Programovanie (1) v C/C++
1-INF-127, ZS 2025/26
2021/22 Programovanie (1) v C/C++
Obsah
- 1 Zimný semester
- 2 Zimný semester, úvodné informácie
- 3 Zimný semester, pravidlá
- 4 Zimný semester, semestrálny test
- 5 Zimný semester, skúška
- 6 Zimný semester, softvér
- 7 Valgrind
- 8 Prednáška 1
- 9 Prednáška 2
- 10 Cvičenia 1
- 11 Testovač
- 12 Prednáška 3
- 13 Prednáška 4
- 14 Prednáška 4b
- 15 Prednáška 5
- 15.1 Oznamy
- 15.2 Hľadanie chýb v programe
- 15.3 Záznam typu struct
- 15.4 Spracovanie väčšieho množstva dát
- 15.5 Prvé použitie poľa: podpriemer / nadpriemer
- 15.6 Polia
- 15.7 Výskyty čísel 0...9
- 15.8 Odbočka: grafická knižnica SVGdraw
- 15.9 Kreslíme kruhy
- 15.10 Polia: zhrnutie
- 15.11 Ďalšie príklady na prácu s poľom
- 16 SVGdraw
- 17 Prednáška 6
- 18 Prednáška 7
- 19 Prednáška 8
- 20 Prednáška 9
- 21 Prednáška 10
- 22 Prednáška 11
- 23 Prednáška 12
- 24 Prednáška 13
- 25 Prednáška 14
- 26 Prednáška 15
- 27 Prednáška 16
- 28 Prednáška 17
- 29 Prednáška 18
- 30 Prednáška 19
- 31 Prednáška 20
- 32 Prednáška 21
- 33 Prednáška 22
- 34 Prednáška 23
Zimný semester
- #Zimný semester, úvodné informácie
- #Zimný semester, pravidlá
- #Zimný semester, semestrálny test
- #Zimný semester, skúška
- #Zimný semester, softvér
| Týždeň 20.-26.9. Úvod, premenné, podmienky, výrazy, cyklus for |
| #Prednáška 1 · #Prednáška 2 · #Cvičenia 1 · Softvér · #Testovač |
| Týždeň 27.9-3.10. Ďalšie príklady na cykly, Euklidov algoritmus, cyklus while, funkcie |
| #Prednáška 3 · #Prednáška 4 · Cvičenia 2 |
| Týždeň 4.-10.10. Dokončenie funkcií, teoretické cvičenie, polia, struct |
| #Prednáška 4b · #Prednáška 5 · Grafická knižnica SVGdraw · Cvičenia 3 · |
| Týždeň 11.-17.10. Eratostenovo sito, jednoduché triedenia, binárne vyhľadávanie, zložitosť, znaky, switch |
| #Prednáška 6 · #Prednáška 7 · Cvičenia 4 |
| Týždeň 18.-24.10. Reťazce, úvod do rekurzie |
| #Prednáška 8 · #Prednáška 9 · Cvičenia 5 |
| Týždeň 25.-31.10. Prehľadávanie s návratom, Mergesort, Quicksort |
| #Prednáška 10 · #Prednáška 11 · Cvičenia 6 |
| Týždeň 1.-7.11. Smerníky, dynamické polia |
| #Prednáška 12 · Cvičenia 7 |
| Týždeň 8.-14.11. Práca s dvojrozmernými údajmi, spájaný zoznam, hašovanie |
| #Prednáška 13 · #Prednáška 14 · Cvičenia 8 |
| Týždeň 15.-21.11. Práca s konzolou na spôsob jazyka C, úvod to textových súborov |
| #Prednáška 15 · Cvičenia 9 |
| Týždeň 22.-28.11. Pokračovanie textových súborov, zásobník, rad |
| #Prednáška 16 · #Prednáška 17 · Cvičenia 10 |
| Týždeň 29.11.-5.12. Vyfarbovanie, aritmetické výrazy |
| #Prednáška 18 · #Prednáška 19 · Cvičenia 11 · #Zimný semester, semestrálny test |
| Týždeň 6.-12.12. Aritmetické stromy, binárne stromy vo všeobecnosti, binárne vyhľadávacie stromy, informácie ku skúške |
| #Prednáška 20 · #Prednáška 21 · Cvičenia 12 · #Zimný semester, skúška |
| Týždeň 13.-19.12. Binárne vyhľadávacie stromy, lexikografické stromy, opakovanie, nepreberané črty C a C++ |
| #Prednáška 22 · Cvičenia 13 · #Prednáška 23 |
Zimný semester, úvodné informácie
Základné údaje
Rozvrh
- Prednášky: pondelok 9:50 F1 a streda 9:50 F1
- Hlavné cvičenia: utorok 11:30 I-H6, I-H3
- Doplnkové cvičenia: piatok 11:30 I-H6
Vyučujú
- doc. Mgr. Broňa Brejová, PhD.
- Ing. Dušan Bernát, PhD.
- Mgr. Adrián Goga
- Bc. Veronika Tordová
Konzultácie po dohode e-mailom.
Ak nemáte otázku na konkrétnu osobu, odporúčame vyučujúcich kontaktovať pomocou spoločnej adresy e-mailovej adresy ![]() . Odpovie vám ten z nás, kto má na starosti príslušnú otázku alebo kto má práve čas.
. Odpovie vám ten z nás, kto má na starosti príslušnú otázku alebo kto má práve čas.
Ciele predmetu
- Naučiť sa algoritmicky uvažovať, písať kratšie programy a hľadať v nich chyby, porozumieť existujúcemu kódu
- Oboznámiť sa so základnými programovými a dátovými štruktúrami jazyka C resp. C++, nie je však nutne so všetkými črtami týchto jazykov
- Cykly, podmienky, premenné a ich typy, funkcie a odovzdávanie parametrov, polia, smerníky, reťazce, súbory
- Oboznámiť sa s niektorými základnými algoritmami a dátovými štruktúrami
- Triedenia, spájané zoznamy, hašovacie tabuľky, stromy, aritmetické výrazy, rad a zásobník, rekurzia, prehľadávanie, vyfarbovanie
- Aj štruktúry, ktoré sú hotové v C++ knižniciach, si budeme programovať sami, aby sme videli, čo sa za nimi skrýva
Literatúra
- Predmet sa nebude striktne riadiť žiadnou učebnicou. Prehľad preberaných tém a stručné poznámky nájdete na stránke predmetu, doporučujeme Vám si na prednáškach a cvičeniach robiť vlastné poznámky.
- Pri štúdiu Vám môžu pomôcť knihy o jazykoch C a C++, o programovaní všeobecne a o algoritmoch preberaných na prednáške. Tu je výber z vhodných titulov, ktoré sú k dispozícii na prezenčné štúdium vo fakultnej knižnici:
- Prokop: Algoritmy v jazyku C a C++ praktický pruvodce, Grada 2008, I-INF-P-26
- Sedgewick: Algorithms in C. Parts 1-4 I-INF-S-43/I-IV
- Kochan: Programming in C, 2005 D-INF-K-7a
- Referenčnú príručku k jazyku C++ nájdete napríklad na tejto webstránke: http://cplusplus.com/
- Môže vás zaujímať aj video prednášok z iných škôl v angličtine
Priebeh semestra
- Na prednáškach budeme preberať obsah predmetu. Prednášky budú štyri vyučovacie hodiny do týždňa.
- Hlavné cvičenia budú dve vyučovacie hodiny do týždňa v počítačovej učebni a ich cieľom je aktívne si precvičiť učivo. Hlavnou náplňou cvičenia je riešenie zadaných príkladov. Cvičiaci vám podľa potreby pomôžu a poradia.
- Príklady z hlavných cvičení, ktoré nestihnete vyriešiť, odporúčame dokončiť doma.
- Okrem toho sa každý týždeň konajú doplnkové cvičenia (tiež dve vyučovacie hodiny). Sú silne odporúčané pre študentov, ktorí doteraz programovali málo alebo vôbec, ale radi uvidíme aj tých, ktorým robia problémy niektoré ťažšie časti učiva, napríklad rekurzia alebo smerníky. Na tomto cvičení s pomocou cvičiacich môžete dokončovať príklady z predchádzajúcich cvičení, pýtať sa otázky k učivu, prípadne pracovať na domácej úlohe.
- Domáce úlohy budú cca 3 cez semester. Pracujte na nich samostatne doma, prípadne na doplnkových cvičeniach. Nechajte si na ne dosť času, nezačnite tesne pred termínom.
- Príklady na cvičenia a domáce úlohy navrhujeme tak, aby vám ich riešenie pomohlo precvičiť si učivo, čím sa okrem iného pripravujete aj na záverečnú skúšku. Okrem tohto sú za tieto príklady body do záverečného hodnotenia. Najviac sa naučíte, ak sa vám príklad podarí samostatne vyriešiť, ale ak sa vám to napriek vášmu úsiliu nedarí, neváhajte sa spýtať o pomoc vyučujúcich. Možno s malou radou od nás sa Vám podarí úlohu spraviť.
- Cieľom vyučujúcich tohto predmetu je vás čo najviac naučiť, ale musíte aj vy byť aktívni partneri. Ak vám na prednáške alebo cvičení nie je niečo jasné, spýtajte sa. V prípade problémov odporúčame navštíviť doplnkové cvičenia, alebo si dohodnúť konzultáciu. Môžete nám klásť tiež otázky emailom. Ak sa dostanete do väčších problémov s plnením študijných povinností, poraďte sa s vyučujúcimi alebo s tútorom, ako tieto problémy riešiť.
Epidemiologické opatrenia
- Môže sa stať, že výučba bude presunutá online
- V tom prípade budú prednášky aj cvičenia v systéme MS Teams
- Ak máte príznaky respiračného ochorenia, nechoďte na fakultu, kontaktujte vyučujúcich emailom
- Počas prezenčnej výučby v odôvodnených prípadoch po predchádzajúcej dohode môžeme umožniť účasť cez MS Teams na cvičeniach
- Videá niektorých prednášok z minulého roku sú k dispozícii, takisto poznámky k prednáškam sú na stránke
- Pokyny k použitiu MS Teams nájdete na zvláštnej stránke
Celkové odporúčania
Prichádzajúci študenti v prvom ročníku majú veľmi rôznu úroveň znalosti programovania, v závislosti od toho, koľko sa mu venovali na strednej škole. Preto pre niektorých môže byť tento predmet veľmi ľahký, pre iných veľmi ťažký. Môže sa to zdať nespravodlivé, ale pokročilí študenti už nad programovaním strávili dlhé hodiny a začiatočníci ich bez určitej námahy nedobehnú. Veľmi radi vám však pomôžeme prekonať nástrahy tohto predmetu. Tu sú naše odporúčania podľa toho, aké znalosti už máte na začiatku semestra. Učebnú látku možno zhruba rozdeliť na základné programovacie konštrukty jazyka C resp. C++ a základné algoritmy, ktoré sa budú počas semestra striedať.
| Úroveň znalostí | Náročnosť látky: základy programovania v C | Náročnosť látky: algoritmy, rekurzia | Odporúčanie |
| Programovať viem len málo alebo vôbec | ťažké | ťažké | Dôležité je začať usilovne pracovať už od začiatku semestra. Odporúčame chodiť aj na doplnkové cvičenia, ďalšie príklady riešiť doma. Neváhajte sa nás spýtať, ak vám niečo nie je jasné. |
| Som skúsený programátor, ale neovládam C ani C++ | ľahké | ťažké | Aj keď prvé prednášky sa vám môžu zdať ľahké, sledujte učebnú látku, aby sa nestalo, že ste sa niektorými dôležitými vecami ešte nestretli. Nezabudnite riešiť príklady z cvičení a domáce úlohy. Hlavne ale nezaspite na vavrínoch: už po pár týždňoch začneme preberať algoritmy a rekurziu, čo môžu byť pre vás ťažšie témy. Treba preto zamakať aj na tomto predmete a v prípade, že Vám učivo robí problémy, neváhajte prísť na doplnkové cvičenia. |
| Som skúsený programátor a ovládam C alebo C++ | viem | ťažké | Podobne ako predchádzajúci riadok. Môžete si prípadne skúsiť napísať test pre pokročilých, môže sa vám podariť preskočiť zopár cvičení. |
| Som skúsený programátor a ovládam aj rekurziu a základné algoritmy (napr. z programátorských súťaží alebo rozšírenej výučby programovania na strednej škole) | ľahké/viem | ľahké/viem | Aby ste sa nenudili riešením ľahkých príkladov, odporúčame test pre pokročilých. Aj tak však potrebujte odovzdať domáce úlohy a absolvovať skúšku, prípadne aj semestrálny test. Priebežne sledujte učivo a v prípade nejasností sa pýtajte. |
Zimný semester, pravidlá
Známkovanie
- 25% známky je na základe príkladov z cvičení
- 15% známky je za domáce úlohy
- 20% známky je za semestrálny test, resp. 30% ak nie je potrebná ústna skúška
- 30% známky je za praktickú skúšku
- 10% známky je za ústnu skúšku, ak je potrebná
- Ústna skúška nie je potrebná, ak študent úspešne absolvuje v prezenčnej forme semestrálny test alebo praktickú skúšku (na úspešné absolvovanie testu treba aspoň 50% bodov, na úspešnú praktickú skúšku treba úspešne odovzdať aspoň jeden z dvoch príkladov)
Pozor, body získavané za jednotlivé príklady nezodpovedajú priamo percentám záverečnej známky. Body za každú formu známkovania sa preváhujú tak, aby maximálny získateľný počet zodpovedal váham uvedených vyššie. Úlohy označené ako bonusové sa nerátajú do maximálneho počtu získateľných bodov v danej aktivite.
Stupnica
- Na úspešné absolvovanie predmetu je potrebné splniť všetky nasledovné podmienky:
- Získať aspoň 50% bodov v celkovom hodnotení
- Získať aspoň 50% z písomky
- Ak sa vás týka ústna skúška, získať aspoň 50% z ústnej skúšky
- Na praktickej skúške úspešne odovzdať aspoň jeden z dvoch príkladov
- Ak niektorú z týchto troch podmienok nesplníte, dostávate známku Fx.
- V prípade úspešného absolvovania predmetu získate známku podľa bodov v celkovom hodnotení takto:
- A: 90% a viac, B:80...89%, C: 70...79%, D: 60...69%, E: 50...59%
Príklady z cvičení
- Na hlavnom cvičení bude zverejnených niekoľko príkladov. Príklady odovzdávate do automatického testovača. Ak úspešne prejdú všetkými testami, môžete za ne dostať body (podmienkou však je dodržať aj ďalšie pokyny v zadaní úlohy).
- Jeden príklad, označený ako rozcvička, bude mať termín odovzdania počas hlavného cvičenia, neskôr teda zaňho body nedostanete.
- Ďalšie príklady môžete odovzdávať až do začiatku ďalšieho hlavného cvičenia.
- Na doplnkovom cvičení môže byť zadaná ešte jedna rozcvička za malý počet bonusových bodov.
- Ak chcete získať body za rozcvičku (hlavnú alebo bonusovú), je potrebné byť počas príslušného cvičenia buď fyzicky na cvičení v počítačovej učebni
- Po predchádzajúcej dohode v odôvodnených prípadoch sa môžete zúčastniť aj dištančne
- Nerozcvičkové príklady môžete riešiť v ľubovoľnom čase a na ľubovoľnom mieste (do termínu odovzdania), odporúčame vám však využiť cvičenia, kde vám môžeme poradiť v prípade problémov
- Ak v niektorom týždni nezískate žiadne body z príkladov z cvičení, dostanete za tento týždeň -5 bodov (toto neplatí pre študentov, ktorí sa z vážnych dôvodov ospravedlnia). Nakoľko každé cvičenia predstavujú materiál z dvoch prednášok, nie je rozumné celý týždeň preskočiť.
- Na niektorých prednáškach alebo cvičeniach budú krátke písomky, kde budete riešiť príklady na papieri. Body za tieto príklady sa tiež rátajú do bodov z cvičení.
Domáce úlohy
- Domáce úlohy sa budú tiež odovzdávať na testovači, budú však opravované ručne.
- Plný počet bodov môžu dosť iba programy, ktoré prejdú všetkými testami, čiastočné body však môžete dosť aj za nedokončený program.
- Budeme kontrolovať správnosť celkovej myšlienky, správnosť implementácie, ale body môžete stratiť aj za neprehľadný štýl.
Semestrálny test
- Koncom semestra sa bude konať jeden semestrálny písomný test prezenčnou alebo dištančnou formou.
- Zmena: Termín testu piatok 10.12. 11:30 počas doplnkových cvičení na MS Teams, viď detaily testu
- Opravný test bude cez skúškové.
Praktická skúška
- Na skúške budete riešiť 2 úlohy pri počítači v celkovom trvaní 2 hodiny.
- Na skúške nemôžete používať žiadne pomocné materiály okrem povoleného ťaháku v rozsahu jedného listu formátu A4 s ľubovoľným obsahom na oboch stranách. Nebude k dispozícii ani internet. Budete používať rovnaké programátorské prostredie ako na cvičeniach.
- Na skúške budú úlohy automaticky testované podobne ako domáce úlohy. Aspoň jedna úloha musí správne prejsť cez všetky testy, inak má študent z daného termínu skúšky známku Fx.
- Po skončení skúšky sa koná krátky ústny pohovor s vyučujúcimi, počas ktorého prediskutujeme programy, ktoré ste odovzdali a uzavrieme vašu známku.
- Bližšie informácie o skúške poskytneme koncom semestra.
Neprítomnosť a opravné termíny
- Domáce úlohy a príklady z cvičení je potrebné odovzdať do určeného termínu. Neskoršie odovzdané riešenia nebudú braté do úvahy, ak nezískate výnimočné predĺženie termínu od vyučujúcich.
- Účasť na hlavných cvičeniach veľmi silne odporúčame a v prípade neprítomnosti stratíte body z rozcvičky. Väčšiu časť bodov môžete získať aj riešením príkladov doma.
- Ak zo závažných dôvodov (napr. zdravotných) nemôžete prísť na písomku, skúšku resp. načas odovzdať domácu úlohu či príklady z cvičení, kontaktujte vyučujúcich emailom. Treba tak spraviť čím skôr, nie až spätne cez skúškové.
- Semestrálny test má jeden opravný termín.
- Ak sa zúčastníte opravného termínu, strácate body z predchádzajúceho termínu, aj keby ste na opravnom získali menej bodov.
- Opakovanie skúšky sa riadi študijným poriadkom fakulty. Máte nárok na dva opravné termíny (ale len v rámci termínov, ktoré sme určili).
Opisovanie
- Máte povolené sa so spolužiakmi a ďalšími osobami rozprávať o zadaných domácich úlohách a príkladoch z cvičení a o stratégiách na ich riešenie. Kód, ktorý odovzdáte, musí však byť vaša samostatná práca. Je zakázané ukazovať svoj kód spolužiakom resp. im ho diktovať. Pri diskusii o úlohe nemajte otvorené vaše programy a ani si nerobte detailné poznámky. Odovzdané programy môžu byť kontrolované softvérom na detekciu plagiarizmu.
- Tiež je zakázané opisovať kód z literatúry alebo z internetu (s výnimkou webstránky predmetu). Pri práci môžete používať webstránky s popisom programovacieho jazyka, nesnažte sa však nájsť priamo riešenie zadaného príkladu.
- Počas testov a skúšok môžete používať iba povolené pomôcky a nesmiete komunikovať so žiadnymi osobami okrem vyučujúcich.
- Ak nájdeme prípady opisovania, všetci zúčastnení študenti získajú za príslušnú domácu úlohu 0 bodov (aj študenti, ktorí dali spolužiakom odpísať). Opakované alebo obzvlášť závažné prípady opisovania alebo porušovania pravidiel predmetu budú podstúpené na riešenie disciplinárnej komisii fakulty.
- Za závažné porušenie pravidiel budeme považovať aj akýkoľvek pokus narušiť činnosť testovača riešení.
Osobné stretnutia
- Vyučujúci vás môžu vyzvať emailom, aby ste prišli na stretnutie ohľadom príkladov, ktoré ste riešili a odovzdali mimo času cvičení (domáce úlohy, príklady z cvičení)
- Na tomto stretnutí im vysvetlíte, ako ste príklad riešili
- Stretnutia sa budú konať počas doplnkových cvičení alebo po dohode v inom čase
- Ak na stretnutie neprídete alebo nebudete vedieť svoj program vysvetliť, stratíte zaňho body
Test pre pokročilých
- V prvom týždni semestra sa bude konať nepovinný test pre pokročilých, určený pre študentov, ktorí už ovládajú väčšiu časť učiva. Jeho úspešným absolvovaním si môžu ušetriť časť povinností na predmete.
- Za každých celých získaných 10% z testu získavate 100% bodov z jedných cvičení (bez bonusov). Na tieto uznané cvičenia nemusíte prísť ani príklady riešiť doma. Napr. ak ste získali 59% z testu, dostanete plný počet bodov z prvých 5 bodovaných cvičení po opravení testu. Tieto body nie je možné presúvať na iné termíny cvičení. Ak riešite úlohy z takéhoto uznaného cvičenia, započíta sa vám maximum z bodov, ktoré získate riešením a z bodov, ktoré sú vám uznané.
- Ak získate aspoň 50% z testu pre pokročilých, body z testu vám budú uznané aj ako body zo semestrálnej písomky. Ak však chcete, môžete písomku znovu písať so spolužiakmi.
Nepreberané črty jazykov C a C++
- Z jazykov C a C++ uvidíme len malú časť.
- Preberané črty týchto jazykov je potrebné ovládať, pre vlastnú potrebu si však môžete v literatúre doštudovať aj ďalšie užitočné príkazy, knižnice a konštrukty.
- Ak je v zadaní uvedené, aké prostriedky máte použiť, držte sa týchto pokynov.
- V opačnom prípade môžete použiť aj nepreberané črty. Aby ste sa vyhli problémom pri opravovaní, je vhodné ich doplniť vysvetľujúcim komentárom.
- Vždy používajte len štandardné súčasti jazykov C a C++ , nie špeciálne knižnice. (Výnimkou sú samozrejme knižnice poskytnuté vyučujúcimi).
- Vaše programy by mali fungovať na testovači bez zvláštnych nastavení kompilátora a pod.
Zimný semester, semestrálny test
- Semestrálny test bude v piatok 10.12. 11:30 počas doplnkových cvičení na MS Teams.
- Test bude trvať 90 minút.
- Personalizované zadania nájdete na testovači vo forme pdf a do týchto zadaní budete dopĺňať odpovede, pdf s odpoveďami odovzdáte na testovači.
- Technickú stránku odporúčame vyskúšať na ukážkovom teste, ktorý je zverejnený na testovači. Počíta sa do cvičení 12 s termínom odovzdania utorok 7.12. do 22:00.
- Test bude pokrývať učivo po prednášku 20, vrátane.
- Môžete používať ľubovoľné papierové materiály aj stránku predmetu (poznámky z prednášok), zakázané sú iné webstránky, použitie editorov (okrem zapisovania odpovedí do textového súboru), kompilátorov, programátorských prostredí, komunikovanie s inými osobami.
- Pozor, nebude veľa času hľadať niečo v prednáškach, lepšie je spraviť si prehľadný ťahák
- Z testu je potrebné získať aspoň polovicu bodov. Počas skúškového bude ešte opravný termín (bližšie v pravidlách predmetu).
Pokročilí, ktorí získali na úvodnom teste pre pokročilých 50% bodov, majú body z testu uznané aj ako body zo semestrálneho testu. Ak však chcete, môžete test znovu písať so spolužiakmi. Odovzdaním testu sa vám budú počítať body z tohto testu bez ohľadu na to, či si polepšíte alebo zhoršíte výsledok.
Na semestrálnom teste budú podobné typy príkladov, aké poznáte z teoretických cvičení, napríklad
- doplňte chýbajúce časti funkcie
- zistite, čo funkcia robí (pre daný vstup alebo všeobecne)
Vyskytne sa však aj nový typ príkladov, kde je úlohou napísať, ako bude na nejakom vstupe fungovať algoritmus alebo dátová štruktúra z prednášky. Nižšie sú ukážky takýchto príkladov. Svoje odpovede si môžete skontrolovať na spodku stránky.
