Vybrané partie z dátových štruktúr
2-INF-237, LS 2016/17
Nepovinná DÚ: Rozdiel medzi revíziami
(Vytvorená stránka „Nepovinné domáce úlohy môžete použiť na získanie bodov za aktivitu aj mimo prednášky. V rámci semestra bude ešte aspoň jedna ďalšia séria úloh, ale nes...“) |
(→Séria 1, odovzdať do 14.3.) |
||
| 8 medziľahlých revízií od jedného používateľa nie je zobrazených. | |||
| Riadok 4: | Riadok 4: | ||
a môžete získať ďalších 10 ako bonus. | a môžete získať ďalších 10 ako bonus. | ||
| + | <!-- | ||
Riešenia úloh odovzdajte v písomne forme na prednáške do termínu | Riešenia úloh odovzdajte v písomne forme na prednáške do termínu | ||
| − | odovzdania. Maximálny počet bodov je orientačný, ak sa úloha ukáže | + | odovzdania. --> |
| + | Maximálny počet bodov je orientačný, ak sa úloha ukáže | ||
náročnejšia, než sa očakávalo, môže byť zvýšený. O úlohách sa môžete | náročnejšia, než sa očakávalo, môže byť zvýšený. O úlohách sa môžete | ||
rozprávať, ale nepíšte si z takýchto rozhovorov poznámky a napíšte | rozprávať, ale nepíšte si z takýchto rozhovorov poznámky a napíšte | ||
| Riadok 12: | Riadok 14: | ||
riešenie vlastnými slovami. Všetky odpovede zdôvodnite. | riešenie vlastnými slovami. Všetky odpovede zdôvodnite. | ||
| − | Neskôr v semestri môže byť zverejnená aj ďalšia séria úloh, ale | + | <!-- Neskôr v semestri môže byť zverejnená aj ďalšia séria úloh, ale |
| − | nespoliehajte sa, že tých sérií bude veľmi veľa. | + | nespoliehajte sa, že tých sérií bude veľmi veľa. --> |
| + | |||
| + | ==Séria 2, odovzdať najneskôr deň pred skúškou do 10:00== | ||
| + | |||
| + | Nepovinnú domácu úlohu môžete odovzdať písomne v M163 (ak tam nie som, strčte papier pod dvere) alebo emailom v pdf formáte a môžete za ňu dostať body za aktivitu. Všetky odpovede stručne zdôvodnite. | ||
| + | |||
| + | ===Úloha 1 (2 body)=== | ||
| + | Uvažujme Morissov-Prattov algoritmus pre vzorku P dĺžky m, ktorý bežíme na veľmi dlhom texte T. Koľko najviac bude trvať spracovanie úseku dĺžky k niekde uprostred textu T ako funkcia parametrov m a k? Hodnota k môže byť menšia alebo väčšia ako m. Uveďte asymptotický horný aj dolný odhad, t.j. aj príklad, kde to bude trvať čo najdlhšie (príklad by mal fungovať pre všeobecné m a k, ale môžete si zvoliť T a P a aj ktorý úsek T dĺžky k uvažujete). | ||
| + | |||
| + | ===Úloha 2 (2 body)=== | ||
| + | Máme dané Bloom filtre pre množiny A a B, vytvorené s tou istou sadou hešovacích funkcií (a teda aj s tou istou veľkosťou tabuľky). | ||
| + | * Ako môžeme z týchto dvoch Bloom filtrov zostrojiť Bloom filter pre zjednotenie A a B? Bude taký istý, ako keby sme priamo vkladali prvky zjednotenia do bežného Bloom filtra? | ||
| + | * Ako môžeme z týchto dvoch Bloom filtrov zostrojiť Bloom filter pre prienik A a B? Bude taký istý, ako keby sme priamo vkladali prvky prieniku do bežného Bloom filtra? | ||
| + | |||
| + | ===Úloha 3 (3 body) === | ||
| + | Máme reťazce X a Y rovnakej dĺžky n, ktorých Hammingova vzdialenosť je 1. | ||
| + | * Aká môže byť v najhoršom prípade Hammingova vzdialenosť reťazcov BWT(X$) a BWT(Y$)? Nájdite príklad, kde je táto vzdialenosť čo najväčšia (ako funkcia n). Naopak, snažte sa dokázať aj horný odhad. | ||
| + | * Pomôcka: abeceda môže byť veľká (môže mať aj veľkosť n) | ||
| + | |||
| + | ===Úloha 4 (? bodov, podľa náročnosti)=== | ||
