Vybrané partie z dátových štruktúr
2-INF-237, LS 2016/17
Dátové štruktúry pre celočíselné kľúče: Rozdiel medzi revíziami
Z VPDS
(→van Emde Boas data structure) |
(→van Emde Boas data structure) |
||
| Riadok 46: | Riadok 46: | ||
* reinterpreted version by Bender and Farach-Colton | * reinterpreted version by Bender and Farach-Colton | ||
* <math>\mathcal{O}(\lg w) = \mathcal{O}(\lg \lg u)</math> time per operation, <math>\Theta (u)</math> space | * <math>\mathcal{O}(\lg w) = \mathcal{O}(\lg \lg u)</math> time per operation, <math>\Theta (u)</math> space | ||
| − | * assuming ''n'' is not not much smaller compared with ''u'', namely if <math>n = u^{Theta(1)}</math>, we get running time <math>O(\log\log n)</math> compared to <math>O(\log n)</math> with balanced binary search trees | + | * assuming ''n'' is not not much smaller compared with ''u'', namely if <math>n = u^{\Theta(1)}</math>, we get running time <math>O(\log\log n)</math> compared to <math>O(\log n)</math> with balanced binary search trees |
| − | * goal is to bound all operations by recurrence <math>T(u) = T(\sqrt{u}) + \mathcal{O}(1)</math>, so running time will be (e.g. by Master theorem applied to <math>log u</math>) <math>T(u) = \mathcal{O}(\lg \lg u)</math> | + | * goal is to bound all operations by recurrence <math>T(u) = T(\sqrt{u}) + \mathcal{O}(1)</math>, so running time will be (e.g. by Master theorem applied to <math>\log u</math>) <math>T(u) = \mathcal{O}(\lg \lg u)</math> |
* main idea is to split universe ''U'' into <math>\sqrt{u}</math> clusters, each of size <math>\sqrt{u}</math> | * main idea is to split universe ''U'' into <math>\sqrt{u}</math> clusters, each of size <math>\sqrt{u}</math> | ||
Verzia zo dňa a času 17:20, 22. jún 2015
Osnova
- van Emde Boas tree, x-fast, y-fast stromy
Obsah
Introduction
- data structures that work only with integers
- can be used to solve predecessor problem
- van Emde Boas data structure, x-fast trees
Models of computations
- for integer data structures
- word - w-bit integer (unsigned)
- words are over universe
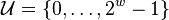 of size
of size 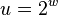
- all input, output, queries, ... are with respect to w-bit words
- memory is an array of words of some fixed size
Word RAM model
- word Random Access Machine
- standard model, it will be used in this lecture
- memory is divided into S cells of size w
- words can serve as pointers
- it is practical to assume
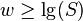 , otherwise we can't index whole memory
, otherwise we can't index whole memory
- if n is the problem size, it implies
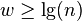
- processor may use in
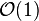 time following 'C-style' operations:
time following 'C-style' operations:
-
![+,-,*,/,\%,\&,|,\gg ,\ll ,<,>,[~]](/vyuka/vpds/images/math/d/8/2/d826bb9c7483a8473ac4d0677a0d5974.png)
Other models
- there exist other models used with (not only) integer data structures
- transdichotomous RAM model
- almost same as word RAM, but it can have perform arbitrary operations that access at most memory cells
- almost same as word RAM, but it can have perform arbitrary operations that access at most
- cell probe model
- reading and writing costs 1, other operations are free
- unrealisitic, used for lower bounds
- pointer machine, etc.
Predecessor problem
- maintain a set S of n words over universe U
- support following operations:
- insert an element of universe into set
- delete an element of set
- find the predecessor of an element from universe in S,
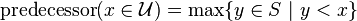
- find the succecessor of an element from universe in S,
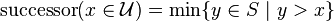
van Emde Boas data structure
- structure to solve predecessor problem
- reinterpreted version by Bender and Farach-Colton
-
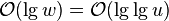 time per operation,
time per operation, 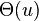 space
space
- assuming n is not not much smaller compared with u, namely if
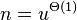 , we get running time
, we get running time 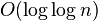 compared to
compared to 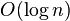 with balanced binary search trees
with balanced binary search trees
- goal is to bound all operations by recurrence
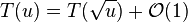 , so running time will be (e.g. by Master theorem applied to
, so running time will be (e.g. by Master theorem applied to 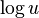 )
) 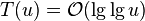
- main idea is to split universe U into
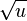 clusters, each of size
clusters, each of size

Hierarchical coordinates
- suppose we have universe of size u
- for word x, we will write
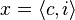 , where:
, where:
-
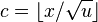 is cluster containing x
is cluster containing x
-
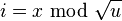 is x's index within cluster
is x's index within cluster
-
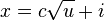
-
- if we have binary numbers:
- just split binary representation of x in half
- c are high order bits,
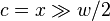
- i are low order bits,
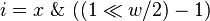
-
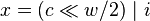
- conversion is in time

VEB recursive structure
- van Emde Boas structure (VEB) V of size u with word size w
- V consists of VEB structures of size and word size
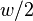 called clusters
called clusters
- each cluster is denoted by V.cluster[c], for
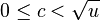
- if is contained in V and x is not the minimum, then i is contained in V.cluster[i]
- in addition, we maintain a summary VEB of size and word size , denoted by V.sumary
- summary contains all integers c such that V.cluster[c] is not empty
- we store minimum element of V separately in V.min (it is not in any cluster) or value None in case V is empty
- we also store copy of maximum element of V in V.max