Príklady o binárnych vyhľadávacích stromoch a lexikografických stromoch (príklady 7 a 8 nižšie) na riadnom termíne testu nebudú, môžu sa však vyskytnúť na opravnom termíne.
Ukážkové príklady na semestrálny test
- Príklad 1: Prepíšte výraz 8 3 4 * + 2 3 + / z postfixovej notácie do bežnej infixovej notácie. Aká je jeho hodnota? Nakreslite ho aj ako strom.
- Príklad 2: Prepíšte výraz ((2+4)/(3*5))/(1-2) do postfixovej a prefixovej notácie.
- Príklad 3: Vyhodnocujeme výraz 8 3 4 * + 2 3 - / v postfixovej notácii algoritmom z prednášky. Aký bude obsah zásobníka v čase, keď začneme spracovávať znamienko +?
- Príklad 4: Máme zásobník s a rad q, pričom obidve štruktúry uchovávajú dáta typu char. Aký bude ich obsah po nasledujúcej postupnosti príkazov?
init(s); init(q); push(s, 'A'); push(s, 'B'); push(s, 'C'); enqueue(q, pop(s)); enqueue(q, pop(s)); push(s, 'D'); push(s, dequeue(q));
- Príklad 5: Strom nižšie má v každom uzle uložené jedno písmeno (dáta typu char). V akom poradí budú vypísané jednotlivé písmená, ak použijeme inorder, preorder a postorder prehľadávanie?
A
/ \
/ \
B C
/ \ / \
D E F G
/ \
H I
- Príklad 6: Máme binárny strom, v ktorom má každý vrchol buď dve deti a v dátovom poli uložený znak '#' alebo nemá žiadne deti a v dátovom poli má uložený znak '*'. Keď tento strom vypíšeme v preorder poradí, dostaneme postupnosť ##*#*** Nakreslite, ako vyzerá tento strom.
- Príklad 7: Nakreslite binárny vyhľadávací strom, ktorý dostaneme, ak do prázdneho stromu postupne vkladáme záznamy s kľúčami 3, 4, 1, 2, 5, 6 (v tomto poradí).
- Príklad 8: Nakreslite lexikografický strom s abecedou {a,b}, do ktorého sme vložili reťazce aba, aaab, baa, bab, ba. Vrcholy, ktoré zodpovedajú niektorému reťazcu zo vstupu, zvýraznite dvojitým krúžkom.
- Príklad 9 Ako bude vyzerať hešovacia tabuľka pri riešení kolízií pomocou spájaných zoznamov, ak hešovacia funkcia je |k| mod 5 a vkladáme prvky 13, -2, 0, 8, 10, 17?
Vzorové riešenia ukážkových príkladov na semestrálny test
- Príklad 1: (8+3*4)/(2+3), hodnota 4, strom:
/
/ \
/ \
+ +
/ \ / \
8 * 2 3
/ \
3 4
- Príklad 2: postfix 2 4 + 3 5 * / 1 2 - / prefix: / / + 2 4 * 3 5 - 1 2
- Príklad 3: na zásobníku budú čísla 8 a 12 (8 je na spodku zásobníka). Číslo 12 vzniklo vynásobením 3 a 4.
- Príklad 4: na zásobníku budú znaky A, D, C (A na spodku zásobníka), v rade bude písmeno B
- Príklad 5:
Preorder: ABDEHICFD Postorder: DHIEBFGCA Inorder: DBHEIAFCG
- Príklad 6:
#
/ \
# *
/\
* #
/\
* *
- Príklad 7:
3
/ \
1 4
\ \
2 5
\
6
- Príklad 8: (namiesto dvojitého krúžku používame *)
.
/ \
/ \
/ \
a b
/ \ /
a b a*
/ / / \
a a* a* b*
/
b*
- Príklad 9:
Pre každý index tabuľky 0,..,4 uvádzame zoznam prvkov, ktoré sa do neho zahešujú. Tieto budú pospájané v zozname v uvedenom poradí.
0: 10, 0 1: 2: 17, -2 3: 8, 13 4:
Zimný semester, skúška
Odporúčame tiež si preštudovať pravidlá predmetu.
Termíny, prihlasovanie
Boli zverejnené predbežné termíny skúšok
- Piatok 17.12.2021 12:00, ústne skúšky od 15:00 (predtermín s limitom 20 študentov, koná sa len pri dostatočnom záujme).
- Piatok 14.1.2022 9:00, ústne skúšky od 13:00 (riadny termín).
- Piatok 21.1.2022 9:00, ústne skúšky od 13:00 (hlavne prvý opravný termín).
- Piatok 4.2.2022 9:00, ústne skúšky od 13:00 (hlavne 2. opravný termín).
Ak zistíte konflikt našej skúšky s hromadnou skúškou alebo písomkou iného predmetu, dajte nám vedieť čím skôr, pokiaľ možno do piatka 10.12. Na poslednú chvíľu už nedokážeme nájsť riešenie. Hlavná časť skúšky je spravidla doobeda, ale poobede sa konajú krátke ústne skúšky, takže pokiaľ možno si na poobedie skúškového termínu nič dôležité neplánujte.
Prihlasovanie
- Prihlasovanie je v AIS2/Votr otvorené od pondelka 13.12. 19:00.
- Na termín sa prihlasujte / odhlasujte najneskôr 24 hodín pred začiatkom termínu.
- Predtermín 17.12. má obmedzenú kapacitu, hláste sa čím skôr, prihlasovanie od štvrtka 9.12. 19:00.
- Opravnú písomku môžete na tomto predmete písať aj po skúške.
- Celkovo budú iba uvedené štyri termíny. Každý sa môže zúčastniť na najviac troch z nich.
Špeciálne pravidlá pre predtermín
- Ak sa zúčastňujete predtermínu, body za tréningové príklady môžete dostať iba ak ich vyriešite do 17.12. 11:30 (toto neplatí, ak po predtermíne ešte idete na opravný termín skúšky).
Praktická skúška
- 2 hodiny práca pri počítači, online alebo v halách H3, H6, podľa aktuálnych opatrení
- Za určitých okolností môže byť čas predĺžený o 30 minút, viď pravidlá nižšie
- Počas skúšky vám nebudeme pomáhať hľadať chyby vo vašom programe. Môžete sa však spýtať na nejasnosti v zadaní. Dajte nám tiež vedieť v prípade technických problémov alebo ak si myslíte, že v zadaní / kostre / vstupoch je chyba.
Ďalšie detaily
- Nebudeme používať SVGdraw
- Môžete používať aj črty C/C++, ktoré sme nebrali. Používajte len štandardné súčasti jazyka. Vaše programy by mali fungovať na testovači bez zvláštnych nastavení kompilátora a pod.
- Odporúčame používať iba tie časti jazyka, s ktorými máte dostatočné skúsenosti. Príkazy, ktoré si nepamätáte, si napíšte na "ťahák".
Pravidlá pre skúšku online
- Počas skúšky máte byť pripojení cez MS Teams pre prípad oznamov, mikrofón a kameru nechajte vypnuté.
- Ak máte otázku, zdvihnite ruku, podobne ako cez cvičenia, spojíme sa s vami súkromným hovorom
- Počas skúšky vás môžeme kontaktovať súkromným hovorom, počas ktorého máte zapnúť kameru, na požiadanie zdieľať obrazovku a ukázať nám, aké programy pri práci používate.
Povolené pomôcky
- Papier a písacie potreby (ak máte tlačiareň, môžete si aj vytlačiť zadanie)
- Ľubovoľné papierové materiály (poznámky, knihy)
- Stránka predmetu (poznámky z prednášok)
- Testovač na sťahovanie zadaní a poskytnutých súborov, odovzdávanie riešení
- MS Teams na komunikáciu s vyučujúcimi
- Bežné programátorské prostredie na vašom počítači: editory (napr. Kate), kompilátory (napr. gcc), debuggery, valgrind/Dr.Memory, integrované nástroje ako Netbeans, Eclipse, Code::Blocks, CLion, Dev-C++, Microsoft Visual Studio a pod.
Zakázané pomôcky
- Iné webstránky okrem vyššie uvedených
- Komunikovanie s inými osobami než vyučujúcimi
- Zdieľanie svojho kódu s inými osobami (ručne alebo prostredníctvom funkcií programátorského prostredia)
- Webové programátorské prostredia
Odovzdávanie riešenia
- Počas skúšky máte povinnosť každých cca 15 minút odovzdať na testovač program, na ktorom práve pracujete, aj keď ešte nie je hotový
- Bude to prebiehať tak, že vždy po 15 minútach vás upozorníme cez MS Teams. Ak ste počas posledných 5 minút pred upozornením program odovzdali, nemusíte robiť nič. Ak nie, mali by ste program odovzdať v najbližších 5 minútach.
- Ak práve nemáte rozpísaný program (čítate zadanie / rozmýšľate), napíšte niečo typu "rozmyslam" do okienka na odovzdanie programu a odošlite.
Pravidlá pre skúšku v hale
- Skúška bude v Linuxe, rovnaké prostredie ako na cvičeniach
- Odovzdávanie prostredníctvom špeciálnej verzie testovača
- Okrem testovača nebude k dispozícii internet
- Bude k dispozícii kópia poznámok z predmetu, ktoré vidíte na tejto stránke
- Budete používať špeciálne skúškové konto, takže nebudete mať k dispozícii žiadne svoje súbory alebo nastavenia
- Pri reštarte počítača sa stratia všetky súbory, používajte testovač ako zálohu (odovzdajte aj nedokončený program)
- Môžete použiť Kate, valgrind, Netbeans, ale aj iné nástroje, ktoré bežia v Linuxe v učebniach a nepotrebujú internet. Prípadné problémy s použitím iného softvéru vám však nebudeme pomáhať riešiť
- Môžete si priniesť a používať ľubovoľné papierové materiály, nesmiete ich však počas skúšky zdieľať so spolužiakmi. Môže sa hodiť aj pero na poznámky.
Príklady
Na skúške budete riešiť dva príklady za rovnaký počet bodov
Prvý príklad
- V prvom príklade budete mať za úlohu samostatne napísať celý program, ktorý rieši zadanú úlohu. Typicky bude treba načítať dáta, spracovať ich a vypísať výsledok.
- V tomto príklade môžete použiť ľubovoľný postup.
- Budú však zakázané polia pevných veľkostí. Polia alokujte dynamicky cez new, alebo použite štruktúry, ktoré menia veľkosť podľa potreby (napr. string, vector). Alokovanú pamäť odalokujte.
- Predtým ako začnete programovať, si poriadne rozmyslite, aké dátové štruktúry (polia, matice, struct-y a pod.) chcete v programe použiť.
Druhý príklad
- V druhom príklade dostanete kostru programu, pričom vašou úlohou bude doprogramovať niektoré funkcie.
- V tomto príklade môžete mať v zadaní predpísaný spôsob, ako máte niektoré časti naprogramovať.
- Budú sa vyžadovať aj zložitejšie časti učiva, ako napríklad zoznamy, stromy a rekurzia.
Ukážkové príklady
Niektoré ukážkové príklady na skúšku budú k dispozícii na testovači, môžete si ich v rámci tréningu vyriešiť a odovzdať. Pre realistickejší tréning si vždy prečítajte zadanie tesne predtým, ako príklad začnete riešiť, aby ste odhadli, koľko času vám príklad zaberie vrátane čítania zadania a rozmýšľania nad riešením.
Hodnotenie
Aby ste mali šancu úspešne ukončiť predmet, aspoň jeden z príkladov vám musí prejsť všetky testy na testovači
- Túto podmienku nebudeme považovať za splnenú, ak váš program nerieši zadanú úlohu (t.j. jeho myšlienka nie je v zásade správna)
- Podmienku však považujeme za splnenú, ak váš program prejde všetky vstupy, má v zásade správnu myšlienku, ale nedostane plný počet bodov napríklad kvôli chýbajúcemu uvoľneniu pamäte, statickým poliam, menšej chybe, ktorá sa neprejavila na daných vstupoch a pod.
- Dobre si rozmyslite, s ktorým príkladom chcete začať a snažte sa ho dokončiť, kým nedostanete OK na testovači. Potom ho môžete ešte vylepšovať alebo sa snažiť vyriešiť aspoň časť príkladu, ktorý ste ešte neriešili.
Bodové hodnotenie
- V prvom rade budeme hodnotiť správnosť myšlienky vášho programu. Predtým, ako začnete programovať, si dobre prečítajte zadanie a rozmyslite, ako budete úlohu riešiť.
- Ďalej je veľmi dôležité, aby sa program dal skompilovať (v štandardnom prostredí) a aby správne fungoval na všetkých vstupoch spĺňajúcich podmienky v zadaní.
- V druhej úlohe budeme jednotlivé funkcie hodnotiť zvlášť, takže môžete získať čiastočné body, ak ste niekoľko funkcií napísali správne.
- Na hodnotenie môže mať menší vplyv aj úprava a štýl programu (komentáre, mená premenných, odsadzovanie, členenie dlhšieho programu na funkcie,...)
- Na tejto skúške nezáleží na rýchlosti vášho programu (pokiaľ zbehne v časovom limite, ktorý však nie je prísny). Radšej napíšte jednoduchý, prehľadný a hlavne správny pomalší program, než rýchlejší, ale zbytočne zložitý, či nesprávny.
Predĺženie času
- Ak v riadnom čase 2 hodiny nemáte na testovači OK ani z jedného príkladu, zo skúšky by ste mali dostať Fx.
- Dovolíme vám však predĺžiť čas skúšky o najviac 30 minút.
- Ak zostanete na predĺženie, budeme vám rátať do výsledku body iba z jedného príkladu. Konkrétne z toho, za ktorý ste dostali OK na testovači (ak z oboch, tak z toho, za ktorý ste mali OK skôr)
Ústna skúška
- Po skúške vyučujúci skontrolujú vaše programy a potom sa konajú ústne skúšky cez MS Teams
- Na ústnu skúšku môžu ísť iba študenti, ktorí úspešne absolvovali praktickú skúšku aj písomku a majú po ústnej skúške šancu získať známku.
- Ak je praktická skúška doobeda, ústne skúšky budú cca 13:00-19:00. Na tento čas si teda neplánujte iné dôležité termíny. Ak máte v rámci tohto času nejaké vážne prekážky k absolvovaniu ústnej skúšky, upovedomte o tom vyučujúcich vopred pred skúškou.
- Vyučujúci po skúške zverejnia približný rozpis časov ústnych skúšok. V čase uvedenom v rozpise by ste mali byť pripojení na MS Teams, budeme vás kontaktovať súkromným hovorom. Sledujte oznamy na MS Teams, kde zverejníme prípadné zmeny rozpisu, ktoré si vyžiada situácia.
- Ak by nebolo možné všetkých študentov vyskúšať ústne v deň skúšky, s niektorými si dohodneme termín na iný deň.
- Ústna skúška nie je potrebná, ak študent úspešne absolvuje v prezenčnej forme test pre pokročilých (aspoň 50% bodov), semestrálny test alebo praktickú skúšku. Týmto študentom sa semestrálny test započíta s vyššou váhou.
Obsah ústnej skúšky
- Prejdeme cez bodovanie vášho programu a prípadné komentáre
- Budeme sa pýtať otázky k vašim odovzdaným programom zo skúšky. Otázky môžu byť napríklad:
- Vysvetlite niektorú konkrétnu časť vášho kódu
- Navrhnite, ako by ste kód zmenili alebo rozšírili, aby sa správanie programu zmenilo predpísaným spôsobom
- Popíšte, čo by spôsobila určitá konkrétna zmena v programe
- Okrem programov zo skúšky môžeme podobne diskutovať aj o programoch, ktoré ste odovzdali na cvičeniach 8 až 12.
- Počas ústnej skúšky budeme pokiaľ možno zdieľať diskutovaný kód v okne viditeľnom všetkým zúčastneným stranám
- Jedným z cieľov ústnej skúšky je preveriť, či dobre rozumiete učivu a programom, ktoré ste v rámci predmetu odovzdali a či je teda pravdepodobné, že sú vašou vlastnou prácou. Ak vaše odpovede nebudú uspokojivé, neudelíme vám z ústnej skúšky polovicu bodov a teda nemôžete predmet úspešne ukončiť.
Opravné termíny
- Opakovanie praktickej aj ústnej skúšky sa riadi študijným poriadkom fakulty. Máte nárok na dva opravné termíny (ale len v rámci termínov, ktoré sme určili).
- Ak po skúške máte nárok na známku E alebo lepšiu, ale chceli by ste si známku ešte opraviť, musíte sa dohodnúť so skúšajúcimi.
- Ak sa zo závažných dôvodov (napr. zdravotných, alebo konflikt s inou skúškou) nemôžete zúčastniť termínu skúšky alebo písomky, dajte o tom vyučujúcim vedieť čím skôr.
Zimný semester, softvér
V tomto dokumente popisujeme niektoré nástroje, ktoré môžete použiť na programovanie v tomto semestri. Na cvičeniach a skúške odporúčame používať editor Kate popísaný nižšie.
Môžete používať aj iné nástroje, ale
- k iným prostrediam vám nemusíme vedieť poradiť, ako ich používať
- na skúške budete môcť používať iba tie programy, ktoré sú k dispozícii v učebniach na fakulte v Linuxe, pričom nebude k dispozícii internet
Prenášanie programov a odovzdávanie domácich úloh
- Pri odovzdávaní domácich úloh odovzdávajte súbor .cpp s vašim programom (prípadne ďalšie súbory, ak to vyžaduje zadanie).
- Ak pracujete na rôznych počítačoch v rámci FMFI učební, svoje projekty si ukladajte na sieťovom disku net
- Dáta zo sieťového disku si môžete stiahnuť v učebni na USB kľúčik, alebo aj cez sieť z domu prihlásením sa na študentský Linuxový klaster daVinci (davinci.fmph.uniba.sk). Na prenos dát môžete použiť napríklad windowsovský program winscp
- Odovzdané programy si môžete počas semestra stiahnuť z testovača, po začiatku ďalšieho semestra k ním stratíte prístup
Kate
Kate je základný textový editor, ponúka však dostatok nastavení, aby sa s v ňom pohodlne písali jednoduché programy (nie je však úplne vhodný na väčšie projekty).
Ako spustiť Kate v učebni
- Prihláste sa do Linuxu rovnakým menom a heslom, aké používate v AISe
- V menu s ponukou programov nájdite Kate (v časti Utilities), alebo stlačte ALT+F2 a napíšte kate
- Odporúčame sedieť vždy pri tom istom počítači, máte uložené nastavenia
Vytvorenie nového programu
- File -> New (Ctrl+N) vytvorí nový textový súbor
- Uložte ho pomocou File -> Save (Ctrl+S), bude od vás žiadať nejaké meno a môžete si zvoliť kam bude daný súbor umiestnený. Nazvať si ho môžeme napr. program.cpp
- Dôležité je pridať koncovku .cpp , vďaka nej Kate vie, že chcete programovať v C++ a mal by vám automaticky zapnúť C++ zvýrazňovanie (ktoré je veľmi praktické)
Nastavenia editora
Na programovanie odporúčame spraviť / skontrolovať nasledujúce nastavenia (keď máte otvorený .cpp súbor)
- automatické zvýrazňovanie Tools -> Highlighting -> Sources, malo by byť zaškrtnuté C++
- automatické C++ odsádzanie Tools -> Indentation malo by byť zaškrtnuté C Style
- zobrazovanie terminálu
- Settings -> Configure Kate -> Plugins a tam zaškrtnite Plugin s terminálom
- View -> Tool Views a zaškrtnite Show Terminal
- Tools -> Synchronize Terminal with Current Document
- Tools -> align vám preformátuje vybranú časť programu
Kompilovanie a spustenie programu
- Kate nemá vstavané kompilovanie ani spúšťanie (keďže je to textový editor), preto na to treba používať terminál (textové príkazy)
- v Kate viete mať priamo otvorenú lištu s terminálom, čo je veľmi praktické, mala by sa nachádzať dole pod textovým oknom (prípade kliknite na malú ikonku Terminal)
- Kliknite do okna s terminálom, aby sa stalo aktívnym
- v termináli sa treba dostať do priečinku s vaším súborom
- buď sa to stane automaticky vďaka nastaveniu Tools -> Synchronize Terminal with Current Document
- alebo použite príkazy nižšie
- Ak sa nachádzate v priečinku, v ktorom sa nachádza váš .cpp program, môžete ho pomocou konzoly kompilovať a spúšťať
- Príkaz make meno_suboru_bez_koncovky - napíšeme meno súboru, ale bez koncovky, v tom istom priečinku sa vytvorí súbor meno_suboru_bez_koncovky, čo bude spustiteľný program (linuxový ekvivalent .exe)
- Príkaz g++ program.cpp -o program - vytvorí to isté ako príkaz pred tým, akurát vieme nastavovať parametre kompilátora g++
- Príkaz ./spustitelny_subor - spustí daný program v priečinku, ak mal niečo vypísať, vypíše to do konzoly, ak mal niečo čítať, načítava to tiež z konzoly (ak nie je povedané inak)
Ďalšia práca s teminálom
- V termináli by ste mali vidieť svoje meno, nejaké ďalšie veci a potom :~$ za ktorým kliká kurzor
- časť za : vám hovorí, v ktorom priečinku sa nachádzate, ~ je domový priečinok
- príkaz ls vypíše zoznam súborov a priečinkov v priečinku, v ktorom ste (skratka z list)
- príkaz cd meno_priečinka - presunie sa do priečinka s daným menom, ak sa taký priečinok nachádza v aktuálnom priečinku (skratka z change directory)
- príkaz cd .. - posuniete sa o jeden priečinok vyššie
- ak budete pri písaní mena priečinka/súboru stláčať Tabulátor, bude sa vám to snažiť automaticky doplniť hľadaný súbor, ak je možností viac, doplní čo najviac znakov, ktoré sú rovnaké
- šípkou hore a dole listujete v histórii príkazov a stlačením Enter ho môžete spustiť znovu
Práca v Kate s grafickou knižnicou SVGdraw
- Knižnicu začneme používať od piatej prednášky
- Stiahnite si knižnicu
- Stiahnuté súbory SVDdraw.cpp a SVGdraw.h si uložte do priečinku, v ktorom máte svoje programy
- do vlastného programu potom musíte na začiatok pridať riadok #include "SVGdraw.h"
Kompilácia s grafickou knižnicou SVGdraw
- kompilátor potrebuje vedieť, že váš program chce používať funkcie z iného súboru (SVGdraw.cpp) a preto mu musíte povedať, aby ich nalinkoval. Obyčajný make fungovať nebude
- použite príkaz g++ program.cpp SVGdraw.cpp -o program
- vytvorí sa vám súbor program, ktorý môžete normálne spustiť pomocou ./program
- v priečinku s programom sa vytvorí súbor s príponou .svg, ktorý si môžete pozrieť napr. v internetových prehliadačoch firefox alebo chromium
Iné programátorské prostredia
Okrem jednoduchých editorov ako Kate existujú aj zložitejšie prostredia, ktoré podporujú prácu programátora, najmä na väčších projektoch. Zvyknú sa nazývať IDE (integrated development environment). Výhodu je napríklad zabudovaný debugger, ktorý umožňuje krokovať program pri hľadaní chýb.
Viacplatformové prostredia
Nasledovné prostredia by mali fungovať na Linuxových aj Windowsových počítačoch, aj keď nie vždy je ľahké ich nainštalovať a môžu byť tiež pomerne pomalé
- Netbeans
- Eclipse
- Code::Blocks
- CLion, komerčný softvér so študentskou licenciou zadarmo
- Visual Studio Code od firmy Microsoft
Z nich v učebniach v Linuxe fungujú Code::Blocks, Netbeans, Eclipse
- Tieto prostredia teda môžete použiť aj na skúške
- Návod na použitie prostredia Netbeans z minulých semestrov nájdete tu
Windows
Pod Windows existuje pomerne veľké množstvo programátorských prostredí podporujúcich C/C++. Možnosti sú napríklad nasledovné:
1. Kompilátor GCC + textový editor
- Ide o najjednoduchšiu možnosť podobnú práci s Kate pod Linuxom.