| + | Máme reťazce X a Y rovnakej dĺžky n, ktorých Hammingova vzdialenosť je 1. | ||
| + | * Aká môže byť v najhoršom prípade '''editačná''' vzdialenosť reťazcov BWT(X$) a BWT(Y$)? Nájdite príklad, kde je táto vzdialenosť čo najväčšia (ako funkcia n). Naopak, snažte sa dokázať aj horný odhad. | ||
==Séria 1, odovzdať do 14.3.== | ==Séria 1, odovzdať do 14.3.== | ||
| Riadok 29: | Riadok 52: | ||
vyskytujúci typ bloku dostane ako kód prázdny reťazec, druhé dva | vyskytujúci typ bloku dostane ako kód prázdny reťazec, druhé dva | ||
najčastejšie sa vyskytujúce typy blokov dostanú kódy 0 a 1, ďalšie | najčastejšie sa vyskytujúce typy blokov dostanú kódy 0 a 1, ďalšie | ||
| − | štyri typy dostanú kódy 00, 01, 10 a 11, ďalších 8 | + | štyri typy dostanú kódy 00, 01, 10 a 11, ďalších 8 typov dostane kódy |
dĺžky 3 atď. | dĺžky 3 atď. | ||
| Riadok 38: | Riadok 61: | ||
štruktúra sa asi bude podobať na štruktúru RRR z prednášky, ale | štruktúra sa asi bude podobať na štruktúru RRR z prednášky, ale | ||
popíšte ju tak, aby text bol zrozumiteľný pre čitateľa, ktorý RRR | popíšte ju tak, aby text bol zrozumiteľný pre čitateľa, ktorý RRR | ||
| − | štruktúru nepozná, pozná však štruktúru | + | štruktúru nepozná, pozná však štruktúru pre nekomprimovaný rank. |
| − | + | ||
===Úloha 2 (max 2 body)=== | ===Úloha 2 (max 2 body)=== | ||
| Riadok 55: | Riadok 77: | ||
Ak bonus za ďalšie body sa pokúste navrhnúť schému, v ktorej bude | Ak bonus za ďalšie body sa pokúste navrhnúť schému, v ktorej bude | ||
| − | komprimovaný reťazec | + | komprimovaný reťazec najviac taký dlhý ako B2, ale ktorá búde spĺňať to, žo |
| − | okrem nej potrebujeme len <math>lg t_2 + O(1)</math> prídavnej | + | okrem nej potrebujeme len <math>\lg t_2 + O(1)</math> prídavnej |
informácie pre každý blok na to, aby sme vedeli spätne určiť pôvodný | informácie pre každý blok na to, aby sme vedeli spätne určiť pôvodný | ||
reťazec. | reťazec. | ||
| − | |||
===Úloha 3 (max 4 body)=== | ===Úloha 3 (max 4 body)=== | ||
| Riadok 79: | Riadok 100: | ||
reálne konštanty A,B,C>1. Ak pridávame prvok a v poli už nie je | reálne konštanty A,B,C>1. Ak pridávame prvok a v poli už nie je | ||
miesto, zväčšíme veľkosť poľa z ''s'' na ''A*s''. Naopak, ak zmažeme | miesto, zväčšíme veľkosť poľa z ''s'' na ''A*s''. Naopak, ak zmažeme | ||
| − | prvok a počet prvkov klesne pod ''s/B'', zmenšíme pole na '' | + | prvok a počet prvkov klesne pod ''s/B'', zmenšíme pole na ''s/C''. V |
knihe Cormen, Leiserson, Rivest and Stein Introduction to Algorithms | knihe Cormen, Leiserson, Rivest and Stein Introduction to Algorithms | ||
(kap. 17 v druhom vydaní) nájdete analýzu pre A=2, B=4 a C=2. Nájdite | (kap. 17 v druhom vydaní) nájdete analýzu pre A=2, B=4 a C=2. Nájdite | ||
| − | množinu hodnôt parametrov A,B,C, ktoré pridávanie aj uberanie prvkov | + | množinu hodnôt parametrov A,B,C, pre ktoré pridávanie aj uberanie prvkov |
funguje amortizovane v čase O(1). | funguje amortizovane v čase O(1). | ||
Aktuálna revízia z 21:23, 23. máj 2017
Nepovinné domáce úlohy môžete použiť na získanie bodov za aktivitu aj mimo prednášky. V rámci semestra bude ešte aspoň jedna ďalšia séria úloh, ale nespoliehajte sa na to, že ich ešte bude veľa. Celkovo máte v hodnotení za body za aktivitu 10 bodov a môžete získať ďalších 10 ako bonus.