Operations
Successor
- query for successor of in VEB V
- we first check if x is less then minimum of V, in that case minimum is the successor
- if x is less than maximum in it's own cluster, then the successor of x must be in that cluster (it's either maximum of that cluster or some other element), so we can recursively search for the successor in that cluster
- otherwise, x is greater than any element in it's own cluster, so the answer is minimum in first non empty cluster that goes after cluster c, we can find it by recursive search in summary
- in each of three cases, we call recursion at most once on VEB of square root of size of V, so running time is bounded by recurrence
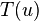
- predecessor query works in very similar fashion
Successor(V, x = <c,i>) {
if (x < V.min) return V.min;
if (i < V.cluster[c].max) {
return <c, Successor(V.cluster[c], i)>;
} else {
c' = Successor(V.summary, c);
return <c', V.cluster[c'].min>;
}
}
Insert
- we want to insert into VEB V
- if minimum is None, it means V is empty and we just set minimum, maximum and return (since minimum is not stored recursively)
- if x is less than minimum, we swap values of x and minimum, so we will insert the old minimum
- if x is greater than maximum, we replace maximum with copy of x
- we check, whether cluster c is empty
- in case it is, we need to insert c into summary
- at last, we insert i into x's cluster c
- note that it can happen that we call recursion twice, but in that case cluster c was empty, so second insert (of i into cluster c) takes constant time, because it just sets minimum and returns
- in any case, we have at most one deep (and at most one shallow) recursion, so running time is still bounded by aforementioned recurrence
Insert(V, x = <c,i>) {
if (V.min == None) {
V.min = V.max = x;
return;
}
if (x < V.min) swap(x, V.min);
if (x > V.max) V.max = x;
if (V.cluster[c].min == None) {
Insert(V.summary, c);
}
Insert(V.cluster[c], i);
}
Delete
- we want to remove from VEB V
- if x is minimum of V, we first check whether the summary is empty
- in case it is, x is the only element of V, so we just remove him and return
- in case there are more elements, new minimum is going to be minimum of first non-empty cluster (since x is the overall minimum and is stored separately), which we can find easily in constant time (we look at minimum of summary and take minimum from that cluster)
- now, we need to delete either minimum of first non-empty cluster (because we moved it into V.min) or x (case where x is not minimum, so it is in some cluster)
- we delete our value recursively from it's cluster
- in case cluster we delete element from is now empty, we need to delete it's number from summary by second recursive call
- note that, same as with insert, in case of second recursive call, cluster in first call had only one element, so it was shallow recursion in constant time and we still have only one deep recursion
- finally, we set min and max values accordingly
Delete(V, x = <c,i>) {
if (x == V.min) {
c = V.summary.min
if (c == None) {
V.min = None;
return;
}
V.min = <c, i = V.cluster[c].min>;
}
Delete(V.cluster[c], i);
if (V.cluster[c].min == None) {
Delete(V.summary, c);
}
if (V.summary.min == None) {
V.max = V.min;
} else {
c' = V.summary.max;
V.max = <c', V.cluster[c'].max>;
}
}
Simple tree view
- original van Emde Boas data structure
- it is similar to previous structure, but from tree point of view
- take a bit vector v of size u, where i-th bit is 1, if integer i is in the structure and 0 otherwise
- next, build full binary tree over vector v, where at each node we store the OR of its children

- note that when we split tree in half of its height, first half represents summary (its leaves are summary bits) and size trees in second half represent clusters
- value of node in tree determine if there is some integer in interval that corresponds to that node
- we will also store for each tree node minimum and maximum integer that is in its interval
Predecessor, successor
- assume we are querying integer x and it is not in the set
- take path from x to root in tree and look at first 1 on that path
- let the last 0 be on node u and first 1 on node v
- if u is left child of v, it means the successor must be in right child's tree and it is minimum of that subtree (since value of v is 1, there must be element in right subtree of v)
- if u is right child of v, we can find predecessor of x as maximum from v's left subtree
- to compute successor from predecessor and vice versa, we can simply store all elements of the structure in sorted linked list
- to find 0-1 transition in x to root path, we use binary search on height
- as value of each node is OR of its children, every element to root path is monotone, path starts as contiguous zeros followed by ones, so we can binary search for 0-1 transition
- in RAM model, we can index directly into path, in other models (e.g. pointer machine), we must store pointers to ancestors to quickly jump in binary search
- in case x is in the set, we just use forward or backward pointer
- time complexity:
- as the binary tree has height w, cost of binary search is
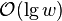 or
or 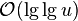
- as the binary tree has height w, cost of binary search is
Updates
- updating this structure is very expensive
- per operation, we must update all nodes of leaf-to-root path, in
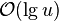 time
time
Sources
- Erik Demain's lecture L11 from MIT: http://courses.csail.mit.edu/6.851/spring12/lectures/
- Wikipedia article about x-fast trees: http://en.wikipedia.org/wiki/X-fast_trie