- GCC je pôvodom Linuxový kompilátor pre C/C++. Existuje však aj verzia pre Windows, ktorá je súčasťou prostredia MinGW.
- Programy možno písať v ľubovoľnom textovom editore, ideálne však v takom, ktorý podporuje zvýrazňovanie syntaxe pre C a C++, napríklad Notepad++, PSPad a mnohé ďalšie.
- Programy potom kompilujeme z príkazového riadku: napríklad súbor program.cpp skompilujeme tak, že sa v príkazovom riadku nastavíme do adresára, ktorý ho obsahuje a následne zadáme príkaz ako
g++ -o program program.cpp
Tým sa vytvorí spustiteľný súbor program.exe, ktorý možno spustiť z príkazového riadku príkazom program.
- Viaceré textové editory podporujú aj integráciu s príkazovým riadkom, takže kompilovanie a spúštanie programov možno realizovať priamo z nich.
Inštalácia MinGW:
- Stiahnite si inštálator zo stránky projektu.
- Zapamätajte si adresár na disku, do ktorého MinGW inštalujete.
- Spustite inštaláciu, počas ktorej zvoľte obidva jazyky C a C++.
- Po ukončení inštalácie pridajte cestu do adresára obsahujúceho spustiteľné súbory gcc.exe a g++.exe (typicky <cesta do koreňového adresára MinGW>\bin) do systémovej premennej PATH, aby bolo možné g++ v príkazovom riadku volať z ľubovoľného adresára. Na internete je dostupných množstvo návodov na editovanie systémových premenných (kľúčové slová pre vyhľadávanie môžu byť napríklad edit PATH environment variable v kombinácii s vašou verziou Windows).
2. NetBeans
- NetBeans je IDE určené najmä pre jazyk Java. Možno v ňom však vyvíjať aj aplikácie pre C a C++.
- Je potrebné mať nainštalované MinGW (viď vyššie) a súčasne aj utilitu MSYS. Je možné nainštalovať aj obidva tieto programy naraz. Po ukončení inštalácie je potrebné okrem cesty na adresár obsahujúci gcc.exe a g++.exe do premennej PATH pridať aj adresár obsahujúci make.exe.
- Podrobný návod na inštaláciu je k dispozícii tu, pričom odporúčame variant s MinGW.
3. Dev-C++
- Iné IDE pre Windows s pomerne bezproblémovou inštaláciou (nepotrebuje MinGW).
- Dostupné je tu.
4. Code::Blocks
- Multiplatformové IDE.
- Dostupné tu.
5. Visual Studio 2015
- Profesionálne komerčné prostredie od firmy Microsoft, ktoré si ako študenti môžete na študijné účely nainštalovať podľa pokynov na fakultnej stránke
Ak máte na počítači operačný systém Windows, ale chceli by ste si vyskúšať aj prácu v Linuxe:
- Môžete si nainštalovať Linux do virtuálneho počítača, napr. pomocou programu VirtualBox.
- Alebo môžete štartovať Linux nainštalovaný na USB kľúči.
On-line prostredia
Ak máte problémy nainštalovať na svoj počítač vhodné prostredie na programovanie, môžete skúsiť webstránky, ktoré vám umožňujú písať, kompilovať a spúšťať jednoduché programy.
- Základná jednoduchá stránka: https://www.codechef.com/ide
- Mierne zložitejšia stránka, v ktorej sa dá program interaktívne spúšťať a dá sa robiť aj s SVGdraw: http://www.tutorialspoint.com/compile_cpp11_online.php
Tieto stránky nebudete môcť používať na skúške.
Kontrola práce s pamäťou programom valgrind
V druhej polovici semestra budeme pracovať aj so smerníkmi a alokáciou pamäte. Na odhalenie chýb, ktoré pri práci s pamäťou vznikajú, môžete použiť program valgrind.
Valgrind
- C-čko pri použití polí a smerníkov nekontroluje, či ich používame správne
- Chybou v programe sa nám teda ľahko môže stať, že čítame alebo píšeme mimo alokovanej pamäte
- Takéto chyby sa niekedy ťažko hľadajú
- V Linuxe nám na hľadanie takýchto chýb pomôže nástroj valgrind, ktorý môžete použiť aj na skúške
- Vo Windows môžete použiť Dr. Memory
Spustenie programu v nástroji valgrind pri použití Kate
- Na príkazovom riadku v editore Kate spúšťate váš program príkazom typu ./prog, kde prog.cpp je meno vášho súboru
- Namiesto toho napíšete valgrind ./prog
- Nástroj valgrind bude náš program pozorne sledovať a keď robí divné veci v pamäti, vypíše nám o tom správu
- Aby boli tieto správy zrozumiteľnejšie (obsahovali čísla riadkov), lepšie je skompilovať program s prepínačom -g
- Namiesto make prog teda napíšete g++ -g prog.cpp -o prog alebo ešte lepšie je zapnúť si aj varovania kompilátora
- g++ -g -Wall prog.cpp -o prog
Spustenie programu v nástroji valgrind pri použití Netbeans
- Keď v Netbeans spustíme nástroj Build (ikonka kladivka; spúšťa sa tiež automaticky pred spustením programu), Netbeans zavolá kompilátor a vytvorí spustiteľný súbor
- Tento spustiteľný súbor nájdeme v adresári typu NetBeansProjects/meno_projektu/dist/Debug/GNU-Linux-x86/, volá sa rovnako ako projekt
- V Linuxe si ho môžeme na príkazovom riadku spustiť aj mimo prostredia Netbeans, stačí napísať NetBeansProjects/meno_projektu/dist/Debug/GNU-Linux-x86/meno_projektu
- Namiesto toho ho môžeme spustiť valgrind NetBeansProjects/meno_projektu/dist/Debug/GNU-Linux-x86/meno_projektu
- Nástroj valgrind bude náš program pozorne sledovať a keď robí divné veci v pamäti, vypíše nám o tom správu
Ukážky chýb a výsledok z valgrind
Neinicializovaná premenná
Nasledujúci program vypisuje neinicializovanú premennú i
#include <iostream>
using namespace std;
int main(void) {
int i; cout << i << endl;
}
Valgrind vypíše okrem iného
==25895== Conditional jump or move depends on uninitialised value(s) ==25895== at 0x4F3CCAE: std::ostreambuf_iterator<char, std::char_traits<char> > std::num_put<char, std::ostreambuf_iterator<char, std::char_traits<char> > >::_M_insert_int<long>(std::ostreambuf_iterator<char, std::char_traits<char> >, std::ios_base&, char, long) const (in /usr/lib/x86_64-linux-gnu/libstdc++.so.6.0.21) ==25895== by 0x4F3CEDC: std::num_put<char, std::ostreambuf_iterator<char, std::char_traits<char> > >::do_put(std::ostreambuf_iterator<char, std::char_traits<char> >, std::ios_base&, char, long) const (in /usr/lib/x86_64-linux-gnu/libstdc++.so.6.0.21) ==25895== by 0x4F493F9: std::ostream& std::ostream::_M_insert<long>(long) (in /usr/lib/x86_64-linux-gnu/libstdc++.so.6.0.21) ==25895== by 0x40082C: main (prog.cpp:4) ==25895== ==25895== Use of uninitialised value of size 8 ==25895== at 0x4F3BB13: ??? (in /usr/lib/x86_64-linux-gnu/libstdc++.so.6.0.21) ==25895== by 0x4F3CCD9: std::ostreambuf_iterator<char, std::char_traits<char> > std::num_put<char, std::ostreambuf_iterator<char, std::char_traits<char> > >::_M_insert_int<long>(std::ostreambuf_iterator<char, std::char_traits<char> >, std::ios_base&, char, long) const (in /usr/lib/x86_64-linux-gnu/libstdc++.so.6.0.21) ==25895== by 0x4F3CEDC: std::num_put<char, std::ostreambuf_iterator<char, std::char_traits<char> > >::do_put(std::ostreambuf_iterator<char, std::char_traits<char> >, std::ios_base&, char, long) const (in /usr/lib/x86_64-linux-gnu/libstdc++.so.6.0.21) ==25895== by 0x4F493F9: std::ostream& std::ostream::_M_insert<long>(long) (in /usr/lib/x86_64-linux-gnu/libstdc++.so.6.0.21) ==25895== by 0x40082C: main (prog.cpp:4)
Dôležitá informácia je, že chyba nastala na riadku 4 v programe prog.cpp
Neinicializovaný smerník
Nasledujúci program zapisuje do pamäte, na ktorú ukazuje smerník s neinicializovnaou hodnotou
#include <iostream>
using namespace std;
int main(void) {
int *p;
*p = 7;
cout << *p << endl;
}
==25923== Use of uninitialised value of size 8 ==25923== at 0x400822: main (prog.cpp:5) ==25923== ==25923== Invalid write of size 4 ==25923== at 0x400822: main (prog.cpp:5) ==25923== Address 0x0 is not stack'd, malloc'd or (recently) free'd ==25923== ==25923== ==25923== Process terminating with default action of signal 11 (SIGSEGV) ==25923== Access not within mapped region at address 0x0 ==25923== at 0x400822: main (prog.cpp:5) ==25923== If you believe this happened as a result of a stack ==25923== overflow in your program's main thread (unlikely but ==25923== possible), you can try to increase the size of the ==25923== main thread stack using the --main-stacksize= flag. ==25923== The main thread stack size used in this run was 8388608.
Chybné odalokovanie
Tento program sa pokúša odalokovať pamäť, ktorá nebola alokovaná
#include <iostream>
using namespace std;
int main(void) {
int i = 7;
int *p = &i;
delete p;
}
==25952== Invalid free() / delete / delete[] / realloc() ==25952== at 0x4C2F24B: operator delete(void*) (in /usr/lib/valgrind/vgpreload_memcheck-amd64-linux.so) ==25952== by 0x4007A7: main (prog.cpp:6) ==25952== Address 0xfff0002bc is on thread 1's stack ==25952== in frame #1, created by main (prog.cpp:3)
Písanie za koniec poľa
Ani valgrind nemusí nájsť všetky chyby, napr. tu sa k premennej správame ako ku poľu a píšeme mimo, ale valgrind si to nevšimne:
#include <iostream>
using namespace std;
int main(void) {
int i;
int *p = &i;
for(int j = 0; j<2; j++) {
p[j] = j;
}
}
Ak index 2 nahradíme 200, valgrind už vypíše chybu...
- Celkovo valgrind lepšie deteguje chyby týkajúce sa dynamicky alokovanej pamäte (pomocou new)
Hľadanie neodalokovanej pamäte
Valgrind nám tiež môže pomôcť nájsť pamäť, ktorú sme alokovali cez new, ale zabudli odalokovať cez delete alebo delete[].
- V programe nižšie máme dve volania new, ku ktorým chýba odalokovanie
#include <iostream>
using namespace std;
int main(void) {
int n = 100;
int *a = new int[n];
double *b = new double;
for(int i = 0; i<n; i++) {
a[i] = i;
}
}
Valgrind vypíše
==7556== Memcheck, a memory error detector ==7556== Copyright (C) 2002-2015, and GNU GPL'd, by Julian Seward et al. ==7556== Using Valgrind-3.11.0 and LibVEX; rerun with -h for copyright info ==7556== Command: ./prog ==7556== ==7556== ==7556== HEAP SUMMARY: ==7556== in use at exit: 73,112 bytes in 3 blocks ==7556== total heap usage: 3 allocs, 0 frees, 73,112 bytes allocated ==7556== ==7556== LEAK SUMMARY: ==7556== definitely lost: 408 bytes in 2 blocks ==7556== indirectly lost: 0 bytes in 0 blocks ==7556== possibly lost: 0 bytes in 0 blocks ==7556== still reachable: 72,704 bytes in 1 blocks ==7556== suppressed: 0 bytes in 0 blocks ==7556== Rerun with --leak-check=full to see details of leaked memory ==7556== ==7556== For counts of detected and suppressed errors, rerun with: -v ==7556== ERROR SUMMARY: 0 errors from 0 contexts (suppressed: 0 from 0)
- Vidíme teda, že počas beho programu sa alokovali 3 kusy pamäte a ani jeden sa neodalokoval
- Z toho jedno alokovanie bolo v štandardnej knižnici, ale tie ďalšie dve sú naše a bolo by pekné ich odalokovať
- Neodalokovaná pamäť v knižnici je označená ako "still reachable", takú môžete ignorovať. Zaujíma vás pamäť označená ako "definitely lost", prípadne "indirectly lost".
- Podľa pokynov programu spustíme valgrind --leak-check=full ./prog
- Pribudne podrobnejší rozbor neodalokovanej pamäte
==7565== HEAP SUMMARY: ==7565== in use at exit: 73,112 bytes in 3 blocks ==7565== total heap usage: 3 allocs, 0 frees, 73,112 bytes allocated ==7565== ==7565== 8 bytes in 1 blocks are definitely lost in loss record 1 of 3 ==7565== at 0x4C2E0EF: operator new(unsigned long) (in /usr/lib/valgrind/vgpreload_memcheck-amd64-linux.so) ==7565== by 0x40078B: main (prog.cpp:6) ==7565== ==7565== 400 bytes in 1 blocks are definitely lost in loss record 2 of 3 ==7565== at 0x4C2E80F: operator new[](unsigned long) (in /usr/lib/valgrind/vgpreload_memcheck-amd64-linux.so) ==7565== by 0x40077D: main (prog.cpp:5) ==7565==
- valgrind nám teraz vypísal, na ktorom riadku je new, ku ktorému nebol volaný delete (riadky 5 a 6 v súbore prog.cpp)
- tu to vidíme ľahko aj bez valgrind, ale vo väčšom programe vám táto informácia môže pomôcť
Cvičenie
Nasledujúci program by mal správne vypísať text "AhojAhojAhojAhoj", ale je v ňom zopár chýb. Skúste nájsť a opraviť chyby čítaním programu, použitím debugera, programu valgrind, prípadne si pridajte nejaké pomocné výpisy premenných.
- v programe valgrind je vždy dobré začať od prvej vypísanej chyby, opraviť ju a spustiť valgrind znovu
#include <iostream>
using namespace std;
void opakuj(char kam[], char co[], char kolko) {
/* Funkcia dostane na vstupe retazec co a cislo kolko a nakopiruje ho tolkokrat
* za sebou do retazca kam. */
int i=0; // pozicia v kam
for(int opakovanie=0; opakovanie<kolko; opakovanie++) { // opakuj kopirovanie
for(int j=0; co[j]!=0; j++) { // prechod cez znaky retazca co
kam[i] = co[j];
i++;
}
}
}
int main(void) {
char ahoj[4] = {'A', 'h', 'o', 'j'};
char vysledok[16];
opakuj(vysledok, ahoj, 4);
cout << vysledok << endl;
}
Prednáška 1
Pozrite si úvod k predmetu a pravidlá.
Oznamy
- Zajtra budú hlavné cvičenia s prvými bodovanými príkladmi
- Stretneme sa všetci v H6, po krátkom úvode sa rozdelíme medzi H3 a H6
- Oboznámenie sa s prostredím, s testovačom, riešenie jednoduchých príkladov k prvej prednáške
- Budete potrebovať prihlasovacie meno a heslo do AIS2 na prihlásenie na počítač v učebni
- Aspoň na úvod cvičenia odporúčame prísť aj pokročilým
- Ak z vážnych príčin nemôžete prísť, kontaktujte nás a dohodneme náhradné riešenie
- V stredu druhá prednáška, v piatok doplnkové cvičenia
- Do zajtra sa v prípade záujmu prihláste na test pre pokročilých
- Test pre pokročilých bude v stredu večer
- Ak si neviete C++ nainštalovať na notebook, prineste ho na doplnkové cvičenia niektorý piatok, skúsime pomôcť
Programátorské prostredie
- Na tomto predmete budeme programovať v jazyku C++, budeme však z neho používať len malú časť
- Cvičenia a skúšky budú v operačnom systéme Linux, ukážeme vám ako používať editor Kate
- Môžete používať aj iné programátorské prostredia, ale
- odovzdané programy musia správne pracovať na testovači
- počas skúšky budete mať k dispozícii len to, čo beží v učebniach v Linuxe
- viac informácií na stránke o alternatívach ku Kate
- Potrebné nástroje si môžete nainštalovať zadarmo aj na vašom počítači alebo môžete mimo rozvrhu používať školské učebne
Prvý program
- Tradične sa v učebniciach programovania ako prvý uvádza program, ktorý iba vypíše na obrazovku text "Hello world!". Tu je v jazyku C++:
#include <iostream>
using namespace std;
int main() {
cout << "Hello world!" << endl;
}
- Samotný text je vypísaný príkazom cout << "Hello world!" << endl;
- Všimnite si, že text Hello world! sme dali do úvodzoviek, čím poukazujeme na to, že to nie sú príkazy programovacieho jazyka, ale text, s ktorým treba niečo robiť.
- Za príkaz sme dali bodkočiarku, ktorá ho ukončuje.
- O vypisovaní si povieme viac neskôr, ale už teraz môžete vypisovať rôzne texty tým, že zmeníte text medzi úvodzovkami.
- Riadok int main() { označuje začiatok programu, program ide až po ukončovaciu zloženú zátvorku }
- Jazyk C++ sám o sebe neobsahuje príkazy na vypisovanie (cout <<...). Na to potrebujeme použiť knižnicu: súbor príkazov, ktoré niekto už naprogramoval a my ich len používame. Prvé dva riadky programu nám umožnia používať štandardnú knižnicu iostream, ktorá je súčasťou C++ a ktorá obsahuje príkazy na vypisovanie.
Spúšťanie programu
- Na to, aby sme náš program mohli spustiť na počítači, potrebujeme ho najskôr skompilovať, t.j. preložiť do spustiteľného strojového kódu.
- Ako na to, nájdete v návode na prácu s editorom Kate
Ďalší jednoduchý program
- Podobným spôsobom môžeme vypísať aj iný text. Napríklad dnešný dátum:
#include <iostream>
using namespace std;
int main() {
cout << "Dnes je 20.9.2021." << endl;
}
- Cvičenie: Rozšírte program tak, aby na druhý riadok vypísal dátum v americkom formáte mesiac/deň/rok.
Premenné
Príklad z cvičenia by mohol vyzerať napríklad takto:
#include <iostream>
using namespace std;
int main() {
cout << "20.9.2021" << endl;
cout << "9/20/2021" << endl;
}
Ak by sme v ňom chceli zmeniť dátum na prvú prednášku o rok, museli by sme pomeniť vhodné čísla na dvoch miestach. Navyše keď vidíme v programe nejaké číslo, nemusí byť úplne jasné, čo znamená.
Program teraz prepíšeme tak, aby sme deň, mesiac a rok mali zapísané symbolicky a mohli ich meniť na jednom mieste.
#include <iostream>
using namespace std;
int main() {
int den = 20;
int mesiac = 9;
int rok = 2021;
cout << den << "." << mesiac << "." << rok << endl;
cout << mesiac << "/" << den << "/" << rok << endl;
}
Symbolickým hodnotám den, mesiac, rok sa hovorí premenné.
- Premenná je vyhradené miesto v pamäti počítača, ku ktorému v programe pristupujeme pod určitým názvom.
- Do tejto pamäti si môžeme zapísať hodnotu a neskôr ju použiť.
- Príkaz int x = 100; vytvorí novú premennú a uloží do nej hodnotu 100.
- Každá premenná má určitý typ, ktorý určuje, aké hodnoty do nej môžeme ukladať.
- Tieto premenné majú typ int, čo je skratka zo slova integer, celé číslo.
Ak v programe premenným priradíme iné čísla, môžeme vypísať iný dátum.
Príkaz int x = 100; vieme rozpísať aj na dva príkazy:
int x;
x = 100;
Prvý z nich vytvorí premennú x, ktorá bude mať nejakú ľubovoľnú hodnotu a druhý túto počiatočnú hodnotu zmení na 100.
Zhrnutie
- Programy, ktoré sme doteraz videli, vyzerali takto:
- Najprv sme zapli používanie niekoľkých knižníc
- Samotný program začínal int main() { a končil zloženou zátvorkou }
- Program mohol mať niekoľko príkazov ukončených bodkočiarkami, ktoré sa vykonávajú jeden po druhom.
- Logiku za tým, prečo jednotlivé príkazy píšu tak, ako sa píšu, sme zatiaľ ešte nevysvetľovali, mali by ste však byť schopní modifikovať príklady uvedené v prednáške menením čísel, textov v úvodzovkách, pridávaním ďalších príkazov a podobne.
- Upozornenia:
- Je rozdiel medzi malými a veľkými písmenami
- Všetky čiarky, bodkočiarky, zátvorky a podobne sú dôležité
- Na väčšine miest v programe môžeme voľne pridávať medzery a konce riadku, snažíme sa tým program spraviť prehľadný
- Programy, ktoré sme videli doteraz, nie sú veľmi zaujímavé, lebo vždy robia to isté a robia pevný počet krokov, ktoré sme museli ručne všetky vypísať. Ďalej uvidíme
- načítanie, ktoré nám umožní získať dáta od používateľa
- podmienky, ktoré nám umožnia vykonávať príkazy podľa okolností
- cykly, ktoré nám umožnia opakovať tie isté príkazy veľa krát
Textový výpis a načítanie
Vieme už vypísať niečo na obrazovku (výstup - output) a podobne môžeme aj čítať, čo nám používateľ napíše na klávesnici (vstup - input). Takéto zadané hodnoty tiež uložíme do premenných, aby sme s nimi mohli ďalej pracovať.
Sčítanie čísel
Nasledujúci program od používateľa vypýta dve čísla a vypíše ich súčet.
#include <iostream>
using namespace std;
int main() {
int x, y;
cout << "Please enter the first number: ";
cin >> x;
cout << "Please enter the second number: ";
cin >> y;
int result = x + y;
cout << x << "+" << y << "=" << result << endl;
}
Tu je príklad behu programu, keď používateľ zadal čísla 10 a 3:
Please enter the first number: 10 Please enter the second number: 3 10+3=13
- Tento program používa na vstup a výstup príkazy z knižnice iostream a teda do hlavičky programu dáme #include <iostream> a using namespace std;
- Program najskôr vytvorí dve premenné x a y typu int (a nepriradzuje im zatiaľ žiadne hodnoty)
- Potom príkazom cout vypíše text "Please enter the first number: " aby používateľ vedel, čo má robiť.
- Potom pomocou príkazu cin načíta číslo od používateľa do premennej x
- To isté opakuje pre premennú y
- Potom vytvorí novú premennú result a uloží do nej súčet x a y.
- Nakoniec vypíše výsledok aj s výrazom, ktorý sme počítali, pomocou príkazu cout.
Viac o príkaze cout
- Pomocou cout vypisujeme na konzolu, t.j. textovú obrazovku
- To, čo chceme vypísať, pošleme na cout pomocou šípky <<
- cout << endl; vypíše koniec riadku
- Môžeme naraz vypísať aj viac vecí oddelených šípkami <<
- Napr. cout << x << "+" << y << "=" << result << endl; vypíše najskôr obsah premennej x (napr. hodnotu 10), potom znamienko plus (ktoré máme v úvodzovkách), potom obsah premennej y, potom znamienko rovnosti, potom obsah premennej result a nakoniec koniec riadku.
Viac o príkaze cin
- Pomocu cin načítavame z konzoly údaje od používateľa
- Tieto údaje pošleme do premenných pomocou šípky >>
- Opäť môžeme načítať aj viac vecí naraz, napr. nasledovný úryvok si vypýta obe čísla naraz a uloží ich do premenných x a y
cout << "Please enter two numbers separated by a space: ";
cin >> x >> y;
- Pozor, cin nekontroluje, že používateľ zadáva rozumné hodnoty. Čo sa stane, ak namiesto čísla zadá nejaké písmená a podobne?