Maximálny počet bodov je orientačný, ak sa úloha ukáže náročnejšia, než sa očakávalo, môže byť zvýšený. O úlohách sa môžete rozprávať, ale nepíšte si z takýchto rozhovorov poznámky a napíšte text vlastnými slovami. Pri väčšine úloh preferujem vaše vlastné riešenie, ale ak riešenie nájdete v literatúre, uveďte zdroj a napíšte riešenie vlastnými slovami. Všetky odpovede zdôvodnite.
Obsah
Séria 2, odovzdať najneskôr deň pred skúškou do 10:00
Nepovinnú domácu úlohu môžete odovzdať písomne v M163 (ak tam nie som, strčte papier pod dvere) alebo emailom v pdf formáte a môžete za ňu dostať body za aktivitu. Všetky odpovede stručne zdôvodnite.
Úloha 1 (2 body)
Uvažujme Morissov-Prattov algoritmus pre vzorku P dĺžky m, ktorý bežíme na veľmi dlhom texte T. Koľko najviac bude trvať spracovanie úseku dĺžky k niekde uprostred textu T ako funkcia parametrov m a k? Hodnota k môže byť menšia alebo väčšia ako m. Uveďte asymptotický horný aj dolný odhad, t.j. aj príklad, kde to bude trvať čo najdlhšie (príklad by mal fungovať pre všeobecné m a k, ale môžete si zvoliť T a P a aj ktorý úsek T dĺžky k uvažujete).
Úloha 2 (2 body)
Máme dané Bloom filtre pre množiny A a B, vytvorené s tou istou sadou hešovacích funkcií (a teda aj s tou istou veľkosťou tabuľky).
- Ako môžeme z týchto dvoch Bloom filtrov zostrojiť Bloom filter pre zjednotenie A a B? Bude taký istý, ako keby sme priamo vkladali prvky zjednotenia do bežného Bloom filtra?
- Ako môžeme z týchto dvoch Bloom filtrov zostrojiť Bloom filter pre prienik A a B? Bude taký istý, ako keby sme priamo vkladali prvky prieniku do bežného Bloom filtra?
Úloha 3 (3 body)
Máme reťazce X a Y rovnakej dĺžky n, ktorých Hammingova vzdialenosť je 1.
- Aká môže byť v najhoršom prípade Hammingova vzdialenosť reťazcov BWT(X$) a BWT(Y$)? Nájdite príklad, kde je táto vzdialenosť čo najväčšia (ako funkcia n). Naopak, snažte sa dokázať aj horný odhad.
- Pomôcka: abeceda môže byť veľká (môže mať aj veľkosť n)
Úloha 4 (? bodov, podľa náročnosti)
Máme reťazce X a Y rovnakej dĺžky n, ktorých Hammingova vzdialenosť je 1.
- Aká môže byť v najhoršom prípade editačná vzdialenosť reťazcov BWT(X$) a BWT(Y$)? Nájdite príklad, kde je táto vzdialenosť čo najväčšia (ako funkcia n). Naopak, snažte sa dokázať aj horný odhad.
Séria 1, odovzdať do 14.3.
Úloha 1 (max 2 body)
V štruktúre RRR sme rozdelili reťazec na bloky dĺžky t2 a každému sme
v komprimovanom poli B priradili kód, pričom bloky s veľmi málo alebo
veľmi veľa jednotkami mali kratšie kódy ako bloky, v ktorých bol počet
jednotiek a núl probližne rovnaký. Namiesto tohto spôsobu môžeme
použiť nasledovný spôsob kompresie bitového reťazca. Pre každý z
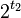 typov bloku spočítame počet výskytov, t.j. koľko
blokov nášho reťazca má tento typ. Potom typy blokov zoradíme podľa
počtu výskytov a pripradíme im kódy tak, že najčastejšie sa
vyskytujúci typ bloku dostane ako kód prázdny reťazec, druhé dva
najčastejšie sa vyskytujúce typy blokov dostanú kódy 0 a 1, ďalšie
štyri typy dostanú kódy 00, 01, 10 a 11, ďalších 8 typov dostane kódy
dĺžky 3 atď.
typov bloku spočítame počet výskytov, t.j. koľko
blokov nášho reťazca má tento typ. Potom typy blokov zoradíme podľa
počtu výskytov a pripradíme im kódy tak, že najčastejšie sa
vyskytujúci typ bloku dostane ako kód prázdny reťazec, druhé dva
najčastejšie sa vyskytujúce typy blokov dostanú kódy 0 a 1, ďalšie
štyri typy dostanú kódy 00, 01, 10 a 11, ďalších 8 typov dostane kódy
dĺžky 3 atď.
