
- Priklad: majme mincu, ktora ma hlavu s pr. 1/4 a hodime ju 3x.
HHH 1/64 HHT 3/64 HTH 3/64 HTT 9/64 THH 3/64 THT 9/64 TTH 9/64 TTT 27/64
- P(X_j=3) = 1/64, P(X_j=2)=9/64, P(X_j=1)=27/64, P(X_j=0)=27/64
- taketo rozdelenie pravdepodobnosti sa vola binomicke
- P(X_j = k) = (N choose k) p^k (1-p)^(N-k), kde
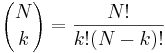 a n! = 1*2*...*n
a n! = 1*2*...*n
- napr pre priklad s troma hodmi kockou P(X_j=2) = 3!/(2!*1!) * (1/4)^2 * (3/4)^1 = 9/64
- Zle sa pocita pre velke N, preto sa niekedy pouziva aproximacia Poissonovym rozdelenim s parametrom lambda = Np, ktore ma
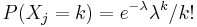
- Spat k sekvenovaniu: vieme spocitat rozdelenie pravdepodobnosti a tiez napr. P(X_i<3) = P(X_i=0)+P(X_i=1)+P(X_i=2) = 0.000045+0.00045+0.0023=0.0028
- Stredna hodnota poctu baz v celom genome s pokrytim k je G*P(X_i=k)
- V priemere teda ocakavame 45 baz nepokrytych, 2800 pokrytých menej ako 3 krát a pod.
- Takyto graf, odhad, vieme lahko spravit pre rozne pocty čítaní a tak naplanovat, kolko čítaní potrebujeme
Chceme tiež odhadnúť počet kontigov (podľa článku E.S. Lander and M.S. Waterman. "Genomic mapping by fingerprinting random clones: a mathematical analysis." Genomics 2.3 (1988): 231-239 [1])
- Ak niekoľko báz vôbec nie je pokrytých čítaniami, preruší sa kontig
- Vieme, koľko báz je v priemere nepokrytých, ale niektoré môžu byť vedľa seba
- Nový kontig vznikne aj ak sa susedné čítania málo prekrývajú
- Predpokladajme, že na spojenie dvoch čítaní potrebujeme prekryv aspoň T=50
- Nech p je pravdepodobnosť, ze dané čítanie i bude posledné v kontigu
- Aby sa to stalo, žiadne čítanie j!=i nesmie začínať v prvých L-T bázach kontigu i
- Každé čítanie tam začína s pravdepodobnosťou q=(L-T)/G
- Ak X je počet čítaní, ktoré zacinaju v tomto useku, tak p = Pr(X=0) = (1-q)^(N-1) podla binomickeho rozdelenia
- v priemere ich tam zacne E(X) = (N-1)(L-T)/G co je zhruba N(L-T)/G
- Jednoduchší vzorec pre p dostaneme ak binomické rozdelenie premennej X aproximujeme Poissonovým s parametrom
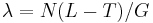 (t.j. aby mali rovnakú strednú hodnotu)
(t.j. aby mali rovnakú strednú hodnotu)
- V Poissonovom rozdelení p = Pr(X=0) = exp(-lambda) = exp(-N(L-T)/G)
- Presnosť aproximácie: pre parametre N,L,G,T uvedené vyššie dostaneme z binomického rozdelenia p=7.459e-5, z Poissonovho 7.485e-5
- Pre N čítaní dostaneme priemerný počet kontigov N*p = N*exp(-N(L-T)/G)
- NL/G je pokrytie, N(L-T)/G je pokrytie, ak by sme dĺžku každého čítania skrátili o dĺžku prekryvu
- Pre T=50 dostaneme priemerný počet koncov kontigov 0.75 (ak pokryjeme celý kruh, máme nula koncov, preto je hodnota menšia ako 1). Ak znížime N na 5000 (5x pokrytie) dostaneme 43 kontigov
- Môže sa zdať zvláštne, ze pri priemernom pocte nepokrytych baz 45 mame pocet koncov v priemere menej ako jedna. Situacia je vsak taka, ze pri opakovaniach tohto experimentu casto dostavame jeden suvisly kontig, ale ak je uz aspon jeden koniec kontigu, byva tam pomerne velka medzera. Tu je napriklad 50 opakovani expertimentu s T=0, priemerny pocet koncov je 0.55, priemerny pocet nepokrytych baz je 49.