Prednáška 2
Oznamy
Opakovanie ako fungujú cvičenia:
- Na začiatku cvičení v utorok sa na testovači objaví nová sada úloh
- Prvá úloha je rozcvička, treba ju odovzdať do konca cvičenia, začnite teda touto úlohou
- Zvyšok cvičenia riešte ďalšie úlohy
- Čo nestihnete na cvičení, môžete dokončiť doma alebo na doplnkových cvičeniach v piatok, termín odovzdania je začiatok cvičenia ďalší utorok
- Úlohy sa dajú odovzdávať aj po termíne, ale nedostanete za ne body, ak sme vám neudelili výnimku
- V piatok príďte na cvičenia, ak vám zostalo veľa príkladov z utorka alebo sa vám zdajú ťažké, takže sa vám zíde pomoc. Tiež ak máte otázky k učivu všeobecne alebo chcete pomôcť s inštaláciou softvéru.
- Ak vám testovač k príkladu vypíše zelené OK, prešiel testami. Ak vypíše oranžový kód chyby, niečo je zle, treba opraviť a odovzdať znovu.
- Body za prvé cvičenia sa objavia na testovači koncom budúceho týždňa, ale zväčša dostanete body za všetky príklady, kde testovač dal OK.
Najbližšie dni na programovaní
- Dnes prednáška, ďalšie dve prednášky budúci týždeň
- Dnes nepovinný test pre pokročilých (ak ste sa prihlásili)
- Doplnkové cvičenia v piatok
- Budúci utorok ďalšie cvičenia s ďalšou sadou úloh (k prednáške dnes a v pondelok)
Technické záležitosti
- Na stránke Softvér nájdete príklady ďalších programov, ktoré môžete použiť namiesto Kate.
- Ak sa vám páči Kate, prečítajte si časť o Kate a práci na príkazovom riadku. Vo Windows si môžete nainštalovať podobný editor, napr. Notepad++.
- Ak by ste chceli viac klikacie prostredie, môžete skúsiť napríklad program Netbeans, dá sa použiť aj na skúške. Mal by sa dať nainštalovať aj vo Windows.
- Na svojom počítači máte širokú paletu možností, v čom programovať, aspoň občas ale skúste použiť Linux na cvičeniach, aby ste vedeli robiť skúšku (Kate alebo Netbeans alebo iné nástroje, nie však internetové prostredia).
Ďalšie upozornenia k štúdiu:
- V rozvrhu http://candle.fmph.uniba.sk/ vidíte všetky predmety, ktoré sú povinné, povinne voliteľné alebo výberové pre váš ročník, ale nie všetky si musíte zapísať a naopak, môžete si zapísať aj iné predmety
- Dôležité je skontrolovať si, či to máte zapísané v AIS, sedí s tým, na čo aj reálne chodíte
- Prvé dva týždne (do 3.10.) si môžete v AIS pridávať a uberať predmety, potom treba kontaktovať študijné emailom, aby vám uzatvorili zápisný list
- Prvácke povinné a povinne voliteľné predmety by ste si mali zapísať, z výberových si môžete vybrať
- Pozor na to, aby ste získali aspoň 20 kreditov za zimný semester.
Opakovanie
Doteraz sme videli:
- Načítavanie pomocou cin, výpis pomocou cout.
- Celočíselné premenné typu int.
#include <iostream>
using namespace std;
int main() {
int x, y;
cout << "Please enter the first number: ";
cin >> x;
cout << "Please enter the second number: ";
cin >> y;
int result = x + y;
cout << x << "+" << y << "=" << result << endl;
}
Komentáre
Do zdrojových kódov programov v jazykoch C a C++ je možné pridávať komentáre, čo sú časti kódu ignorované kompilátorom.
- Komentár je časť programu začínajúca /* a končiaca */ (aj cez viac riadkov)
- Komentár je aj text od // až po koniec riadku. To je užitočné na písanie krátkych komentárov.
Do komentárov sa zvyknú písať poznámky k významu okolitých príkazov, čo zlepšuje orientáciu v kóde a jeho pochopenie inými programátormi.
Príklad:
#include <iostream>
using namespace std;
/* Tento program od pouzivatela nacita dve cele cisla
* a vypise ich sucet. */
int main() {
// vytvorime premenne x a y
int x, y;
// do premennych od pouzivatela nacitame cisla
cout << "Please enter the first number: ";
cin >> x;
cout << "Please enter the second number: ";
cin >> y;
// do novej premennej result spocitame vysledok
int result = x + y;
// vysledok vypiseme
cout << x << "+" << y << "=" << result << endl;
}
Podmienka (if)
Niekedy chceme vykonať určité príkazy len ak sú splnené nejaké podmienky. To nám umožňuje príkaz if.
- Nasledujúci program si vypýta od používateľa číslo a vypíše, či je toto číslo záporné alebo nezáporné.
#include <iostream>
using namespace std;
int main() {
int x;
cout << "Zadajte cislo: ";
cin >> x;
if (x < 0) {
cout << "Cislo " << x << " je zaporne." << endl;
} else {
cout << "Cislo " << x << " je nezaporne." << endl;
}
}
- Tu je príklad dvoch behov programu:
Zadajte cislo: 10 Cislo 10 je nezaporne.
Zadajte cislo: -3 Cislo -3 je zaporne.
- Ako vidíme, za príkazom if je zátvorka s podmienkou. V našom príklade podmienka je x < 0.
- Ak je podmienka v zátvorke splnená (t.j. ak x je menšie ako nula), vykonáme príkazy v zloženej zátvorke za príkazom if.
- Ak podmienka nie je splnená (t.j. ak je x väčšie alebo rovné nule), vykonáme príkazy v zloženej zátvorke za slovom else
- Časť else {...} je možné vynechať, ak nechceme vykonávať žiadne príkazy.
- Ak za if alebo else nasleduje iba jeden príkaz, zátvorky { a } môžeme vynechať. To však ľahko vedie k chybám, preto je lepšie ich vždy použiť.
Cvičenie:
- Pomocou podmienky vypíšte absolútnu hodnotu načítaného čísla.
- Namiesto vypísania uložte túto hodnotu do premennej y, ktorá by sa dala ďalej v programe použiť.
Dátové typy int, double a bool
Na začiatok budeme pracovať s troma dátovými typmi:
- typ int pre celé čísla – príkladmi konštánt typu int sú 1, 42, -2, alebo 0.
- typ double pre reálne čísla – príkladmi konštánt typu double sú 4.2, -3.0, 3.14159, alebo 1.5e3 (1.5e3 je tzv. semilogaritmický zápis znamenajúci 1,5 ⋅ 103, t.j. 1500).
- typ bool pre logické hodnoty – jedinými konštantami sú true (ekvivalentná číselnej hodnote 1) a false (ekvivalentná číselnej hodnote 0).
Premenné typu int a double zaberajú pevne daný počet bitov, preto do nich nie je možné uložiť ľubovoľné celé alebo reálne číslo. Presný rozsah možných hodnôt môže závisieť od kompilátora, v súčasnosti však väčšinou platí:
- Typ int zvyčajne zaberá 4 bajty (32 bitov) a dajú sa ním reprezentovať celé čísla z intervalu <-2 147 483 648, +2 147 483 647>.
- Typ double zvyčajne zaberá 8 bajtov. Ním reprezentované reálne čísla sú v pamäti uložené vo forme z ⋅ a ⋅ 2b, kde z je znamienko, a je reálne číslo z intervalu <1,2) (mantisa) a b je celé číslo (exponent). Na uloženie mantisy sa používa 52 bitov a na uloženie exponentu 11 bitov. Typ double tak možno použiť na prácu s reálnymi číslami približne v rozsahu od 10-300 po 10^{300} s presnosťou na 15 až 16 platných číslic. Pri tejto reprezentácii sa nevyhradzujú pevné počty bitov na reprezentáciu celej a desatinnej časti; počet cifier pred a za rádovou čiarkou je určený exponentom. Hovoríme preto o pohyblivej rádovej čiarke.
Pretypovanie
Hodnotu niektorého z typov bool, int, double je možné skonvertovať na „zodpovedajúcu” hodnotu ľubovoľného ďalšieho z týchto typov. V takom prípade hovoríme o pretypovaní. Platí pritom nasledujúce:
- Konverzia z „menej všeobecného” typu na „všeobecnejší” sa správa očakávateľným spôsobom. Booleovské hodnoty false resp. true sa konvertujú na celé čísla 0 resp. 1, prípadne na reálne čísla 0.0 resp, 1.0; celé číslo sa tiež konvertuje na reálne číslo, ktoré je mu rovné.
- Konverzia zo „všeobecnejšieho” typu na „menej všeobecný” dodržiava určité vopred stanovené pravidlá. Napríklad pri konverzii z int alebo double na bool sa ľubovoľná nenulová hodnota skonvertuje na true a nula sa skonvertuje na false. Pri konverzii z double na int dôjde k zaokrúhleniu smerom k nule (čiže nadol pri kladných číslach, nahor pri záporných).
Pretypovanie je možné realizovať dvoma spôsobmi:
- Implicitne, napríklad priradením premennej jedného typu do premennej iného typu, alebo použitím premennej jedného typu v kontexte, kde sa očakáva premenná druhého typu.
- Explicitne, použitím pretypovacieho operátora: (nazov_noveho_typu) vyraz_stareho_typu.
Možnosti pretypovania sú ilustrované nasledujúcim ukážkovým programom.
#include <iostream>
using namespace std;
int main() {
bool b1 = true;
int n1 = 4;
double x1 = 1.234;
bool b2;
int n2;
b2 = n1; // b2 = 1
n2 = x1; // n2 = 1
cout << b2 << " " << n2 << endl; // Vypise 1 1
x1 = n2; // x1 = 1.0
cout << x1 << endl; // Vypise 1
cout << (bool) 7 << " " << (bool) 0 << endl; // Vypise 1 0
cout << (int) 4.2 << " " << (int) -4.2 << endl; // Vypise 4 -4
}
Aritmetické operátory a výrazy
Na typoch int aj double sa dajú robiť základné aritmetické operácie
- sčítanie +
- odčítanie -
- násobenie *
- delenie /
Operátor / sa na argumentoch typu int správa ako celočíselné delenie – hodnota podielu sa zaokrúhli smerom k nule.
- Napríklad výraz 5/3 má hodnotu 1.
- Akonáhle je však aspoň jeden operand typu double, interpretuje sa / ako delenie reálnych čísel.
- Výrazy 5.0/3.0, 5.0/3, 5/3.0 a 5/(double)3 teda majú všetky hodnotu 1.66667.
#include <iostream>
using namespace std;
int main() {
int a = 4;
int b = 3;
// Automaticky pretypuje cele cislo 3 na realne cislo 3.0
double d = 3;
// Celociselne delenie: 4 / 3 = 1
cout << a / b << endl;
// Necelociselne delenie: 4 / 3.0 = 1.33333
cout << a / d << endl;
// Necelociselne delenie: (1.0 * 4) / 3 = 4.0 / 3 = 1.33333
cout << (1.0 * a) / b << endl;
// Necelociselne delenie: 3.0 / 4 = 1.33333
cout << ((double)a) / b << endl;
// Do e je priradeny vysledok celociselneho delenia 4 / 3 = 1;
// po pretypovani je to rovne 1.0
double e = a / b;
// Vypise 1
cout << e << endl;
// Vypise 0.5, lebo 1.0 / 2 je necelociselne delenie
cout << e / 2 << endl;
}
- Na celých číslach je definovaný operátor %, ktorého výstupom je zvyšok po celočíselnom delení (modulo). Napríklad výraz 5%3 má hodnotu 2.
- Ďalšie matematické operácie a funkcie vyžadujú #include <cmath> (pre jazyk C++) v hlavičke programu:
- Napríklad cos(x), sin(x), tan(x) (tangens), acos(x) (arkus kosínus), exp(x) (ex), log(x) (prirodzený logaritmus), pow(x,y) (xy), sqrt(x) (odmocnina), abs(x) (absolútna hodnota), floor(x) (dolná celá časť), ...
- Viac detailov možno nájsť v dokumentácii.
Relačné operátory
Hodnoty typov int, double a bool možno porovnávať nasledujúcimi relačnými operátormi:
- == pre rovnosť;
- != pre nerovnosť;
- < pre reláciu „menší”;
- > pre reláciu „väčší”;
- <= pre reláciu „menší alebo rovný”;
- >= pre reláciu „väčší alebo rovný”.
Výstupom relačného operátora je logická hodnota true alebo false.
Logické operátory a výrazy
Na výrazoch typu bool sú definované logické operátory, ktoré sa správajú rovnako ako logické spojky známe z výrokovej logiky:
- || pre disjunkciu (or, alebo);
- && pre konjunkciu (and, a súčasne);
- ! pre negáciu (not, opak)
Logickým výrazom je napríklad !((x >= 2) && (x <= 4)) alebo !true.
Operátory priradenia, inkrementu a dekrementu
Operátor priradenia premenna = hodnota už poznáme. Často realizovanou operáciou na číslach je zvýšenie hodnoty o 1. To možno urobiť napríklad nasledujúcimi spôsobmi:
- x = x + 1;
- x += 1;
- x++;
Analogicky sú definované operátory ako --, -=, *=, atď.
Priorita a asociativita operátorov
Výrazy sa vyhodnocujú v nasledujúcom poradí preferencie jednotlivých operátorov. Operátory v jednom riadku majú rovnakú prioritu a operátory vo vyššom riadku majú vyššiu prioritu, než operátory v nižších riadkoch.
- ++ (inkrement), -- (dekrement), ! (logická negácia)
- *, /, %
- +, -
- <, >, <=, >=
- ==, !=
- && (logická konjunkcia)
- || (logická disjunkcia)
- = (priradenie)
Poradie vyhodnocovania je možné meniť zátvorkami, ako napríklad vo výraze 4*(5-3).
Uvedené operátory sa väčšinou vyhodnocujú zľava doprava (hovoríme, že sú zľava asociatívne) – napríklad 1 - 2 - 3 sa teda vyhodnotí ako (1 - 2) - 3, t.j. -4 a nie ako 1 - (2 - 3), t.j. 2. Výnimkou sú operátory !, ++, -- a =, ktoré sú sprava asociatívne. To umožňuje napríklad viacnásobné priradenie a = b = c, ktoré najprv priradí hodnotu c do b a následne hodnotu výrazu b = c – tou je nová hodnota premennej b, čiže hodnota premennej c –, do a.
Viac sa o operátoroch v C++ možno dočítať napríklad tu.
Viac o podmienkach
Vnorené podmienky
Príkazy if môžeme navzájom vnárať.
Príklad: načítaj číslo a zisti, či je kladné, záporné alebo nula.
#include <iostream>
using namespace std;
int main() {
int x;
cout << "Please enter some number: ";
cin >> x;
if (x == 0) {
cout << "Zero" << endl;
} else {
if (x > 0) {
cout << "Positive" << endl;
} else {
cout << "Negative" << endl;
}
}
}
Logické výrazy môžu byť efektívnym nástrojom na elimináciu množstva vnorených podmienok: napríklad konštrukcia typu
if (a == 0) {
if (b == 0) {
čokoľvek
}
}
je ekvivalentná konštrukcii
if (a == 0 && b == 0) {
čokoľvek
}
Upozornenie
Častou chybou je použitie priradenia namiesto porovnania. Nasledujúci kúsok programu do premennej x priradí nulu, ktorá sa premení na false pre účely vyhodnotenia podmienky.
if (x=0) cout << “zero” << endl;
Ďalšia bežná chyba je zabudnutie zložených zátvoriek
if (x==0) cout << “zero”; cout << endl;
Tento program vykoná cout << endl vždy, nezávisle od podmienky. V prípade, že chceme vykonať v podmienke viacero príkazov, nesmieme zabudnúť ich uzátvorkovať:
if (x==0) { cout << “zero”; cout << endl; }
Cvičenia
- Napíšte program, ktorý načíta čísla a,b,c a vypíše, či sú usporiadané vzostupne, t.j. či platí a<b<c
- Pozor, výraz a<b<c treba rozpísať na dve porovnania spojené logickou spojkou
Cyklus for
Dôležitou časťou programovania je schopnosť opakovanie vykonávať tie isté príkazy. Prvou možnosťou ako to robiť, je cyklus for.
Príklad 1: vypisovanie čísel od 1 po n
Nasledujúci program načíta zo vstupu číslo n a postupne vypíše prirodzené čísla od 1 po n (pred každé dá medzeru).
#include <iostream>
using namespace std;
int main() {
int n;
cin >> n;
for (int i = 1; i <= n; i++) {
cout << " " << i;
}
cout << endl;
}
Tu je výstup programu pre n = 9:
1 2 3 4 5 6 7 8 9
Cyklus for vyzeral v programe takto:
for (int i = 1; i <= n; i++) {
telo cyklu
}
Táto konštrukcia pozostáva z kľúčového slova for nasledovaným zátvorkou s troma časťami oddelenými bodkočiarkami:
- Príkaz int i = 1 vytvorí novú celočíselnú premennú i a priradí jej hodnotu 1.
- Podmienka i <= n určuje dokedy sa má cyklus opakovať. V tomto prípade to má byť kým je hodnota premennej i menšia alebo rovná n.
- Príkaz i++ hovorí, že po každom zopakovaní cyklu (t.j. po každej jeho iterácii) sa má hodnota premennej i zvýšiť o jedna.
- Medzi zloženými zátvorkami { a } je potom tzv. telo cyklu – čiže jeden alebo viac príkazov, ktoré sa budú opakovať postupne pre rôzne hodnoty premennej i.
V príklade 1 je telom cyklu iba príkaz cout << " " << i;, ktorý vypíše medzeru a hodnotu premennej i.
Príklad 2: vypisovanie čísel od 0 po n-1
Drobnou zmenou predchádzajúceho programu môžeme napríklad vypísať všetky čísla od 0 po n-1:
#include <iostream>
using namespace std;
int main() {
int n;
cin >> n;
for (int i = 0; i < n; i++) {
cout << " " << i;
}
cout << endl;
}
Tu je výstup programu pre n = 9:
0 1 2 3 4 5 6 7 8
Príklad 3: výpočet faktoriálu
Nasledujúci program si od používateľa vypýta číslo n a vypočíta n!, t.j. súčin celých čísel od 1 po n.
#include <iostream>
using namespace std;
int main() {
int n;
cout << "Zadajte n: ";
cin >> n;
int vysledok = 1;
for (int i = 1; i <= n; i++) {
vysledok = vysledok * i;
}
cout << n << "! = " << vysledok << endl;
}
Príklad behu programu pre n=4 (1*2*3*4=24):
Zadajte n: 4 4! = 24
- Program používa premennú vysledok, ktorú na začiatku inicializuje hodnotou 1 a postupne ju násobí číslami 1, 2, ..., n.
- Riadok vysledok = vysledok * i; zoberie pôvodnú hodnotu premennej vysledok, vynásobí ju hodnotou premennej i (t.j. jedným z čísel 1, 2, ..., n) a výsledok uloží naspäť do premennej vysledok (prepíše pôvodnú hodnotu). To isté sa dá napísať ako vysledok *= i;
Funkcia n! však veľmi rýchlo rastie a už pre n=13 sa výsledok nezmestí do premennej typu int. Dostávame nezmyselné hodnoty:
12! = 479001600 13! = 1932053504 14! = 1278945280 15! = 2004310016 16! = 2004189184 17! = -288522240
Správne hodnoty (ktoré možno získať zmenou typu premennej vysledok na long long int) sú:
12! = 479001600 13! = 6227020800 14! = 87178291200 15! = 1307674368000 16! = 20922789888000 17! = 355687428096000
Cvičenie: rozšírte program tak, aby okrem výpisu výsledku aj rozpísal faktoriál ako súčin:
Zadajte n: 4 4! = 1*2*3*4 = 24
Zhrnutie
Poznáme základné stavebné prvky, z ktorých sa dajú spraviť aj pomerne zložité programy:
- premenné typu int, double, bool a operátory, ktoré s nimi vedia počítať
- podmienku if, ktorá umožňuje vykonávať určité časti programu len za nejakých okolností
- cyklus for, ktorý umožnuje opakovať určité časti programu veľa krát
Cieľom najbližšej prednášky a cvičení je hlavne precvičiť si tieto stavebné prvky na veľa ďalších príkladoch.
Cvičenia 1
Cieľom prvých cvičení je:
- vyskúšať si prihlásenie na počítače v učebni a prácu v prostredí Kate, prípadne v iných prostrediach
- precvičiť si písanie jednoduchých programov
- vyskúšať si prácu s testovačom
Počas cvičení alebo najneskôr do piatku prosím vyplňte aj anonymnú anketu o vašich programátorských skúsenostiach.
Príklad 0: Sčítanie čísel
- Zapnite počítač, zvoľte Linux, prihláste sa heslom ako do AIS
- Otvorte si stránku predmetu http://compbio.fmph.uniba.sk/vyuka/prog/, nájdite prvé cvičenia (tento text)
- Spustite editor Kate podľa návodu tu
- Skopírujte si Program na sčítanie čísel z prvej prednášky
- Skúste ho skompilovať a spustiť.
Príklad 1: odovzdávanie na testovači domácich úloh
- Prihláste sa na testovač, zmeňte si heslo
- Pozrite si Návod na prácu s testovačom
- Nájdite si zadanie príkladu 1 na testovači, je to len malá modifikácia sčítania dvoch čísel
- Rozdiel je, že testovaču nebudeme vypisovať, aby zadal číslo a na výstupe vypíšeme iba samotný súčet.
- Zmodifikujte program podľa požiadaviek zadania a odovzdajte ho na testovači
- Pozrite si výsledky testovania, ak nedostanete odpoveď OK, skúste chybu opraviť
- Tento príklad je rozcvička, body zaňho dostanete, len ak ho dokončíte počas cvičenia
Ďalšie bodované príklady
- Ďalšie zadania na tento týždeň nájdete priamo na testovači. Prvé tri príklady sa týkajú pondelkovej prednášky, ďalšie tri už potrebujú učivo zo stredy.
- Ak ste všetky príklady nevyriešili, odporúčame vám prísť na doplnkové cvičenia v piatok a pokračovať v ich riešení
- Môžete ich riešiť aj doma, až do začiatku cvičení budúci utorok
- Tento týždeň na doplnkových cvičeniach ešte nebude rozcvička za bonusové body
Testovač
Príklady z cvičení, domácich úloh, ale aj na záverečnej skúške budete odovzdávať na stránke http://prog.dcs.fmph.uniba.sk/ , ktorá bude súčasne mnohé z vašich riešení aj testovať.
- Na stránku sa prihláste heslom, ktoré dostanete na prvých cvičeniach, po prihlásení si ho zmeňte.
- Na testovači uvidíte zoznam príkladov, spolu s ich zadaniami v pdf formáte a s ďalšími potrebnými súbormi (napr. kostra programu, príklady vstupu)
- Vaše programy môžete odovzdať buď zvolením súboru s programom (.cpp) z disku alebo nakopírovaním programu do textového poľa.
- Váš program sa uloží na testovači a môžete si neskôr skontrolovať, či ste odovzdali správnu verziu.
- Testovač váš program skompiluje a spustí na niekoľkých vstupoch. Výsledok testovania vám zobrazí.
- V závislosti od zaťaženia servera zobrazenie výsledku môže nejaký čas trvať.
- V ideálnom prípade dostanete výsledok OK, ak váš program vypísal na všetkých vstupoch správnu odpoveď.
- Môže však dôjsť k rôznym chybám:
- CE (compile error): chyba pri kompilácii, testovač vypíše výstup kompilátora. Odporúčame pred odovzdaním program skompilovať na vašom počítači.
- WA (wrong answer): na niektorom vstupe váš program vypísal zlú odpoveď. Môže ísť o závažnú chybu v programe, ale aj len o malý problém vo formáte výstupu. Testovač väčšinou porovnáva váš výsledok znak po znaku so správnym výsledkom a každý rozdiel, ako napríklad medzera navyše, považuje za chybu. Pozrite si detaily testovania, či nezbadáte rozdiely vo formáte.