Popíšte ako k takto komprimovanému reťazcu zostavíme všetky ďalšie potrebné polia na to, aby sme mohli počítať rank v čase O(1). Veľkosť vašej štruktúry by mala byť m+o(n), kde n je dĺžka pôvodného binárneho reťazca a m dĺžka jeho komprimovanej verzie. Vaša štruktúra sa asi bude podobať na štruktúru RRR z prednášky, ale popíšte ju tak, aby text bol zrozumiteľný pre čitateľa, ktorý RRR štruktúru nepozná, pozná však štruktúru pre nekomprimovaný rank.
Úloha 2 (max 2 body)
Označme B1 komprimovaný reťazec z úlohy 1, t.j zreťazenie kódov pre jednotlivé bloky. Označme B2 komprimovaný reťazec z prednášky o dátovej štruktúre RRR, t.j. zreťazenie odtlačkov (signature) pre jednotlivé bloky. Nájdite príklad, kedy je B2 kratší ako B1 a naopak príklad, pre ktorý je B1 oveľa kratší ako B2.
Poznámka: B1 ani B2 neobsahujú dosť informácie, aby sa z nich samotných dal spätne rekonštruovať pôvodný binárny reťazec, lebo nepoužíme bezprefixový kód. Huffmanovo kódovanie je bezprefixový kód, lebo kód žiadneho znaku nie je prefixom kódu iného znaku.
Ak bonus za ďalšie body sa pokúste navrhnúť schému, v ktorej bude
komprimovaný reťazec najviac taký dlhý ako B2, ale ktorá búde spĺňať to, žo
okrem nej potrebujeme len 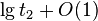 prídavnej
informácie pre každý blok na to, aby sme vedeli spätne určiť pôvodný
reťazec.
prídavnej
informácie pre každý blok na to, aby sme vedeli spätne určiť pôvodný
reťazec.
Úloha 3 (max 4 body)
V prednáške je uvedené bez dôkazu, že ak chceme počítať rank nad
väčšou abecedou, môžeme namiesto wavelet tree použiť RRR štruktúru pre
indikátorové bitové vektory jednotlivých znakov abecedy a že výsledná
štruktúra bude mať veľkosť 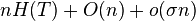 . Dokážte toto tvrdenie. V tejto úlohe ocením aj vami spísaný
dôkaz naštudovaný z literatúry s uvedením zdroja. Ako počiatočný zdroj
môžete použiť prehľadový článok Navarro, Mäkinen (2007) Compressed
full-text
indexes [1]
(strana 30).
. Dokážte toto tvrdenie. V tejto úlohe ocením aj vami spísaný
dôkaz naštudovaný z literatúry s uvedením zdroja. Ako počiatočný zdroj
môžete použiť prehľadový článok Navarro, Mäkinen (2007) Compressed
full-text
indexes [1]
(strana 30).
Úloha 4 (max 3 body)
Uvažujme verziu štruktúry vector, ktorá používa ako parametre tri reálne konštanty A,B,C>1. Ak pridávame prvok a v poli už nie je miesto, zväčšíme veľkosť poľa z s na A*s. Naopak, ak zmažeme prvok a počet prvkov klesne pod s/B, zmenšíme pole na s/C. V knihe Cormen, Leiserson, Rivest and Stein Introduction to Algorithms (kap. 17 v druhom vydaní) nájdete analýzu pre A=2, B=4 a C=2. Nájdite množinu hodnôt parametrov A,B,C, pre ktoré pridávanie aj uberanie prvkov funguje amortizovane v čase O(1).
Nemusíte charakterizovať všetky trojice parametrov, pre ktoré je amortizovaný čas konštantný, ale nájdite nejakú množinu trojíc, pre ktoré je to pravda. Ideálne každému parametru povolíte hodnoty z nejakého intervalu, ktorý môže byť ohraničený konštantami alebo funkciou iných parametrov. Zjavne napríklad musí platiť, že B>C.