nepokr: 0 koncov: 0 nepokr: 0 koncov: 0 nepokr: 0 koncov: 0 nepokr: 274 koncov: 2 nepokr: 282 koncov: 1 nepokr: 0 koncov: 0 nepokr: 0 koncov: 0 nepokr: 0 koncov: 0 nepokr: 8 koncov: 1 nepokr: 0 koncov: 0 nepokr: 12 koncov: 1 nepokr: 0 koncov: 0 nepokr: 122 koncov: 1 nepokr: 135 koncov: 1 nepokr: 111 koncov: 1 nepokr: 13 koncov: 1 nepokr: 1 koncov: 1 nepokr: 56 koncov: 1 nepokr: 265 koncov: 1 nepokr: 0 koncov: 0 nepokr: 10 koncov: 1 nepokr: 0 koncov: 0 nepokr: 0 koncov: 0 nepokr: 130 koncov: 1 nepokr: 217 koncov: 1 nepokr: 3 koncov: 1 nepokr: 0 koncov: 0 nepokr: 0 koncov: 0 nepokr: 0 koncov: 0 nepokr: 86 koncov: 1 nepokr: 139 koncov: 2 nepokr: 0 koncov: 0 nepokr: 0 koncov: 0 nepokr: 76 koncov: 1 nepokr: 221 koncov: 1 nepokr: 26 koncov: 1 nepokr: 0 koncov: 0 nepokr: 1 koncov: 1 nepokr: 0 koncov: 0 nepokr: 0 koncov: 0 nepokr: 0 koncov: 0 nepokr: 0 koncov: 0 nepokr: 0 koncov: 0 nepokr: 0 koncov: 0 nepokr: 12 koncov: 1 nepokr: 103 koncov: 2 nepokr: 0 koncov: 0 nepokr: 71 koncov: 1 nepokr: 69 koncov: 1 nepokr: 0 koncov: 0
- Tento jednoduchy model nepokryva vsetky faktory:
- čítania nemaju rovnaku dlzku
- Problemy v zostavovani kvoli chybam, opakovaniam a pod.
- čítania nie su rozlozene rovnomerne (cloning bias a pod.)
- Vplyv koncov chromozomov pri linearnych chromozomoch
- Uzitocny ako hruby odhad
- Na spresnenie mozeme skusat spravit zlozitejsie modely, alebo simulovat data
- Poznamka: pravdepodobnosti z binomickeho rozdelenia mozeme lahko spocitat napr. statistickym softverom R. Tu su prikazy, ktore sa na to hodia, pre pripad, ze by vas to zaujimalo:
dbinom(10,1e4,0.001); #(12.5% miest ma pokrytie presne 10) pbinom(10,1e4,0.001,lower.tail=TRUE); #(58% miest ma pokrytie najviac 10) dbinom(0:30,1e4,0.001); #tabulka pravdepodobnosti [1] 4.517335e-05 4.521856e-04 2.262965e-03 7.549258e-03 1.888637e-02 [6] 3.779542e-02 6.302390e-02 9.007019e-02 1.126216e-01 1.251601e-01 [11] 1.251726e-01 1.137933e-01 9.481826e-02 7.292252e-02 5.207187e-02 [16] 3.470068e-02 2.167707e-02 1.274356e-02 7.074795e-03 3.720595e-03 [21] 1.858621e-03 8.841718e-04 4.014538e-04 1.743354e-04 7.254524e-05 [26] 2.897743e-05 1.112843e-05 4.115040e-06 1.467156e-06 5.050044e-07 [31] 1.680146e-07
Zhrnutie
- Pravdepobnostny model: myslienkovy experiment, v ktorom vystupuje nahoda, napr. hod idealizovanou kockou
- Vysledok je hodnota, ktoru budeme volat nahodna premenna
- Tabulka, ktora pre kazdu moznu hodnotu nahodnej premennej urci jej pravdepodobnost, sa vola rozdelenie pravdepodobnosti, sucet hodnot v tabulke je 1
- Znacenie typu P(X=7)=0.1
- Priklad: mame genom dlzky G=1mil., nahodne umiestnime N=10000 čítaní dlzky L=1000
- Nahodna premenna X_i je pocet čítaní pokryvajucich urcitu poziciu i
- Podobne, ako keby sme N krat hodili kocku, ktora ma cca 1 promile sancu padnu ako hlava a 99.9% ako znak a pytame sa, kolko krat padne znak (1 promile sme dostali po zaukruhleni z L/(G-L+1))
- Rozdelenie pravdepobnosti sa v tomto pripade vola binomicke a existuje vzorec, ako ho spocitat
- Takyto model nam moze pomoct urcit, kolko čítaní potrebujeme osekvenovat, aby napr. aspon 95% pozicii bolo pokrytych aspon 4 čítaniami