- TO (time limit exceeded): program na príslušnom vstupe bežal príliš dlho. Nakoľko dávame pomerne veľké časové limity, pravdepodobne váš program sa "zacyklil", t.j. beží do nekonečna.
- SG (segmentation fault): váš program spadol na chybu pri behu, napr. delenie nulou, prístup mimo hraníc poľa, prípadne priveľká spotreba pamäte.
- Kód WAITING znamená, že váš program ešte čaká na spustenie a RUNNING znamená, že prebieha jeho testovanie.
- Pri týchto problémoch skúste program spúšťať na viacerých vstupoch na vašom počítači a chybu objaviť. Niekedy vám poskytneme aj vstupy a výstupy použité na testovači, ktoré vám pomôžu pri hľadaní chyby. V opačnom prípade si skúste nejaké vstupy vymyslieť sami.
- Program opravujte až kým nedostanete OK na všetkých vstupoch.
- Testovač vám dovolí odovzdať program aj po termíne, ale takéto pokusy už nebudú brané do úvahy pri bodovaní, pokiaľ nemáte dohodnuté individuálne predĺženie termínu s vyučujúcimi.
- Ak testovač nefunguje alebo ak nájdete chybu v zadaní, dajte nám vedieť na adrese
 Takisto na túto adresu posielajte otázky k zadaniam alebo prosby o pomoc s konkrétnou úlohou.
Takisto na túto adresu posielajte otázky k zadaniam alebo prosby o pomoc s konkrétnou úlohou.
Poznámka o vstupe a výstupe
- Ak v zadaní nie je povedané inak, všetok vstup načítavajte z konzoly príkazmi cin (prípadne scanf a pod.) a vypisujte na konzolu príkazmi cout (prípadne printf a pod.)
- Vstup uvedený v zadaní má testovač v súbore a presmeruje ho vášmu programu na konzolu, t.j. správa sa podobne, ako keby niekto zadával príslušné hodnoty ručne počas behu vášho programu
- Naopak testovač zachytí do súboru všetko, čo váš program vypíše na konzolu. Tento súbor potom porovnáva so správnou odpoveďou.
- Napr. program na sčítanie čísel z prvej prednášky by mohol mať nasledovný vstup a výstup na testovači:
10 3
Please enter the first number: Please enter the second number: 10+3=13
- V príkladoch na testovači väčšinou vynecháme interaktívne časti, program si teda nebude pýtať čísla od užívateľa, predpokladá, že ten ich sám od seba zadá.
Nastavenia kompilátora
- Vaše programy kompilujeme pomocou gcc 9.3.0 s nastaveniami g++ -static -std=gnu++11 -O2 -Wall -Wextra
Prednáška 3
Oznamy
Budúci pondelok 4. októbra bude na časti prednášky teoretické cvičenie
- Budete písať krátky test zameraný učivo z prvých troch prednášok
- Tento test sa počíta do druhých cvičení. Ak ich máte uznané z testu pre pokročilých, na test nemusíte ísť
- Na teste bude povolené používať pero a ťahák vo forme jedného obojstranne popísaného listu A4
Ciele teoretického cvičenia
- Precvičiť si poriadnejšie základné konštrukty
- Vynechaním časti prednášky vznikne väčší priestor precvičiť si základy
- Vyskúšať si prácu na papieri (bude treba na aj semestrálnom teste, ktorý má oveľa väčšiu váhu)
Prečo robíme toto cvičenie a písomné testy na papieri?
- Dobré na precvičenie porozumenia hotovým programom (treba na ďalších predmetoch aj pri štúdiu odbornej literatúry)
- Núti vás dobre si premyslieť každý detail, nie len náhodne skúšať meniť rôzne časti programu, kým nezačne fungovať
- Pri zložitejších programoch sa už nedá postupovať náhodne
- Na papieri miernejšie hodnotíme drobné chyby ako chýbajúca bodkočiarka, to vám na počítači pomôže nájsť kompilátor. Dôležitejšie je sa rozhodnúť, či má byť niekde napríklad i<n alebo i<=n.
Opakovanie: výpočet faktoriálu
#include <iostream>
using namespace std;
int main() {
int n;
cout << "Zadajte n: ";
cin >> n;
int vysledok = 1;
for (int i = 1; i <= n; i++) {
vysledok = vysledok * i;
}
cout << n << "! = " << vysledok << endl;
}
Príklad behu programu pre n=4:
Zadajte n: 4 4! = 24
Cvičenie: rozšírte program tak, aby okrem výpisu výsledku aj rozpísal faktoriál ako súčin:
Zadajte n: 4 4! = 1*2*3*4 = 24
Ďalšie príklady na cyklus for
Simulovanie hodov kocky
Nasledujúci program od používateľa načíta číslo n a vypíše n simulovaných hodov kocky (každý na samostatný riadok).
#include <iostream>
#include <cstdlib>
#include <ctime>
using namespace std;
int main() {
// Inicializacia generatora pseudonahodnych cisel
srand(time(NULL));
int n;
cout << "Zadajte pocet hodov: ";
cin >> n;
for (int i = 1; i <= n; i++) {
// Vygenerovanie a vypisanie hodu kockou
cout << rand() % 6 + 1 << endl;
}
}
Príklad behu programu:
Zadajte pocet hodov: 6 2 6 1 2 1 4
- Program využíva funkciu rand(), ktorá generuje pseudonáhodné celé čísla.
- Nie sú v skutočnosti náhodné, lebo ide o pevne definovanú matematickú postupnosť, ktorá však má mnohé vlastnosti náhodných čísel.
- Aby bolo možné použiť túto funkciu, treba do hlavičky pridať #include <cstdlib>.
- Výstupom funkcie rand() je nezáporné celé číslo medzi nulou a nejakou veľkou konštantou.
- Zvyšok po delení tohto čísla šiestimi, t.j. rand() % 6, je potom číslo medzi 0 a 5. Ak k tomu pripočítame 1, dostaneme číslo od 1 po 6.
- Funkcia srand inicializuje generátor pseudonáhodných čísel na základe parametra určujúceho počiatočný bod pseudonáhodnej postupnosti.
- My ako tento parameter používame aktuálny čas (v sekundách od začiatku roku 1970), čo zaručuje dostatočný efekt náhodnosti.
- Aby bolo možné použiť funkciu time, je treba do hlavičky pridať #include <ctime>.
Vypisovanie deliteľov (podmienka v cykle)
Nasledujúci program načíta od používateľa prirodzené číslo n a vypíše zoznam jeho deliteľov.
- číslo i delí číslo n práve vtedy, keď zvyšok po delení čísla n číslom i je 0
#include <iostream>
using namespace std;
int main() {
int n;
cout << "Zadajte cislo: ";
cin >> n;
cout << "Delitele cisla " << n << ":";
for (int i = 1; i <= n; i++) {
if (n % i == 0) {
cout << " " << i;
}
}
cout << endl;
}
Príklad behu programu:
Zadajte cislo: 30 Delitele cisla 30: 1 2 3 5 6 10 15 30
Úprava a čitateľnosť programov
Pri písaní programov myslite na to, že ich typicky budú okrem počítača čítať aj ľudia (napríklad vy po dlhšom čase, učitelia, alebo kolegovia na väčšom projekte). Je preto zvykom dodržiavať určité zásady, ktoré čitateľnosť zdrojového kódu zlepšujú:
- Odsadzovanie: príkazy vykonávané v cykle, či v podmienke (alebo vo všeobecnosti v ľubovoľnom bloku medzi { a }) odsadzujeme o niekoľko pozícií doprava (napríklad o 4 medzery).
- Pri vnorených cykloch, podmienkach a podobne odsadzujeme o ďalšie štyri pozície, atď.
- Väčšina editorov a IDE pre C/C++ nejakým spôsobom odsadzovanie podporujú
- Voľné riadky: ucelené časti programu je kvôli prehľadnosti často dobré oddeliť prázdnym riadkom.
- Medzery: odporúča sa písať okolo operátorov medzery.
- Napríklad zápis
for (int i = 1; i <= n; i++) {
a += i;
}
je o dosť prehľadnejší ako
for(int i=1;i<=n;i++){a+=i;}
- Dĺžka riadku: odporúča sa vyhýbať sa riadkom dlhším ako 80 znakov. S dlhými riadkami sú problémy pri tlači alebo zobrazovaní v menších oknách; aj na veľkom monitore čitateľa zbytočne namáhajú. V prípade potreby je možné dlhšiu podmienku alebo iný výraz rozdeliť na viac riadkov.
- Názvy premenných: najmä pri rozsiahlejších programoch je vhodné používať názvy premenných, ktoré vyjadrujú ich obsah (napríklad userCount alebo pocet_pouzivatelov namiesto h). Premenné v kratších programoch, alebo premenné používané iba lokálne v kratšom kuse programu možno označovať aj krátkymi zaužívanými názvami, ako napríklad i a j pre premenné v cykloch, n pre počet, alebo a pre pole.
- Komentáre: význam jednotlivých úsekov kódu je najmä pri rozsiahlejších programoch dobré popísať v komentároch.
Pri známkovaní budeme brať do úvahy aj prehľadnosť vašich programov.
Cyklus while
Okrem cyklu for možno v jazykoch C/C++ používať aj cyklus while s nasledujúcou schémou:
while (podmienka) {
telo cyklu
}
Telo takéhoto cyklu sa vykonáva, kým je podmienka cyklu splnená. Presnejšie sa pri vykonávaní cyklu while typicky deje nasledovné:
- Overí sa, či je podmienka cyklu splnená.
- Ak áno, vykoná sa telo cyklu a celý proces sa opakuje (čiže sa opätovne vykoná overenie podmienky z bodu 1, atď.).
- Ak nie, vykonávanie programu pokračuje prvým príkazom nasledujúcim za cyklom while.
Úroky v banke
- Predpokladajme, že na začiatku každého roku uložíme na účet nejakú pevnú sumu (napríklad 1000 EUR).
- Na konci každého roku sa vklad zúročí ročným úrokom (napríklad 5%).
- Za koľko rokov úspory dosiahnu danú cieľovú čiastku (napríklad 10000 EUR)?
Túto úlohu budeme riešiť programom pracujúcim nasledovne:
- V premennej ciastka budeme uchovávať aktuálny stav účtu
- V každom roku túto premennú zvýšime o vklad a úrok
- Toto opakujeme, kým suma uložená v premennej nie je rovná aspoň cieľovej čiastke.
To môžeme vyjadriť pomocou cyklu while.
#include <iostream>
using namespace std;
int main(void) {
double vklad, ciel, urok;
cout << "Zadaj kazdorocny vklad: ";
cin >> vklad;
cout << "Zadaj cielovu ciastku: ";
cin >> ciel;
cout << "Zadaj rocny urok (v %): ";
cin >> urok;
int rok = 0;
double ciastka = 0;
while (ciastka < ciel) {
rok++;
ciastka = (ciastka + vklad) * (1 + urok / 100);
cout << "Na konci roku " << rok << " je na ucte " << ciastka << " EUR." << endl;
}
}
Ukážkový vstup a výstup:
Zadaj kazdorocny vklad: 1000 Zadaj cielovu ciastku: 10000 Zadaj rocny urok (v %): 5 Na konci roku 1 je na ucte 1050 EUR Na konci roku 2 je na ucte 2152.5 EUR Na konci roku 3 je na ucte 3310.12 EUR Na konci roku 4 je na ucte 4525.63 EUR Na konci roku 5 je na ucte 5801.91 EUR Na konci roku 6 je na ucte 7142.01 EUR Na konci roku 7 je na ucte 8549.11 EUR Na konci roku 8 je na ucte 10026.6 EUR
Euklidov algoritmus
Euklidov algoritmus slúži na hľadanie najväčšieho spoločného deliteľa dvojice kladných celých čísel a, b.
- To znamená: hľadáme najväčšie kladné prirodzené číslo d, ktoré delí súčasne a aj b.
- Najväčší spoločný deliteľ čísel a, b označujeme gcd(a,b) (z angl. greatest common divisor). V slovenčine sa používa aj s označenie nsd(a,b).
- Ide o jeden z najstarších známych algoritmov vôbec. Jeho variant popísal už Euklides v diele Základy okolo roku 300 pred Kr.
Príklad:
- Delitele čísla 12 sú 1, 2, 3, 4, 6, 12.
- Delitele čísla 8 sú 1, 2, 4, 8.
- Spoločné delitele 8 a 12 teda sú 1, 2, 4.
- Najväčší spoločný deliteľ čísel 8 a 12 je teda gcd(8,12) = 4.
Euklidov algoritmus je založený na platnosti nasledujúcej lemy.
Lema. Pre všetky kladné celé čísla a, b platí:
- gcd(a,b) = gcd(b, a mod b).
Dôkaz.
- Nech X je množina spoločných deliteľov a a b, nech Y je množina spoločných deliteľov b a a mod b. Dokážeme rovnosť X = Y.
- Ak označíme r := a mod b, tak existuje celé číslo q také, že a = q b + r.
- Ak x ∈ Y, číslo x delí b aj r a z rovnosti a = q b + r vyplýva, že delí aj a. Teda x ∈ X.
- Ak naopak x ∈ X, číslo x delí a aj b a z rovnosti r = a - qb vyplýva, že delí aj r. Preto x ∈ Y.
- Dokázali sme teda, že platí X ⊆ Y a súčasne X ⊆ Y. Preto X = Y. ◻
Poznámka: môže sa stať, že a mod b je 0. Nakoľko ale každé celé číslo delí nulu, gcd(b, 0) = b pre každé kladné b.
- Euklidov algoritmus opakovane používa lemu: gcd(12,8) = gcd(8, 4) = gcd(4, 0) = 4
- Dostáva sa k stále menším číslam, až kým b neklesne na nulu
Implementácia tohto algoritmu teda môže vyzerať nasledovne:
#include <iostream>
using namespace std;
int main() {
int a, b;
cout << "Zadaj dvojicu kladnych celych cisel: ";
cin >> a >> b;
while (b != 0) {
int r = a % b;
a = b;
b = r;
}
cout << "Najvacsi spolocny delitel je " << a << "." << endl;
}
Príklad behu programu:
Zadaj dvojicu kladnych celych cisel: 30 8 Najvacsi spolocny delitel je 2.
Tento výpočet prešiel cez dvojice:
30 8 8 6 6 2 2 0
Cvičenie: Ako bude fungovať Euklidov algoritmus pre vstupné čísla 8, 30?
Nekonečný cyklus
V cykle while typu
while (true) {
telo cyklu
}
je podmienka stále splnená; telo cyklu sa teda opakuje donekonečna resp. kým program nezastavíme (v prípade, že cyklus neukončíme umelo príkazom break, ktorý uvidíme o chvíľu).
Napríklad môžeme donekonečna niečo vypisovať:
#include <iostream>
using namespace std;
int main() {
while (true) {
cout << "Hello, World!" << endl;
}
}
Hra „hádaj číslo”
V nasledujúcom programe si počítač „myslí” číslo od 1 do 100 a užívateľ háda, o ktoré číslo ide (až kým nakoniec neuhádne).
#include <iostream>
#include <cstdlib>
#include <ctime>
using namespace std;
int main() {
srand(time(NULL));
int num = rand() % 100 + 1;
cout << "Myslim si cislo od 1 po 100. Tvoj tip: ";
bool correct = false;
while (!correct) {
int guess;
cin >> guess;
if (guess < num) {
cout << "Prilis nizko. Iny tip: ";
} else if (guess > num) {
cout << "Prilis vysoko. Iny tip: ";
} else {
correct = true;
cout << "Spravne!" << endl;
}
}
}
Príklad behu programu:
Myslim si cislo od 1 po 100. Tvoj tip: 50 Prilis nizko. Iny tip: 70 Prilis nizko. Iny tip: 90 Prilis vysoko. Iny tip: 80 Spravne!
Príkazy break a continue
V C/C++ existuje dvojica príkazov umožňujúcich umelo prerušiť vykonávanie cyklu resp. jednej jeho iterácie:
- Príkaz break ukončí cyklus, v ktorom sa program práve nachádza; vykonávanie programu pokračuje prvým príkazom za cyklom.
- Príkaz continue „skočí” na ďalšiu iteráciu cyklu, pričom nevykoná zvyšok tela cyklu.
Tieto príkazy treba používať s mierou, keďže robia program menej prehľadným a sú častým zdrojom chýb.
Hra „hádaj číslo” s príkazom break
Program uvedený vyššie môžeme prepísať bez boolovskej premennej s použitím nekonečného cyklu, z ktorého ale „vyskočíme” príkazom break, keď používateľ uhádne.
#include <iostream>
#include <cstdlib>
#include <ctime>
using namespace std;
int main() {
srand(time(NULL));
int num = rand() % 100 + 1;
cout << "Myslim si cislo od 1 po 100. Tvoj tip: ";
while (true) {
int guess;
cin >> guess;
if (guess < num) {
cout << "Prilis nizko. Iny tip: ";
} else if (guess > num) {
cout << "Prilis vysoko. Iny tip: ";
} else {
cout << "Spravne!" << endl;
break;
}
}
}
Viac o cykle for
Schéma cyklu for
Cyklus for sme doposiaľ používali iba veľmi základným spôsobom; jeho možnosti sú omnoho väčšia. Vo všeobecnosti možno schému cyklu for popísať nasledovne:
for (prikaz1; podmienka; prikaz2) {
postupnost_prikazov
}
Takýto cyklus potom pracuje nasledovne:
- Vykoná sa príkaz prikaz1.
- Kým platí podmienka podmienka, vykonáva sa telo cyklu postupnost_prikazov zakaždým nasledované príkazom prikaz2.
Uvedený cyklus for je teda typicky ekvivalentný nasledujúcemu cyklu while:
prikaz1;
while (podmienka) {
postupnost_prikazov
prikaz2;
}
(Drobnou výnimkou je prípad, keď telo cyklu for obsahuje príkaz continue. V takom prípade sa príkaz prikaz2 aj tak vykoná.)
Nasledujúce kúsky kódu napríklad obidva vypisujú čísla 1 až 9:
for (int i = 1; i <= 9; i++) {
cout << " " << i;
}
int i = 1;
while (i <= 9) {
cout << " " << i;
i++;
}
Cyklus for spravidla používame, ak má náš cyklus krátky a jednoduchý iterátor (prikaz2) a jednoduchú podmienku. V opačnom prípade väčšinou používame cyklus while.
Vypisovanie deliteľov od najväčších
Vráťme sa k programu na vypisovanie všetkých deliteľov čísla n z úvodu tejto prednášky. Tam sme deliteľov vypisovali v poradí od najmenšieho po najväčší, a to použitím cyklu
for (int i = 1; i <= n; i++)
Nahradením tohto cyklu cyklom
for (int i = n; i >= 1; i--)
získame program vypisujúci delitele v poradí od najväčšieho po najmenší.
#include <iostream>
using namespace std;
int main() {
int n;
cout << "Zadajte cislo: ";
cin >> n;
cout << "Delitele cisla " << n << ":";
for (int i = n; i >= 1; i--) {
if (n % i == 0) {
cout << " " << i;
}
}
cout << endl;
}
Príklad behu programu:
Zadajte cislo: 30 Delitele cisla 30: 30 15 10 6 5 3 2 1
Rýchlejšie hľadanie deliteľov
Program na vypisovanie deliteľov môžeme o niečo urýchliť:
- Stačí si všimnúť, že i je deliteľ čísla n práve vtedy, keď n/i je deliteľom čísla n.
- Číslo n/i teda môžeme rovno vypísať spoločne s i.
- Aspoň jedno z tejto dvojice čísel je navyše menšie alebo rovné odmocnine z n, čo znamená, že stačí prehľadať iba čísla i spĺňajúce túto podmienku.
#include <iostream>
using namespace std;
int main() {
int n;
cout << "Zadajte cislo: ";
cin >> n;
cout << "Delitele cisla " << n << ":";
for (int i = 1; i*i <= n; i++) {
if (n % i == 0) {
cout << " " << i << " " << n / i;
}
}
cout << endl;
}
Cvičenie 1: Občas sa môže stať, že program vypíše niektorého deliteľa dvakrát. Kedy? Modifikujte telo cyklu for tak, aby program každého deliteľa vypísal práve raz.
Cvičenie 2: Vyskúšajte si rýchlosť rôznych variantov programu na vypisovanie deliteľov na veľkom vstupe, napríklad pre n = 1234567890.
Nekonečný cyklus for
V cykle
for (prikaz1; podmienka; prikaz2) {
postupnost_prikazov
}
môžu byť príkazy prikaz1 a prikaz2 aj prázdne – v takom prípade sa na ich mieste nič nevykoná. Podobne môže byť prázdna aj podmienka podmienka, ktorá sa v takom prípade interpretuje ako true.
Nekonečný cyklus možno teda napísať aj ako
for ( ; true; ) {
cout << "Hello, World!" << endl;
}
prípadne ako
for ( ; ; ) {
cout << "Hello, World!" << endl;
}
Vnorené cykly
Vypíšeme tabuľku násobilky, v ktorej bude v riadku i a stĺpci j súčin i ⋅ j.
- Použijeme dva vnorené cykly: jeden pôjde cez riadky, druhý cez stĺpce.
#include <iostream>
using namespace std;
int main() {
int n; // pokial ma ist nasobilka
cin >> n;
for (int riadok = 1; riadok <= n; riadok++) {
for (int stlpec = 1; stlpec <= n; stlpec++) {
cout << " " << riadok * stlpec;
}
cout << endl;
}
}
Ukážka výstupu pre n=5:
1 2 3 4 5 2 4 6 8 10 3 6 9 12 15 4 8 12 16 20 5 10 15 20 25
Ak pred každé číslo vypíšeme namiesto medzery " " tabulátor "\t", dostaneme krajší výstup
1 2 3 4 5 2 4 6 8 10 3 6 9 12 15 4 8 12 16 20 5 10 15 20 25
Cvičenie: pridajme jednotlivým riadkom a stĺpcom hlavičku
Cykly: zhrnutie
- Videli sme niekoľko príkladov využitia cyklov for a while.
- Cyklus for je možné zapísať ako while (a naopak).
- Z cyklu vieme vyskočiť príkazom break, prejsť na ďalšiu iteráciu príkazom continue. Používať s mierou.
- Euklidov algoritmus rýchlo nájde najväčšieho spoločného deliteľa dvoch čísel.
Prednáška 4
Oznamy
Čo nás čaká v najbližších dňoch
- V piatok doplnkové cvičenia
- Príďte, ak potrebujete pomôcť s riešením úloh alebo máte iné otázky k predmetu
- V pondelok 4.10. bude časť prednášky teoretické cvičenie, na ktorom bude krátky test
- Test bude z prvých troch prednášok
- Tento test sa počíta do druhých cvičení. Ak ich máte uznané z testu pre pokročilých, na test nemusíte ísť
- Na teste bude povolené používať pero a ťahák vo forme jedného obojstranne popísaného listu A4
Funkcie
Funkcia je samostatný kus kódu (postupnosť príkazov) s určitým menom. Po zavolaní funkcie jej menom sa daná postupnosť príkazov vykoná.
- V iných programovacích jazykoch sa používajú aj podobné termíny ako procedúra, metóda, či podprogram.
- Funkcia vo všeobecnosti dostane niekoľko (aj nula) vstupných argumentov, ktoré môže pri svojom behu používať.
- Funkcia tiež môže vrátiť výstupnú hodnotu.
- Ide teda o veľmi podobný koncept ako funkcie v matematike (ako napríklad sin(x)):
- Oboje si možno predstaviť ako „krabičku”, ktorá na základe niekoľkých vstupných hodnôt vráti nejakú výstupnú hodnotu.
- Funkcie v C/C++ ale môžu okrem vracania výstupných hodnôt vykonávať ľubovoľný kód, teda napríklad aj niečo vypisovať na konzolu a podobne.
Obvod trojuholníka bez použitia funkcií
Užitočnosť funkcií ilustrujeme na príklade. Chceme napísať program, ktorý od používateľa načíta súradnice vrcholov trojuholníka ABC a na výstup vypíše obvod tohto trojuholníka. Beh takéhoto programu teda môže vyzerať napríklad takto:
Zadaj suradnice vrcholu A: 0 0 Zadaj suradnice vrcholu B: 3 0 Zadaj suradnice vrcholu C: 0 4 Obvod trojuholnika ABC: 12
Obvod spočítame ako súčet dĺžok jednotlivých strán, v programe teda trikrát opakujeme výpočet dĺžky strany:
#include <iostream>
#include <cmath>
using namespace std;
int main() {
double Ax, Ay, Bx, By, Cx, Cy;
cout << "Zadaj suradnice vrcholu A: ";
cin >> Ax >> Ay;
cout << "Zadaj suradnice vrcholu B: ";
cin >> Bx >> By;
cout << "Zadaj suradnice vrcholu C: ";
cin >> Cx >> Cy;
/* Spocitaj dlzky jednotlivych stran: */
double a = sqrt((Bx - Cx) * (Bx - Cx)
+ (By - Cy) * (By - Cy));
double b = sqrt((Ax - Cx) * (Ax - Cx)
+ (Ay - Cy) * (Ay - Cy));
double c = sqrt((Ax - Bx) * (Ax - Bx)
+ (Ay - By) * (Ay - By));
cout << "Obvod trojuholnika ABC: " << a + b + c;
}
Opakované písanie toho istého vzorca na výpočet dĺžky strany je prácne; navyše pri ňom ľahko spravíme chybu. V nasledujúcom programe ho teda nahradíme funkciou.
Obvod trojuholníka s použitím funkcie
Videli sme teda, že na výpočet obvodu trojuholníka sa nám môže zísť funkcia počítajúca vzdialenosť medzi dvoma bodmi v rovine, t.j. dĺžku úsečky. Tá môže v C/C++ vyzerať napríklad takto:
double dlzka(double x1, double y1, double x2, double y2) {
return sqrt((x1 - x2) * (x1 - x2) + (y1 - y2) * (y1 - y2));
}
Týmto sme zadefinovali funkciu s názvom dlzka so štyrmi vstupnými argumentmi x1, y1, x2, y2 typu double, reprezentujúcimi súradnice dvojice bodov v rovine. Pred samotný názov funkcie sme zadali návratový typ funkcie, ktorým je double – táto funkcia teda bude vracať na výstupe reálne čísla. Nakoniec sme zadefinovali samotné telo funkcie, tentokrát pozostávajúce z jediného špeciálneho príkazu return, ktorým funkcia vracia svoju výstupnú hodnotu.
Kompletný program na výpočet obvodu trojuholníka môže s použitím funkcie dlzka vyzerať napríklad takto:
#include <iostream>
#include <cmath>
using namespace std;
/* Definicia funkcie dlzka: */
double dlzka(double x1, double y1, double x2, double y2) {
return sqrt((x1 - x2) * (x1 - x2) + (y1 - y2) * (y1 - y2));
}
int main() {
double Ax, Ay, Bx, By, Cx, Cy;
cout << "Zadaj suradnice vrcholu A: ";
cin >> Ax >> Ay;
cout << "Zadaj suradnice vrcholu B: ";
cin >> Bx >> By;
cout << "Zadaj suradnice vrcholu C: ";
cin >> Cx >> Cy;
// Spocitaj dlzky jednotlivych stran:
// Volanie funkcie dlzka s argumentmi Bx, By, Cx, Cy
double a = dlzka(Bx, By, Cx, Cy);
// Volanie funkcie dlzka s argumentmi Ax, Ay, Cx, Cy
double b = dlzka(Ax, Ay, Cx, Cy);
// Volanie funkcie dlzky s argumentmi Ax, Ay, Bx, By
double c = dlzka(Ax, Ay, Bx, By);
cout << "Obvod trojuholnika ABC: " << a + b + c;
}
Telo funkcie nemusí pozostávať iba z jediného príkazu. Napríklad ešte jednoduchšie by sme funkciu dlzka mohli napísať takto:
double dlzka(double x1, double y1,
double x2, double y2) {
double dx = x1 - x2;
double dy = y1 - y2;
return sqrt(dx * dx + dy * dy);
}
Cvičenie:
- V Pascale existuje funkcia sqr, ktorá na vstupe berie reálne číslo x a výstupom je toto číslo umocnené na druhú. Naprogramujte túto funkciu v C/C++ a použite ju na zjednodušenie funkcie dlzka.
- Mohli by sme použiť aj pow(x,2) (treba #include <cmath>), ale môže byť jednoduchšie zrátať x*x.
Výhody funkcií
Funkcie sú užitočné z viacerých dôvodov:
- Umožňujú vytvoriť „skratku” pre často používané časti kódu, ktoré tak nie je nutné zakaždým písať nanovo.
- Umožňujú používanie kusov kódu vytvorených iným programátorom. Napríklad sme použili funkciu sqrt, ktorá vráti druhú odmocninu svojho vstupu.
- Funkcie umožňujú rozdeliť písanie programu na menšie časti. Zvlášť sa môžeme sústrediť na telo programu, ktoré používa funkciu a zvlášť na implementáciu samotnej funkcie. Tieto dve časti môžu robiť aj rôzni programátori.
Definícia funkcie
Definícia funkcie pozostáva z nasledujúcich častí:
- Typ návratovej hodnoty funkcie. Funkcia z úvodného príkladu napríklad vracia vzdialenosť bodov v rovine, teda hodnotu typu double. Podobne môžeme písať funkcie vracajúce iné návratové typy, napríklad int. Funkcie, ktoré nemajú vracať žiadnu hodnotu majú špeciálny návratový typ void – ide typicky o funkcie, ktoré len vykonajú určitú činnosť, napríklad vypísanie textu na konzolu a podobne.
- Identifikátor funkcie. Funkciu môžeme (v rámci určitých medzí) pomenovať prakticky ľubovoľne, rovnako ako pri premenných. Vhodné je však použiť názov, ktorý vystihuje úlohu danej funkcie (napríklad dlzka).
- Zoznam vstupných parametrov funkcie. V zátvorkách za názvom funkcie je zoznam typov a identifikátorov vstupných argumentov, ktoré funkcia očakáva. V úvodnom príklade funkcia očakáva súradnice dvoch bodov v rovine, teda štyri hodnoty typu double. Ak funkcia neočakáva žiaden vstupný argument, môžeme do zátvoriek napísať void alebo nechať zoznam argumentov prázdny.
- Telo funkcie. Do zložených zátvoriek za definíciou funkcie píšeme postupnosť príkazov, ktoré má funkcia vykonať.
- Príkaz return. Vracia návratovú hodnotu funkcie.
typ_navratovej_hodnoty identifikator_funkcie(zoznam_vstupnych_argumentov) {
telo_funkcie // Môže obsahovať príkazy return.
}
Ďalšie príklady funkcií
Súčet čísel od a po b
Ukážeme si tri verzie funkcie, ktorá dostane dvojicu celých čísel a, b a spočíta súčet všetkých celých čísel od a po b vrátane.
- Prvá verzia tento súčet vráti ako návratovú hodnotu.
- Druhá verzia súčet vypíše, vrátane sčitovaných čísel, jej návratový typ bude void.
- Tretia verzia súčet aj vypíše aj vráti.
/* Funkcia, ktora vrati sucet a + (a+1) + ... + (b-1) + b */
int sum(int a, int b) {
int result = 0;
for (int i = a; i <= b; i++) {
result += i;
}
return result;
}
/* Funkcia, ktora vypise cisla a, (a+1), ..., b a ich sucet */
void printNumbers(int a, int b) {
int result = 0;
for (int i = a; i <= b; i++) {
if (i > a) {
cout << " + ";
}
cout << i;
result += i;
}
cout << " = " << result << endl;
}
/* Funkcia, ktora vypise cisla a, (a+1), ..., b a ich sucet
* a tento sucet aj vrati. */
int sumAndPrint(int a, int b) {
int result = 0;
for (int i = a; i <= b; i++) {
if (i > a) {
cout << " + ";
}
cout << i;
result += i;
}
cout << " = " << result << endl;
return result;
}
Program využívajúci tieto funkcie môže vyzerať napríklad takto:
#include <iostream>
using namespace std;
// sem pridu definicie funkcii sum, printNUmbers, sumAndPrint
// uvedene vyssie
int main() {
int a, b;
cout << "Zadaj dvojicu celych cisel: ";
cin >> a >> b;
cout << "Test funkcie sum" << endl;
cout << "Sucet celych cisel od " << a << " po " << b << ": ";
// zavolame funkciu a vysledok priamo vypiseme
cout << sum(a, b) << endl;
// vysledok funkcie mozeme ulozit do premennej
// a pouzit neskor:
int sucet = sum(a, b);
cout << "Druha mocnina suctu cisel je: " << sucet * sucet << endl;
cout << endl << "Test funkcie printNumbers" << endl;
// tato funkcia nema vysledok, nic neukladame
printNumbers(a, b);
cout << endl << "Test funkcie sumAndPrint" << endl;
// dalsia funkcia vypise aj vrati hodnotu
int sucet2 = sumAndPrint(a, b);
cout << "Druha mocnina suctu cisel je: " << sucet2 * sucet2 << endl;
// vystupnu hodnotu funkcie mozeme aj odignorovat
sumAndPrint(a,b);
}
Fibonacciho čísla
Fibonacciho postupnosť je postupnosť čísel taká, že:
- Nultý člen je 0.
- Prvý člen je 1.
- Každý ďalší člen postupnosti je daný súčtom dvoch predchádzajúcich.
Prvých niekoľko členov Fibonacciho postupnosti je
- 0, 1, 1, 2, 3, 5, 8, 13, 21, 34, 55, 89, 144, 233, 377, 610, 987, 1597, 2584, 4181, 6765, 10946, 17711, 28657, 46368, 75025, 121393, ...
Formálnejšiu definíciu n-tého Fibonacciho čísla F(n) môžeme zapísať ako rekurentný vzťah:
- F(0) = 0,
- F(1) = 1,
- Pre všetky prirodzené čísla n ≥ 2: F(n) = F(n - 1) + F(n - 2).
Napíšeme teraz funkciu fibonacci, ktorá pre dané n vypočíta n-té Fibonnaciho číslo F(n) a použijeme ju v programe.
#include <iostream>
using namespace std;
int fibonacci(int n) {
if (n == 0) {
return 0;
} else if (n == 1) {
return 1;
} else {
int F_posledne = 1;
int F_predposledne = 0;
for (int i = 2; i <= n; i++) {
int F_n = F_posledne + F_predposledne;
F_predposledne = F_posledne;
F_posledne = F_n;
}
return F_posledne;
}
}
int main() {
int n;
cout << "Zadaj n: ";
cin >> n;
cout << "F(" << n << ") = " << fibonacci(n) << endl;
}
Príklad behu programu:
Zadaj n: 9 F(9) = 34
Cvičenie: Napíšte funkciu printFibonacci, ktorá vypíše prvých n Fibonacciho čísel.
- Akú bude mať táto funkcia hlavičku?
- Vyskúšajte dva spôsoby implementácie: volaním funkcie fibonacci pre rôzne hodnoty n a prepísaním tejto funkcie, aby sa hodnoty vypisovali priamo počas ich výpočtu. Ktorý spôsob bude rýchlejší pre veľké n a prečo?
Príkaz return
Pozrime sa teraz bližšie na špeciálny príkaz return:
- Po vykonaní príkazu return je funkcia okamžite zastavená a jej výstupná hodnota je výraz za slovom return.
- Funkcia môže obsahovať aj viacero volaní return. Akonáhle sa však jedno z nich vykoná, funkcia končí s danou návratovou hodnotou. Napríklad:
#include <iostream>
using namespace std;
int f(void) {
return 1;
return 2; // Nikdy sa nevykona.
return 3; // Nikdy sa nevykona.
}
int main() {
cout << f() << endl; // Vypise 1.
}
- Funkcia s návratovým typom void môže tiež obsahovať príkaz return, avšak bez návratovej hodnoty.
- V takom prípade return slúži iba na ukončenie vykonávania funkcie, väčšinou je lepšie prepísať inak
- Tu je ukážka, kde namiesto return by bolo lepšie použiť else:
#include <iostream>
using namespace std;
void akeCislo(int n) {
if (n >= 0) {
cout << "Cislo je nezaporne." << endl;
return;
}
// Vykona sa len v pripade n < 0:
cout << "Cislo je zaporne." << endl;
}
int main() {
int n;
cin >> n;
akeCislo(n);
}
- Napríklad minimum z dvoch čísel môžeme vypočítať dvoma rôznymi spôsobmi:
int minimum1(int a, int b) {
int minval;
if (a < b) {
minval = a;
} else {
minval = b;
}
return minval;
}
int minimum2(int a, int b) {
if (a < b) {
return a;
} else {
return b;
}
}
- Funkcie s návratovým typom iným ako void je žiadúce písať tak, aby na ľubovoľnom vstupe ich vykonávanie vždy skončilo príkazom return.
- Ak totiž takáto funkcia skončí inak, než príkazom return, jej výstupná hodnota je nedefinovaná (použije sa „hocijaký nezmysel”), čo môže viesť k zákerným chybám.
Cvičenie: Nájdite hodnotu nasledujúcej funkcie pre n=6 a n=7. Viete stručne popísať, čo funkcia robí pre všeobecné n?
int zahada(int n) {
for (int i = 2; i * i <= n; i++) {
if (n % i == 0) {
return i;
}
}
return n;
}
Lokálne a globálne premenné
Premenné v C/C++ možno rozdeliť na globálne a lokálne:
- Globálne premenné možno používať vo všetkých funkciách, ktoré sú v programe definované za touto premennou.
- Lokálne premenné sú definované vo vnútri funkcie a môžu sa používať iba v rámci nej (alebo iba v rámci niektorej časti funkcie, ak je premenná definovaná napríklad v tele cyklu a podobne).
Platí navyše, že:
- Viaceré funkcie môžu mať lokálne premenné s tým istým názvom – každá funkcia potom používa tú svoju. Toto sa bežne používa.
- Ak má lokálna premenná rovnaký názov ako nejaká globálna premenná, lokálna premenná prekryje globálnu – funkcia teda používa svoju lokálnu premennú (bližšia košeľa ako kabát). Toto radšej nerobte, môže vzniknúť chaos.
Je silno odporúčané používať predovšetkým lokálne premenné. Väčšie programy s globálnymi premennými môžu byť veľmi neprehľadné.
Nasledujúci program obsahuje globálnu premennú x a v každej funkcii lokálnu premennú s názvom y:
#include <iostream>
using namespace std;
int x;
void f(void) {
int y = 10;
cout << x << " " << y << endl;
}
int main() {
x = 10;
int y = 20;
f(); // Vypise 10 10.
cout << x << " " << y << endl; // Vypise 10 20.
}
Parametre funkcií
Odovzdávanie parametrov hodnotou
Vstupné parametre funkcií sa správajú ako lokálne premenné danej funkcie. Pri volaní funkcie sa každému parametru priradí určitá hodnota. Uvažujme napríklad funkciu
void f(int a, int b) {
// ...
}
Pri volaní
f(1,2);
sa parametru a priradí hodnota 1 a parametru b sa priradí hodnota 2. Tieto sa ďalej správajú ako lokálne premenné funkcie f. Možno ich teda meniť, ale táto zmena sa neprejaví na mieste, odkiaľ funkciu voláme. Tento mechanizmus nazývame odovzdávaním parametrov hodnotou.
Príklad:
#include <iostream>
using namespace std;
void f(int n) {
n++;
cout << n << endl;
}
int main() {
int n = 1;
f(n); // Vypise 2
cout << n << endl; // Vypise 1
}
Odovzdávanie parametrov referenciou
V prípade, že pred názov niektorého parametra v hlavičke funkcie napíšeme &, parameter sa bude odovzdávať referenciou.
- Za takýto parameter možno pri volaní funkcie dosadiť iba premennú (kým pri odovzdávaní hodnotou môžeme použiť napríklad aj konštanty alebo iný výraz).
- Namiesto hodnoty sa funkcii pošle adresa premennej v pamäti (referencia).
- Funkcia potom bude túto premennú používať pod novým názvom; jej prípadné zmeny sa prejavia aj na mieste, odkiaľ bola funkcia volaná.
Príklad:
#include <iostream>
using namespace std;
void f(int &n) {
n++;
cout << n << endl;
}
int main() {
int n = 1;
f(n); // Vypise 2.
cout << n << endl; // Vypise 2.
}
Ďalej si ukážeme niekoľko použití odovzdávania parametrov referenciou.
Viac ako jedna návratová hodnota
Odovzdávanie parametra referenciou používame napríklad vtedy, keď potrebujeme vrátiť viac ako jednu výstupnú hodnotu.
Napríklad nasledujúca funkcia stred dostane súradnice dvoch bodov [x1,y1] a [x2,y2] a do parametrov [xm,ym], ktoré sú odovzdané referenciou, uloží súradnice stredu úsečky spájajúcej body [x1,y1] a [x2,y2].
#include <iostream>
using namespace std;
void stred(double x1, double y1, double x2, double y2,
double &xm, double &ym) {
xm = (x1 + x2) / 2;
ym = (y1 + y2) / 2;
}
int main() {
double Ax, Ay, Bx, By;
cout << "Zadaj suradnice bodu A: ";
cin >> Ax >> Ay;
cout << "Zadaj suradnice bodu B: ";
cin >> Bx >> By;
double Mx, My;
stred(Ax, Ay, Bx, By, Mx, My);
cout << "Stred usecky AB je ["
<< Mx << ", " << My << "]." << endl;
}
Funkcia swap
Typickým príkladom použitia odovzdávania parametrov referenciou je funkcia swap, ktorá vymení hodnoty dvoch premenných, ktoré dostane ako parametre.
#include <iostream>
using namespace std;
void swap(int &a, int &b) {
int tmp = a;
a = b;
b = tmp;
}
int main() {
int x, y;
cin >> x >> y;
swap(x, y);
cout << "x = " << x << ", y = " << y << endl;
}
Keby sme funkcii odovzdali parameter hodnotou – čiže by sme funkciu swap definovali s hlavičkou void swap(int a, int b); – vo funkcii main by sa premenné nevymenili.
Ošetrovanie chybných vstupov
Občas môže nastať potreba, aby parametre funkcie spĺňali určité podmienky. V takom prípade môže byť potrebné korektne sa vysporiadať aj so vstupmi, ktoré tieto podmienky nespĺňajú. Ukážeme si teraz zopár možných prístupov k tomuto problému.
Funkcia neošetrujúca chybné vstupy
Uvažujme napríklad nasledujúcu funkciu, ktorá počíta súčet všetkých deliteľov čísla n. Jej základným predpokladom je, že n je kladné celé číslo.
#include <iostream>
using namespace std;
int sumOfDivisors(int n) {
int sum = 0;
for (int i = 1; i <= n; i++) {
if (n % i == 0) {
sum += i;
}
}
return sum;
}
int main() {
int n;
cout << "Zadaj kladne cele cislo: ";
cin >> n;
cout << "Sucet delitelov " << n << ": "
<< sumOfDivisors(n) << "." << endl;
}
Ak však používateľ zadá na vstupe nejaké záporné číslo, funkcia vždy vráti nulu, čo nie je úplne v súlade s očakávaním. Jednou možnosťou by samozrejme bolo prerobiť funkciu tak, aby pracovala správne aj na záporných vstupoch. Sú však aj situácie, keď podobné riešenie nie je možné. Ukážeme si preto ďalšie spôsoby, ako sa s nekorektným vstupom vysporiadať.
Použitie funkcie assert
V prípade použitia nekorektného vstupu napríklad môžeme celý program ihneď ukončiť. Pohodlný spôsob, ako to spraviť, je použitie funkcie assert (treba #include <cassert>). Táto funkcia kontroluje platnosť nejakej podmienky. Ak je táto podmienka splnená, program normálne pokračuje; v opačnom prípade sa program zastaví s chybovou hláškou. Argumentom funkcie assert môže byť ľubovoľná booleovská hodnota.
#include <iostream>
#include <cassert>
using namespace std;
int sumOfDivisors(int n) {
assert(n > 0);
int sum = 0;
for (int i = 1; i <= n; i++) {
if (n % i == 0) {
sum += i;
}
}
return sum;
}
int main() {
int n;
cout << "Zadaj kladne cele cislo: ";
cin >> n;
cout << "Sucet delitelov " << n << ": "
<< sumOfDivisors(n) << "." << endl;
}
Úspech výpočtu ako výstupná hodnota
Často je ale neprípustné v prípade jediného volania funkcie s nekorektnými vstupmi ukončiť celý program. Chceli by sme teda vrátiť dve hodnoty: samotný súčet deliteľov a indikátor, či boli argumenty zadané správne.
- Napríklad súčet deliteľov môžeme ukladať do parametra odovzdávaného referenciou.
- Výstupom funkcie bude booleovská hodnota, ktorá bude true práve vtedy, keď výpočet funkcie prebehol správne (t.j. keď boli zadané správne argumenty). Túto výstupnú hodnotu je potom možné použiť pri volaní funkcie ako známku toho, že hodnota v parametre predanom referenciou je zmysluplná.
#include <iostream>
using namespace std;
bool sumOfDivisors(int n, int &sum) {
if (n <= 0) {
return false;
} else {
sum = 0;
for (int i = 1; i <= n; i++) {
if (n % i == 0) {
sum += i;
}
}
return true;
}
}
int main() {
int n, sum;
cout << "Zadaj kladne cele cislo: ";
cin >> n;
if (sumOfDivisors(n, sum)) {
cout << "Sucet delitelov " << n << ": "
<< sum << "." << endl;
} else {
cout << "Zly vstup" << endl;
}
}
Programy s viacerými funkciami
V programe možno volať iba funkcie, ktoré už predtým boli niekde definované.
Tento program typicky neskompiluje (vo vnútri f1 ešte nepozná f2)
void f1(void) {
f2();
}
void f2(void) {
cout << "Hello, World!" << endl;
}
Tento program je v poriadku:
void f2(void) {
cout << "Hello, World!" << endl;
}
void f1(void) {
f2();
}
Funkcia main
Špeciálnou funkciou je v C/C++ funkcia main.
- V programe ju nemožno volať – jediné jej volanie je automatické (začína sa ním beh programu).
- Výstupná hodnota funkcie main sa interpretuje ako „spôsob ukončenia” programu (napríklad 0 pre korektné ukončenie, iné hodnoty pre chyby).
- Funkciu main môžeme teda ukončit napríklad príkazom return 0.
- Funkcia main môže mať aj určité presne špecifikované parametre (viac o tom neskôr).
Funkcie: zhrnutie
- Funkcie nám umožňujú rozbiť väčší program na menšie logické časti a tým ho sprehľadniť. Tiež nám umožňujú vyhnúť sa opakovaniu podobných kusov kódu.
- Hlavička funkcie obsahuje návratový typ (môže byť void), meno funkcie, typy a mená parametrov.
- V tele funkcie sú samotné príkazy. Vypočítanú hodnotu vrátime príkazom return.
- Lokálne premenné sú viditeľné len vo funkcii, ktorá ich definuje, globálne vo všetkých funkciách.
- Parametre odovzdávané hodnotou sú lokálne premenné inicializované hodnotami, ktoré sa zadajú pri volaní funkcie.
- Parametre odovzdávané referenciou (&) sú len novým menom pre inú premennú.
Prednáška 4b
Oznamy
Program na dnes:
- oznamy
- teoretické cvičenie (krátky test)
- vzorové riešenia testu
- dokončenie minulej prednášky
Čo nás čaká v najbližších dňoch
- zajtra hlavné cvičenia, rozcvička na funkcie (pozrite si pred cvičením)
- v stredu prednáška o poliach
- v stredu bude zverejnené zadanie prvej domácej úlohy
- v piatok doplnkové cvičenia
Dnešné teoretické cvičenie
- krátky bodovaný testík, počíta sa do cvičení (spolu 4 body, cca 1% známky)
- ciele: zopakovať si učivo, rozmýšľať nad hotovými programami bez kompilovania a spúšťania programu, tréning na semestrálny test
- môžete používať pero a ťahák vo forme jedného obojstranne popísaného listu A4
Opakovanie
Funkcia je samostatný kus kódu (postupnosť príkazov) s určitým menom. Po zavolaní funkcie jej menom sa daná postupnosť príkazov vykoná.
- Umožňujú vytvoriť „skratku” pre často používané časti kódu, ktoré tak nie je nutné zakaždým písať nanovo.
Definícia funkcie pozostáva z nasledujúcich častí:
- Typ návratovej hodnoty funkcie (napríklad double, int, void)
- Identifikátor funkcie (použite výstižný názov)
- Zoznam vstupných parametrov funkcie a ich typov
- Telo funkcie (príkazy v { })
- Príkaz return vracia návratovú hodnotu funkcie a ukončí jej beh
Platnosť lokálnych premenných je obmedzená na funkciu (alebo blok) v ktorej boli zadefinované. Globálne premenné je možné používať vo všetkých funkciách, zvyčajne sa chceme ich použitiu vyhnúť.
Odovzdávanie parametrov
- Hodnotou: parametre sa nakopírujú, ďalej fungujú ako lokálne premenná funkcie (napr. double x)
- Referenciou: parameter je nové meno pre premennú z volajúcej funkcie (napr. double &x)
Odovzdávanie parametrov hodnotou
Vstupné parametre funkcií sa správajú ako lokálne premenné danej funkcie. Pri volaní funkcie sa každému parametru priradí určitá hodnota. Uvažujme napríklad funkciu
void f(int a, int b) {
// ...
}
Pri volaní
f(1,2);
sa parametru a priradí hodnota 1 a parametru b sa priradí hodnota 2. Tieto sa ďalej správajú ako lokálne premenné funkcie f. Možno ich teda meniť, ale táto zmena sa neprejaví na mieste, odkiaľ funkciu voláme. Tento mechanizmus nazývame odovzdávaním parametrov hodnotou.
Príklad:
#include <iostream>
using namespace std;
void f(int n) {
n++;
cout << n << endl;
}
int main() {
int n = 1;
f(n); // Vypise 2
cout << n << endl; // Vypise 1
}
Odovzdávanie parametrov referenciou
V prípade, že pred názov niektorého parametra v hlavičke funkcie napíšeme &, parameter sa bude odovzdávať referenciou.
- Za takýto parameter možno pri volaní funkcie dosadiť iba premennú (kým pri odovzdávaní hodnotou môžeme použiť napríklad aj konštanty alebo iný výraz).
- Namiesto hodnoty sa funkcii pošle adresa premennej v pamäti (referencia).
- Funkcia potom bude túto premennú používať pod novým názvom; jej prípadné zmeny sa prejavia aj na mieste, odkiaľ bola funkcia volaná.
Príklad:
#include <iostream>
using namespace std;
void f(int &n) {
n++;
cout << n << endl;
}
int main() {
int n = 1;
f(n); // Vypise 2.
cout << n << endl; // Vypise 2.
}
Ďalej si ukážeme niekoľko použití odovzdávania parametrov referenciou.
Viac ako jedna návratová hodnota
Odovzdávanie parametra referenciou používame napríklad vtedy, keď potrebujeme vrátiť viac ako jednu výstupnú hodnotu.
Napríklad nasledujúca funkcia mid dostane súradnice dvoch bodov [x1,y1] a [x2,y2] a do parametrov [xm,ym], ktoré sú odovzdané referenciou, uloží súradnice stredu úsečky spájajúcej body [x1,y1] a [x2,y2].
#include <iostream>
using namespace std;
void mid(double x1, double y1, double x2, double y2,
double &xm, double &ym) {
xm = (x1 + x2) / 2;
ym = (y1 + y2) / 2;
}
int main() {
double Ax, Ay, Bx, By;
cout << "Zadaj suradnice bodu A: ";
cin >> Ax >> Ay;
cout << "Zadaj suradnice bodu B: ";
cin >> Bx >> By;
double Mx, My;
mid(Ax, Ay, Bx, By, Mx, My);
cout << "Stred usecky AB je ["
<< Mx << ", " << My << "]." << endl;
}
Funkcia swap
Typickým príkladom použitia odovzdávania parametrov referenciou je funkcia swap, ktorá vymení hodnoty dvoch premenných, ktoré dostane ako parametre.
#include <iostream>
using namespace std;
void swap(int &a, int &b) {
int tmp = a;
a = b;
b = tmp;
}
int main() {
int x, y;
cin >> x >> y;
swap(x, y);
cout << "x = " << x << ", y = " << y << endl;
}
Keby sme funkcii odovzdali parameter hodnotou – čiže by sme funkciu swap definovali s hlavičkou void swap(int a, int b); – vo funkcii main by sa premenné nevymenili.
Ošetrovanie chybných vstupov
Občas môže nastať potreba, aby parametre funkcie spĺňali určité podmienky. V takom prípade môže byť potrebné korektne sa vysporiadať aj so vstupmi, ktoré tieto podmienky nespĺňajú. Ukážeme si teraz zopár možných prístupov k tomuto problému.
Funkcia neošetrujúca chybné vstupy
Uvažujme napríklad nasledujúcu funkciu, ktorá počíta súčet všetkých deliteľov čísla n. Jej základným predpokladom je, že n je kladné celé číslo.
#include <iostream>
using namespace std;
int sumOfDivisors(int n) {
int sum = 0;
for (int i = 1; i <= n; i++) {
if (n % i == 0) {
sum += i;
}
}
return sum;
}
int main() {
int n;
cout << "Zadaj kladne cele cislo: ";
cin >> n;
cout << "Sucet delitelov " << n << ": "
<< sumOfDivisors(n) << "." << endl;
}
Ak však používateľ zadá na vstupe nejaké záporné číslo, funkcia vždy vráti nulu, čo nie je úplne v súlade s očakávaním. Jednou možnosťou by samozrejme bolo prerobiť funkciu tak, aby pracovala správne aj na záporných vstupoch. Sú však aj situácie, keď podobné riešenie nie je možné. Ukážeme si preto ďalšie spôsoby, ako sa s nekorektným vstupom vysporiadať.
Použitie funkcie exit
V prípade použitia nekorektného vstupu napríklad môžeme celý program ihneď ukončiť funkciou exit (treba #include <cstdlib>).
- Parametrom tejto funkcie je návratová hodnota celého programu, ktorá typicky udáva, či program skončil korektne alebo nie.
- Na vyjadrenie neúspešného ukončenia programu použijeme preddefinovanú konštantu EXIT_FAILURE.
#include <iostream>
#include <cstdlib>
using namespace std;
int sumOfDivisors(int n) {
if (n <= 0) {
exit(EXIT_FAILURE);
}
int sum = 0;
for (int i = 1; i <= n; i++) {
if (n % i == 0) {
sum += i;
}
}
return sum;
}
int main() {
int n;
cout << "Zadaj kladne cele cislo: ";
cin >> n;
cout << "Sucet delitelov " << n << ": "
<< sumOfDivisors(n) << "." << endl;
}
Použitie funkcie assert
Pohodlnejšou alternatívou je použitie funkcie assert (treba #include <cassert>). Táto funkcia umožňuje predpokladať platnosť nejakej podmienky – ak je táto podmienka splnená, program normálne pokračuje; v opačnom prípade sa program zastaví s chybovou hláškou. Argumentom funkcie assert môže byť ľubovoľná booleovská hodnota.
#include <iostream>
#include <cassert>
using namespace std;
int sumOfDivisors(int n) {
assert(n > 0);
int sum = 0;
for (int i = 1; i <= n; i++) {
if (n % i == 0) {
sum += i;
}
}
return sum;
}
int main() {
int n;
cout << "Zadaj kladne cele cislo: ";
cin >> n;
cout << "Sucet delitelov " << n << ": "
<< sumOfDivisors(n) << "." << endl;
}
Úspech výpočtu ako výstupná hodnota
Často je ale neprípustné v prípade jediného volania funkcie s nekorektnými vstupmi ukončiť celý program. Chceli by sme teda vrátiť dve hodnoty: samotný súčet deliteľov a indikátor, či boli argumenty zadané správne.
- Napríklad súčet deliteľov môžeme ukladať do parametra odovzdávaného referenciou.
- Výstupom funkcie bude booleovská hodnota, ktorá bude true práve vtedy, keď výpočet funkcie prebehol správne (t.j. keď boli zadané správne argumenty). Túto výstupnú hodnotu je potom možné použiť pri volaní funkcie ako známku toho, že hodnota v parametre predanom referenciou je zmysluplná.
#include <iostream>
using namespace std;
bool sumOfDivisors(int n, int &sum) {
if (n <= 0) {
return false;
} else {
sum = 0;
for (int i = 1; i <= n; i++) {
if (n % i == 0) {
sum += i;
}
}
return true;
}
}
int main() {
int n, sum;
cout << "Zadaj kladne cele cislo: ";
cin >> n;
if (sumOfDivisors(n, sum)) {
cout << "Sucet delitelov " << n << ": "
<< sum << "." << endl;
} else {
cout << "Zly vstup" << endl;
}
}
Programy s viacerými funkciami
V programe možno volať iba funkcie, ktoré už predtým boli niekde definované alebo aspoň deklarované (tento pojem si ozrejmíme o chvíľu).
Tento program typicky neskompiluje (vo vnútri f1 ešte nepozná f2)
void f1(void) {
f2();
}
void f2(void) {
cout << "Hello, World!" << endl;
}
Tento program je v poriadku:
void f2(void) {
cout << "Hello, World!" << endl;
}
void f1(void) {
f2();
}
Program tiež skompiluje v prípade, že každú funkciu pred jej volaním aspoň zadeklarujeme – t.j. uvedieme jej hlavičku bez definície jej tela – a samotnú definíciu funkcie uvedieme až neskôr. V poriadku je teda napríklad aj nasledujúci program:
void f2(void);
void f1(void) {
f2();
}
void f2(void) {
cout << "Hello, World!" << endl;
}
Funkcia main
Špeciálnou funkciou je v C/C++ funkcia main. Od ostatných funkcií sa odlišuje v nasledujúcom:
- V programe ju nemožno volať – jediné jej volanie je automatické (začína sa ním beh programu).
- Výstupná hodnota funkcie main sa interpretuje ako „spôsob ukončenia” programu (napríklad 0 pre korektné ukončenie, iné hodnoty pre chyby).
- Funkciu main môžeme teda ukončit napríklad príkazom return 0.
- Funkcia main môže mať aj určité presne špecifikované parametre (viac o tom neskôr).
Prednáška 5
Oznamy
- Dokončenie predchádzajúcej prednášky (funkcie).
- Príďte na doplnkové cvičenia, ak sa vám včera nepodarilo vyriešiť veľa príkladov. Pomôžeme vám s ďalšími príkladmi na tento týždeň
- Dnes polia, budúci pondelok hlavne ďalšie príklady a algoritmy s použitím tých častí Cčka, ktoré už poznáte
Hľadanie chýb v programe
- Väčšina programov nefunguje na prvý krát, hľadanie chýb patrí medzi základné činnosti programátora
- Podobné chyby sa často opakujú, tréningom sa ich naučíte nájsť rýchlejšie
Ak program ani neskompiluje
- Kompilátor vypíše číslo riadku s chybou, čo vám ju môže pomôcť nájsť
- Občas je však chyba trochu inde, napr. niečo chýba o riadok vyššie
- Pokročilejšie postredia, ako napr. Netbeans, vám vedia ukázať polohu chyby
- Ak kompilátor vypíše veľa chýb, opravte najskôr prvú, potom skompilujte znovu, ďalšie chyby môžu byť len dôsledkom prvej
- Ak neviete nájsť chybu pri kompilácii, skúste zakomentovať nejaké časti programu pomocou /* */, aby ste zúžili priestor, kde chyba môže byť
- Aj varovania kompilátora môžu poukazovať na chybu v programe
Ak program dáva zlé výsledky, "cyklí sa" alebo "padá"
- Môžete skúsiť program znovu prečítať, či nezbadáte chybu
- Pomáha dobrá čitateľnosť programov
- Alebo experimentami zistiť, kde sa jeho správanie prvýkrát začne odlišovať od toho, čo očakávate
- To sa dá robiť spúšťaním programu po krokoch v nástroji nazvanom debugger (nachádza sa napr. v Netbeans)
- Alternatíva k debuggeru je do programu pridať pomocné výpisy, ktoré vám prezradia, ktorá časť programu sa práve vykonáva a aké sú hodnoty dôležitých premenných
- Po nájdení chyby treba tieto pomocné výpisy odstrániť. Pozor, aby ste tým nespravili ďalšiu chybu
- Debugger alebo výpisy vám pomôžu nájsť chybu iba vtedy, ak máte predstavu o tom, ako by program mal fungovať a hľadáte, kde sa od nej skutočné správanie líši
- Pomáha vyrobiť si čo najmenší vstup, kde je zlý výsledok
Záznam typu struct
V príkladoch s obvodom trojuholníka a stredom úsečky sme funkciám posielali veľa parametrov (súradnice x a y)
void stred(double x1, double y1, double x2, double y2, double &xm, double &ym) {
xm = (x1 + x2) / 2;
ym = (y1 + y2) / 2;
}
Program bude krajší, ak si údaje o jednom bode spojíme do jedného záznamu
struct bod {
double x, y;
};
- Pomocou struct vytvoríme nový dátový typ bod, ktorý má zložky x a y
- V jednom struct-e môžu byť aj položky rôznych typov, napr.
struct bod {
double x,y;
int id;
bool visible;
};
- Môžeme vytvárať premenné typu bod, napr. bod a, b;
- K položkám bodu pristupujeme pomocou bodky, napr. a.x = 4.0;
- Do funkcií body posielame radšej referenciou, aby sa zbytočne nekopírovalo veľa hodnôt
Nasledujúci program načíta súradnice troch bodov, spočíta obvod trojuholníka a stredy všetkých troch strán.
#include <iostream>
#include <cmath>
using namespace std;
struct bod {
double x, y; // suradnice bodu v rovine
};
double dlzka(bod &bod1, bod &bod2) {
// funkcia vrati dlzku usecky z bodu 1 do bodu 2
double dx = bod1.x - bod2.x;
double dy = bod1.y - bod2.y;
return sqrt(dx * dx + dy * dy);
}
void stred(bod &bod1, bod &bod2, bod &stred) {
// funkcia do bodu stred spocita stred usecky z bodu 1 do bodu 2
stred.x = (bod1.x + bod2.x) / 2;
stred.y = (bod1.y + bod2.y) / 2;
}
void vypisBod(bod &b) {
// funkcia vypise suradnice bodu v zatvorke a koniec riadku
cout << "(" << b.x << "," << b.y << ")" << endl;
}
int main() {
// nacitame suradnice vrcholov trojuholnika
bod A, B, C;
cout << "Zadaj suradnice vrcholu A oddelene medzerou: ";
cin >> A.x >> A.y;
cout << "Zadaj suradnice vrcholu B oddelene medzerou: ";
cin >> B.x >> B.y;
cout << "Zadaj suradnice vrcholu C oddelene medzerou: ";
cin >> C.x >> C.y;Teacher
// spocitame dlzky stran
double da = dlzka(B, C);
double db = dlzka(A, C);
double dc = dlzka(A, B);
// vypiseme obvod
cout << "Obvod trojuholnika ABC: " << da + db + dc << endl;
// spocitame stredy stran
bod stredAB;
stred(A, B, stredAB);
bod stredAC;
stred(A, C, stredAC);
bod stredBC;
stred(B, C, stredBC);
// vypiseme stredy stran
cout << "Stred strany AB: ";
vypisBod(stredAB);
cout << "Stred strany AC: ";
vypisBod(stredAC);
cout << "Stred strany BC: ";
vypisBod(stredBC);
}
Príklad behu programu:
Zadaj suradnice vrcholu A oddelene medzerou: 0 0 Zadaj suradnice vrcholu B oddelene medzerou: 0 3 Zadaj suradnice vrcholu C oddelene medzerou: 4 0 Obvod trojuholnika ABC: 12 Stred strany AB: (0,1.5) Stred strany AC: (2,0) Stred strany BC: (2,1.5)
Spracovanie väčšieho množstva dát
Naše programy doteraz spracovávali len malý počet vstupných dát načítaných od užívateľa (napr. súradnice troch bodov). Často však chceme pracovať s väčším množstvom dát
- Dnes si ukážeme, ako uložiť väčšie množstvo dát do poľa
- Na niektoré úlohy však pole nepotrebujeme - údaje môžeme spracovávať rovno ako ich užívateľ zadáva (takéto príklady sme už videli na cvičeniach)
V nasledujúcich príkladoch užívateľ zadá číslo N a potom N celých čísel
- Predstavme si napríklad, že učiteľ zadá body, ktoré študenti dostali na písomke (napr. celé čísla v rozsahu 0..10)
- Z týchto bodov chceme spočítať nejaké štatistiky
Priemer
#include <iostream>
using namespace std;
int main() {
int N;
cout << "Zadaj pocet cisel: ";
cin >> N;
int sucet = 0;
cout << "Zadavaj cisla: ";
for (int i = 0; i < N; i++) {
int x;
cin >> x;
sucet += x;
}
double priemer = sucet / (double) N;
cout << "Priemer je " << priemer << "." << endl;
}
- Čo by sa stalo, keby sme vo výpočte priemeru vynechali (double)?
Maximum
#include <iostream>
using namespace std;
int main() {
int max, x, N;
cout << "Zadaj pocet cisel: ";
cin >> N;
cout << "Zadavajte cisla: ";
max = ?
for (int i = 0; i < N; i++) {
cin >> x;
if (x > max) {
max = x;
}
}
cout << endl << "Maximum je " << max << endl;
}
Ako ale začať? Ako nastaviť maximum na začiatok?
- Jedna možnosť je nastaviť ho na nejakú veľmi malú hodnotu, aby sa iste neskôr zmenila. Ale čo ak používateľ dá všetky čísla ešte menšie?
- Riešením je použiť najmenšie možné číslo. Ale to je príliš viazané na konkrétny rozsah, nebude fungovať po zmene typu premenných.
- Ďalšia možnosť je si pamätať, že ešte nemáme správne nastavené maximum a po načítaní prvého čísla ho nastaviť alebo spracovať prvé číslo zvlášť (mimo cyklu).
#include <iostream>
using namespace std;
int main() {
int max, x, N;
cout << "Zadaj pocet cisel: ";
cin >> N;
cout << "Zadavajte cisla: ";
cin >> x; // načítanie prvého čísla
max = x;
for (int i = 1; i < N; i++) { // cyklus cez N-1 ďalších čísel
cin >> x;
if (x > max) {
max = x;
}
}
cout << endl << "Maximum je " << max << endl;
}
Cvičenie:
- Ako by sme program rozšírili tak, aby vedel vypísať aj koľké číslo v poradí bolo najväčšie?
- Čo treba v programe zmeniť, ak chceme hľadať minimum namiesto maxima?
- Spočítajte, koľkokrát sa na vstupe vyskytuje číslo 0
Prvé použitie poľa: podpriemer / nadpriemer
Chceme spočítať priemer a o každom vstupnom čísle vypísať, či je nadpriemerné alebo podpriemerné.
- Priemer vieme až keď načítame všetky čísla, musíme si ich teda zapamätať
- Na to používame tabuľky, ktoré sa volajú polia.
- Na začiatok pre jednoduchosť predpokladajme, že vopred vieme, že počet údajov N je napr. 20 (N teda nenačítavame)
- Príkaz int a[20]; vytvorí pole s 20 premennými typu int, ku ktorým pristupujeme a[0], a[1], ..., a[19]
- pozor, a[20] neexistuje
#include <iostream>
using namespace std;
int main() {
const int N = 20; // premennu N uz nebude mozne menit, ma konstantnu hodnotu 20
int a[N];
double sucet = 0;
cout << "Zadavajte " << N << " cisel: ";
for (int i = 0; i < N; i++) {
cin >> a[i];
sucet += a[i];
}
double priemer = sucet / N;
cout << "Priemer je " << priemer << "." << endl;
for (int i = 0; i < N; i++) {
if (a[i] > priemer) {
cout << a[i] << ": vacsie ako priemer." << endl;
} else if (a[i] < priemer) {
cout << a[i] << ": mensie ako priemer." << endl;
} else {
cout << a[i] << ": priemer." << endl;
}
}
}
Na zamyslenie:
- Pozor, chyby pri zaokrúhľovaní môžu spôsobiť, že niekedy priemerné číslo bude považované za nad/podpriemerné
- Vedeli by ste program prerobiť tak, aby používal iba premenné typu int a nerobil žiadnu chybu v zaokrúhľovaní?
- Môže aj po takejto zmene niekedy dať zlú odpoveď?
Polia
Rozsah poľa je konštantný výraz väčší ako 0. Prvky sa indexujú od 0 po počet - 1
int a[10];
const int N=20;
double b[N];
Ak nepoznáme vopred počet prvkov, ktoré chceme dať do poľa, môžeme odhadnúť, že ich nebude viac ako NMax, ktoré definujeme ako konštantu v programe.
- Vytvoríme pole veľkosti NMax, použijeme z neho len prých N hodnôt
#include <iostream>
using namespace std;
int main() {
const int NMax = 1000;
int p[NMax];
int N;
cout << "Zadaj pocet cisel: ";
cin >> N;
if (N > NMax) {
cout << "Prilis velke N" << endl;
return 1; // ukončíme funkciu main a tým aj program
}
cout << "Zadavajte " << N << " cisel: ";
...
Čo ak ako veľkosť poľa použijeme premennú N, ktorú si prečítame od používateľa alebo inak spočítame za behu?
int N;
cout << "Zadaj pocet cisel: ";
cin >> N;
int p[N];
- V starších verziách C resp. C++ to nefunguje, aj keď niektoré novšie kompilátory to zvládajú
- Na prednáškach tento spôsob nebudeme používať
- Pole veľkosti N, ktorá nie je konštanta, sa naučíme vytvárať inak v druhej polovici semestra
Vytvorenie a inicializácia poľa
V definícii môžeme pole inicializovať zoznamom prvkov.
// spravne: inicializacia zoznamom
int A[4] = {3, 6, 8, 10};
// spravne: definicia bez inicializacie
int B[4];
// nespravne, pole tu nedefinujeme:
// B[4] = {3, 6, 8, 10};
// spravne - menime prvky existujuceho pola:
B[0] = 3; B[1] = 6; B[2] = 8; B[3] = 10;
Indexovanie hodnotou mimo intervalu
Pozor, kompilátor nekontroluje indexy prvkov
int a[10];
a[10] = 1234;
- Skompiluje, ale hodnota 1234 sa zapíše do pamäti na zlé miesto
- Môže to mať nepredvídateľné následky: prepísanie obsahu iných premenných (chybný výpočet alebo „nevysvetliteľné“ správanie sa programu) alebo dokonca prepísanie časti kódu vášho programu
Kopírovanie a testovanie rovnosti
V prípade, že chceme vytvoriť pole, ktoré je kópiou už existujúceho poľa, ponúka sa možnosť príkazu priradenia b=a;. Takýto príkaz však neskompiluje – nedá sa takto priraďovať, treba kopírovať prvok po prvku.
for (int i=0; i < 10; i++) {
b[i] = a[i];
}
Polia sa tiež nedajú porovnávať pomocou operátora ==. Podmienku if (a==b) { cout << "rovnake"; }. síce skompilujete, ale nikdy to nebude pravda – neporovná sa obsah poľa, ale niečo úplne iné (adresy polí v pamäti). Treba opäť porovnávať prvok po prvku.
bool rovne = true;
for (int i = 0; i < 10; i++) {
rovne = rovne && a[i] == b[i];
}
if (rovne) {
cout << "Rovnaju sa" << endl;
}
Ten istý kúsok programu môžeme napísať napr. aj takto:
bool rovne = true;
for (int i = 0; i < 10; i++) {
if(a[i] != b[i]) {
rovne = false;
break;
}
}
if (rovne) {
cout << "Rovnaju sa" << endl;
}
Výskyty čísel 0...9
Na vstupe je číslo N a N celých čísel od 0 do 9 a chceme vedieť, koľkokrát sa jednotlivé čísla na vstupe vyskytli.
Prvý prístup:
- vstupné čísla uložíme do poľa
- pre každú hodnotu i od 0 po 9 prejdeme pole a spočítame počet výskytov i
Druhý prístup:
- samotné vstupné čísla neukladáme do poľa, spracovávame ich po jednom
- vytvoríme si pole počítadiel dĺžky 10, v ktorom p[i] bude počet výskytov čísla i
#include <iostream>
using namespace std;
int main() {
int p[10]; // pole dlzky 10
int N;
cout << "Zadajte pocet cisel: ";
cin >> N;
for (int i = 0; i < 10; i++) {
p[i] = 0; // inicializácia poľa p[0]=0; p[1]=0; ... p[9]=0;
}
cout << "Zadavajte " << N << "cisel z intervalu 0-9: ";
for (int i = 0; i < N; i++) {
int x;
cin >> x;
if (x >= 0 && x < 10) { // test, či je číslo z požadovaného rozsahu
p[x]++; // zvýšime počítadlo pre hodnotu x
}
}
cout << endl;
for (int i = 0; i < 10; i++) {
cout << "Pocet vyskytov " << i << " je " << p[i] << endl; // výpis
}
}
Odbočka: grafická knižnica SVGdraw

- Aplikácie s grafickým rozhraním budeme programovať až budúci semester
- V tomto semestri, ale budeme kresliť obrázky v SVG formáte pomocou jednoduchej knižnice #SVGdraw
- Knižnicu si stiahnite a nainštalujte podľa návodu
- Na začiatku programu zapnite knižnicu pomocou #include "SVGdraw.h"
- Tu je malý ukážkový program, ktorý vykreslí zelený štvorec a v ňom červený kruh:
#include "SVGdraw.h"
int main() {
/* Vytvor obrázok s šírkou 150 a výškou 100 a
* ulož ho do súboru stvorec.svg*/
SVGdraw drawing(150, 100, "stvorec.svg");
/* Nastav farbu vyfarbovania na zelenú. */
drawing.setFillColor("green");
/* Vykresli štvorec s ľavým horným
* rohom v bode (20,10)
* a s dĺžkou strany 80,
* t.j. pravým dolným rohom 100,90 */
drawing.drawRectangle(20,10,80,80);
/* Nastav farbu vyfarbovania na červenú */
drawing.setFillColor("red");
/* Vykresli kruh so stredom
* v bode (60,50) a polomerom 40. */
drawing.drawEllipse(60,50,40,40);
/* Ukonči vypisovanie obrázka. */
drawing.finish();
}
Kreslíme kruhy

Nasledujúci program náhodne vygeneruje súradnice niekoľkých kruhov a vykreslí ich pomocou knižnice SVGdraw.
- Údaje o jednom kruhu si uloží do záznamu struct kruh, v programe používame pole takýchto kruhov.
- Navyše o každom kruhu zistí, či sa pretína s iným kruhom, a ak áno, pri vykresľovaní ho orámuje červenou farbou.
#include "SVGdraw.h"
#include <cstdlib>
#include <ctime>
#include <cmath>
struct kruh {
int x, y; /* suradnice stredu */
int polomer; /* polomer kruhu */
bool pretinaSa; /* pretína sa s iným? */
};
void generujKruh(kruh &k, int velkost, int polomer) {
/* inicializuj kruh s nahodnou polohou
* a danym polomerom */
k.x = rand() % (velkost - 2 * polomer)
+ polomer;
k.y = rand() % (velkost - 2 * polomer)
+ polomer;
k.polomer = polomer;
}
bool pretinajuSa(kruh &k1, kruh &k2) {
/* zisti, ci sa dva kruhy pretinaju */
int dx = k1.x - k2.x;
int dy = k1.y - k2.y;
double d2 = sqrt(dx * dx + dy * dy);
return d2 <= k1.polomer + k2.polomer;
}
int main() {
const int pocet = 10; /* počet kruhov */
const int velkost = 300; /* veľkosť obrázku */
const int polomer = 15; /* polomer kruhu */
/* inicializácia generátora
* pseudonáhodných čísel */
srand(time(NULL));
/* inicializácia obrázku */
SVGdraw drawing(velkost, velkost, "kruhy.svg");
/* pole kruhov */
kruh kruhy[pocet];
for (int i = 0; i < pocet; i++) {
/* kazdemu kruhu vygeneruj nahodnu polohu */
generujKruh(kruhy[i], velkost, polomer);
}
/* zisti, ktoré kruhy pretínajú iné kruhy */
for (int i = 0; i < pocet; i++) {
kruhy[i].pretinaSa = false;
for (int j = 0; j < pocet; j++) {
if (i != j && pretinajuSa(kruhy[i],
kruhy[j])) {
kruhy[i].pretinaSa = true;
}
}
}
/* vykresluj kruhy */
drawing.setFillColor("gray");
for (int i = 0; i < pocet; i++) {
if (kruhy[i].pretinaSa) {
drawing.setLineColor("red");
} else {
drawing.setLineColor("black");
}
drawing.drawEllipse(kruhy[i].x,
kruhy[i].y,
kruhy[i].polomer,
kruhy[i].polomer);
}
/* ukoncenie vykreslovania */
drawing.finish();
}
Polia: zhrnutie
- Pole je tabuľka hodnôt. V poli dĺžky n máme hodnoty p[0], p[1], ..., p[n-1]
- Kopírovanie a porovnávanie polí si musíme naprogramovať
- C resp. C++ nekontrolujú, či index nie je mimo rozsahu poľa
Ďalšie príklady na prácu s poľom
- Načítajte pole čísel a vypíšte ho v opačnom poradí.
- Skúste poradie povymieňať priamo v poli a nie iba pri výpise.
- Načítajte pole čísel, náhodne ich premiešajte a zase vypíšte.
SVGdraw
Knižnica SVGdraw umožňuje vytvoriť obrázok v SVG formáte a vykresľovať do neho rôzne geometrické útvary, animovať ich a používať korytnačiu grafiku.
- Návod na použitie knižnice v prostredí Netbeans a v prostredí Kate
- Stiahnutie knižnice
- Príklady programov na prednáške 5
Vykresľovanie v SVG formáte
- Ako prvé musíme vytvoriť súbor s obrázkom v SVG formáte s určitými rozmermi príkazom typu SVGdraw drawing(150, 100, "hello.svg");
- Do obrázku môžeme kresliť príkazmi drawRectangle, drawEllipse, drawLine, drawText.
- Ak chceme vykresľovať mnohouholníky, použijeme skupinu príkazov startPolygon, addPolygonPoint a drawPolygon. Pomocou startPolygon a addPolygonPoint postupne vymenujeme vrcholy a pomocou drawPolygon mnohouholník uzavrieme a vykreslíme.
- Pomocou príkazov setLineColor, setFillColor, setNoFill nastavujeme farbu čiar a vyfarbovania. Farby zadávame buď troma číslami od 0 do 255 určujúcimi intenzitu červenej, zelenej a modrej, alebo názvom, napr. "red" (zoznam mien farieb). Príkaz setFontSize nastavuje veľkosť písma a setLineWidth nastavuje hrúbku čiary.
- Po vykreslení všetkých útvarov ukončíme vykresľovanie príkazom drawing.finish();
- Po spustení programu by mal vzniknúť súbor hello.svg, ktorý si môžete prezrieť napríklad v internetovom prehliadači.
Animácie
- Príkaz wait umožní pozastaviť vykresľovanie SVG súboru o zadaný čas v sekundách, takže jednotlivé útvary sa objavujú postupne.
- Príkaz clear schová všetky vykreslené útvary, takže môžeme kresliť znova na prázdnu plochu. Pred príkazom clear je vhodné použiť wait.
- Príkaz hideItem schová objekt (napr. čiaru) so zadaným číslom. Každý kresliaci príkaz vráti číslo práve vykresleného objektu, takže si ho stačí uložiť v nejakej premennej pre neskoršie mazanie.
Príkazy pre korytnačiu grafiku
Namiesto vykresľovania obdĺžnikov, čiar a pod na zadané súradnice môžeme obrázok vytvoriť aj korytnačou grafikou. Na obrázku bude pohyb korytnačky znázornený ako červený trojuholník a za sebou bude nechávať čiernu čiaru.
- Príkazom typu Turtle turtle(200, 300, "domcek2.svg", 50, 250, 0); vytvoríme SVG obrázok určitej veľkosti a s určitým menom súboru. Posledné tri čísla udávajú počiatočnú polohu korytnačky a jej natočenie.
- Korytnačka si pamätá svoju polohu a natočenie na ploche. Príkaz forward posunie korytnačku dopredu, príkazy turnLeft a turnRight ju otočia.
- Príkaz setSpeed umožňuje zmeniť rýchlosť korytnačky, aby sme lepšie videli, ako sa postupne hýbe.
Prednáška 6
Oznamy
Prebrali sme premenné, polia, podmienky, cykly a funkcie.
- Z týchto stavebných prvkov sa dajú vystavať pomerne komplikované programy.
- Menej skúsení programátori si potrebujú prácu s týmito pojmami čo najviac precvičiť. Skúste si vyriešiť všetky príklady z cvičení, pracujte na domácej úlohe. Kontaktujte nás, ak vám niečo nie je jasné.
- Video s príkladom použitia knižnice #SVGdraw na kreslenie kruhov môžte nájsť tu: Kreslíme kruhy.
Čo nás čaká v najbližšom čase
- DÚ1 bude zverejnené dnes po prednáške, riešte do pondelka 25.10. 22:00
- Dnes algoritmy s poliami
- Rozcvička zajtra sa tiež bude týkať polí
- V piatok na doplnkových cvičeniach bonusová rozcvička za 1 bod
- Počas riešenia hlavnej aj bonusovej rozcvičky treba byť fyzicky na cvičení, v odôvodnených prípadoch sa dá vopred dohodnúť účasť cez MS Teams
Pozor, v stredu 13.10. bude v miestnosti F1 fakultná akcia
- Preto prednáška bude vo forme videa, ktoré dostanete vopred k dispozícii a môžete si ho pozrieť v čase, ktorý vám vyhovuje.
- Ak ho chcete pozerať v čase prednášky, môžete ísť napríklad do voľných počítačových učební M-217 a F2-128 (=T3). Odporúčame priniesť si slúchadlá, ktoré môžete zapojiť do fakultného počítača.
Parametre funkcií: prehľad, opakovanie
Jednoduché typy, napr. int, double, bool
- Bez & sa skopíruje hodnota
- S & premenná dostane vo funkcii nové meno
void f1(int x) {
x++; // zmena x sa neprenesie do main (y zostane rovnaká)
cout << x << endl;
}
void f2(int &x) {
x++; // zmena x sa prenesie ako zmena y v main
cout << x << endl;
}
int main() {
int y = 0;
f1(y);
f2(y);
f1(y + 1);
//zle: f2(y+1);
}
Polia odovzdávame bez &
- väčšinou potrebujeme poslať aj veľkosť poľa, ak nie je globálne známa
- zmeny v poli zostanú aj po skončení funkcie
void f(int a[], int n) {
for (int i = 0; i < n; i++) {
cout << a[i] << endl;
}
}
int main() {
int b[3] = {1, 2, 3};
f(b, 3);
}
SVGdraw obrázky sú v skutočnosti objekty, väčšinou ich chcete posielať s &
- všetky zmeny na nich spravené pretrvávajú aj po skončení funkcie
#include "SVGdraw.h"
void kresli(SVGdraw &drawing, int n, int y,
int rozostup, int velkost) {
for(int i=0; i<n; i++) {
drawing.drawRectangle(i*rozostup+velkost, y,
velkost, velkost);
}
}
int main() {
SVGdraw drawing(320, 100, "stvorce.svg");
kresli(drawing, 10, 50, 30, 10);
drawing.finish();
}
Štruktúry (struct) väčšinou tiež posielame pomocou &
Návratové hodnoty:
- ak je výsledkom funkcie jedno číslo alebo pravdivostná hodnota, vrátime ju príkazom return
- ak je výsledkom viac hodnôt, alebo niečo zložitejšie (pole, struct,...), odovzdáme ho ako parameter pomocou &, návratová hodnota môže zostať void (pri poli & nedávame)
Tieto pravidlá súvisia so smerníkmi a správou pamäti, povieme si viac o pár týždňov
Funkcie a polia: načítanie a vypísanie poľa
Dve základné funkcie, ktoré sa nám môžu zísť v programoch
- precvičíme si tiež ako sa pracuje s poliami vo funkciách
#include <cstdlib>
#include <iostream>
using namespace std;
void readArray(int a[], int &n, int maxN) {
/* Od užívateľa načíta počet vstupných čísel,
* tento počet uloží do premennej n.
* Potom načíta n celých čísel a uloží ich do poľa a,
* Hodnota maxN je veľkosť poľa,
* ktorú nemožno prekročiť. */
cin >> n;
if (n > maxN) {
cout << "Prilis velke n!" << endl;
exit(1);
}
for (int i = 0; i < n; i++) {
cin >> a[i];
}
}
void printArray(int a[], int n) {
for (int i = 0; i < n; i++) {
cout << " " << a[i];
}
cout << endl;
}
int main() {
const int maxN = 100;
int n;
int a[maxN];
readArray(a, n, maxN);
// tu môžeme pole nejako upraviť
printArray(a, n);
}
Triedenia
Máme pole čísel, chceme ich usporiadať od najmenšieho po najväčšie.
- Napr. pre pole 9 3 7 4 5 2 chceme dostať 2 3 4 5 7 9
- Jeden z najštudovanejších problémov v informatike.
- Súčasť mnohých zložitejších algoritmov.
- Veľa spôsobov, ako triediť, dnes si ukážeme zopár najjednoduchších.
Bublinkové triedenie (Bubble Sort)
Idea: Kontrolujeme všetky dvojice susedných prvkov a keď vidíme menšie číslo za väčším, vymeníme ich
for (int i = 1; i < n; i++) {
if (a[i] < a[i - 1]) {
swap(a[i - 1], a[i]);
}
}
- Ak sme nenašli v poli žiadnu dvojicu, ktorú treba vymeniť, skončili sme.
- Inak celý proces opakujeme znova.
Celé triedenie:
void swap(int &x, int &y) {
/* Vymeň hodnoty premenných x a y. */
int tmp = x;
x = y;
y = tmp;
}
void sort(int a[], int n) {
/* usporiadaj prvky v poli a od najmenšieho po najväčší */
bool hotovo = false;
while (!hotovo) {
bool vymenil = false;
/* porovnávaj všetky dvojice susedov,
vymeň ak menší za väčším */
for (int i = 1; i < n; i++) {
if (a[i] < a[i - 1]) {
swap(a[i - 1], a[i]);
vymenil = true;
}
}
/* ak sme žiadnu dvojicu nevymenili,
môžeme skončiť. */
if (!vymenil) {
hotovo = true;
}
}
}
- Čo ak vo for cykle dáme for (int i = 0; i < n; i++) { ?
- Ako nahradíme premennú hotovo príkazom break?
Príklad behu:
prvá iterácia while cyklu 9 3 7 4 5 2 3 9 7 4 5 2 3 7 9 4 5 2 3 7 4 9 5 2 3 7 4 5 9 2 3 7 4 5 2 9 druhá iterácia while cyklu 3 7 4 5 2 9 3 4 7 5 2 9 3 4 5 7 2 9 3 4 5 2 7 9 tretia iterácia while cyklu 3 4 5 2 7 9 3 4 2 5 7 9 štvrtá iterácia while cyklu 3 4 2 5 7 9 3 2 4 5 7 9 piata iterácia while cyklu 3 2 4 5 7 9 2 3 4 5 7 9
Cvičenie: Ako sa bude správať algoritmus na nasledujúcich vstupoch, koľkokrát zopakuje vonkajší while cyklus?
- Utriedené pole 1,2,...,n
- Pole n,1,2,...,n-1
- Pole 2,3,...,n,1
- Pole n,n-1,...,1
Triedenie výberom (selection sort, max sort)
Idea: nájdime najväčší prvok a uložme ho na koniec. Potom nájdime najväčší medzi zvyšnými a uložme ho na druhé miesto odzadu atď.
- V cykle uvádzame ako komentár invariant, podmienku, ktorá na tom mieste vždy platí. Takýto invariant nám pomôže si uvedomiť, že je náš program správny.
int maxIndex(int a[], int n) {
/* vráť index, na ktorom je najväčší prvok
z prvkov a[0]...a[n-1] */
int index = 0;
for(int i=1; i<n; i++) {
if(a[i]>a[index]) {
index = i;
}
/* invariant: a[j]<=a[index] pre vsetky j=0,...,i*/
}
return index;
}
void sort(int a[], int n) {
/* usporiadaj prvky v poli a od najmenšieho po najväčší */
for(int kam = n - 1; kam >= 1; kam--) {
/* invariant: a[kam+1]...a[n-1] sú utriedené
* a pre každé i,j také že 0<=i<=kam, kam<j<n
* platí a[i]<=a[j] */
int index = maxIndex(a, kam + 1);
swap(a[index], a[kam]);
}
}
Príklad behu programu
Vstup 9 3 7 4 5 2 Po výmene (9,2) 2 3 7 4 5 9 Po výmene (7,5) 2 3 5 4 7 9 Po výmene (5,4) 2 3 4 5 7 9 Po výmene (4,4) 2 3 4 5 7 9 Po výmene (3,3) 2 3 4 5 7 9
Cvičenie: Bude čas behu algoritmu výrazne odlišný pre pole utriedené správne a pole utriedené v opačnom poradí?
Triedenie vkladaním (Insertion Sort)
Idea:
- v prvej časti poľa prvky v utriedenom poradí
- zober prvý prvok z druhej časti a vlož ho na správne miesto v utriedenom poradí
Príklad behu algoritmu:
9 3 7 4 5 2 3 9 7 4 5 2 3 7 9 4 5 2 3 4 7 9 5 2 3 4 5 7 9 2 2 3 4 5 7 9
Ako spraviť vkladanie:
- Vkladaný prvok si zapamätáme v pomocnej premennej
- Utriedené prvky posúvame o jedno doprava, kým nenájdeme správne miesto pre odložený prvok
void sort(int a[], int n) {
/* usporiadaj prvky v poli a od najmenšieho po najväčší */
for (int i = 1; i < n; i++) {
int prvok = a[i];
int kam = i;
while (kam > 0 && a[kam - 1] > prvok) {
a[kam] = a[kam - 1];
kam--;
}
a[kam] = prvok;
}
}
- Všimnime si podmienku (kam > 0 && a[kam - 1] > prvok)
- Ak kam==0, prvá časť je false, druhá časť sa už nevyhodnocuje
- Ak by sme prehodili časti, program by mohol spadnúť (a[kam - 1] > prvok && kam > 0)
Cvičenie: Ako sa bude správať algoritmus na nasledujúcich vstupoch, koľkokrát zopakuje priradenie a[kam]=a[kam-1]?
- Utriedené pole 1,2,...,n
- Pole n,1,2,...,n-1
- Pole 2,3,...,n,1
- Pole n,n-1,...,1
Triedenia: zhrnutie
- Videli sme tri jednoduché algoritmy na triedenie
- Neskôr sa naučíme rýchlejšie algoritmy na triedenie, ktoré používajú rekurziu
- Precvičili sme si funkcie, parametre a polia
- K funkciám je dobré napísať, čo robia
- Do cyklov si môžeme písať invarianty
- Používajú sa pri formálnom dokazovaní správnosti
- Pomáhajú pochopeniu kódu
- Môžeme ich použiť na ručnú alebo automatickú kontrolu správnosti hodnôt premenných
- Príkaz assert v knižnici cassert kontroluje podmienku, napr. assert(i>=0 && i<n); ukončí program s chybovou hláškou ak podmienka neplatí
Cvičenie:
- Na vstupe sú dve n-prvkové množiny (čísla v množine sa neopakujú, ale môžu byť zadané v ľubovoľnom poradí)
- Zistite, tieto množiny obsahujú rovnaké prvky
- Viete pri tom použiť triedenie?
Eratostenovo sito
- Prvočíslo je prirodzené číslo väčšie ako 1, ktoré je deliteľné len samo sebou a číslom 1.
- Chceli by sme nájsť všetky prvočísla medzi 2 a n.
- Napríklad ak n=30, výsledok má byť 2, 3, 5, 7, 11, 13, 17, 19, 23, 29.
Mohli by sme ísť cez všetky čísla a pre každé testovať, koľko má deliteľov (deliteľov sme už hľadali predtým), ale vieme to spraviť aj rýchlejšie. Použijeme algoritmus zvaný Eratostenovo sito.
- Vytvoríme pole a pravdivostných hodnôt, kde a[i] nám hovorí, či je i ešte potenciálne prvočíslo.
- Na začiatku budú všetky hodnoty true, lebo sme ešte žiadne číslo nevylúčili.
- Začneme číslom 2. Toto je iste prvočíslo, tak ho vypíšeme. O jeho násobkoch však vieme, že iste nemôžu byť prvočísla. Nastavíme preto pre každý násobok j=2*k pravdivostnú hodnotu a[j] na false.
- Potom prechádzame v poli, kým nenájdeme najbližšiu ďalšiu hodnotu true. Toto číslo je prvočíslo, teda ho vypíšeme a vyškrtáme jeho násobky.
#include <iostream>
using namespace std;
int main() {
const int n = 30;
bool a[n + 1];
for (int i = 2; i <= n; i++) {
a[i] = true;
}
for (int i = 2; i <= n; i++) {
if (a[i]) {
cout << i << " ";
for (int j = 2 * i; j <= n; j = j + i) {
a[j] = false;
}
}
}
cout << endl;
}
Výstup programu
2 3 5 7 11 13 17 19 23 29
Priebeh programu:
0 1 2 3 4 5 6 7 8 9 10 11 12 ... ? ? T T T T T T T T T T T ... na zaciatku ? ? T T F T F T F T F T F ... po vyskrtani i=2 ? ? T T F T F T F F F T F ... po vyskrtani i=3 ? ? T T F T F T F F F T F ... dalej sa uz skrtaju len vacsie cisla
Cvičenie: Napíšte funkciu, ktorá uloží prvočísla medzi 2 a n do poľa (ak by sme ich chceli použiť na ďalšie výpočty).
Zdrojový kód programu s triedeniami
/* Program s triedeniami z prednášky 6.
http://compbio.fmph.uniba.sk/vyuka/prog/index.php/Predn%C3%A1%C5%A1ka_6 */
#include <iostream>
#include <cstdlib>
using namespace std;
void swap(int &x, int &y) {
/* Vymeň hodnoty premenných x a y. */
int tmp = x;
x = y;
y = tmp;
}
void readArray(int a[], int &n, int maxN) {
/* Od užívateľa načíta počet vstupných čísel,
* tento počet uloží do premennej n.
* Potom načíta n celých čísel a uloží ich do poľa a,
* Hodnota maxN je veľkosť poľa,
* ktorú nemožno prekročiť. */
cin >> n;
if (n > maxN) {
cout << "Prilis velke n!" << endl;
exit(1);
}
for (int i = 0; i < n; i++) {
cin >> a[i];
}
}
void printArray(int a[], int n) {
for (int i = 0; i < n; i++) {
cout << " " << a[i];
}
cout << endl;
}
void bubbleSort(int a[], int n) {
/* usporiadaj prvky v poli a od najmenšieho po najväčší */
bool hotovo = false;
while (!hotovo) {
bool vymenil = false;
/* porovnávaj všetky dvojice susedov, vymeň ak menší za väčším */
for (int i = 1; i < n; i++) {
if (a[i] < a[i - 1]) {
swap(a[i - 1], a[i]);
vymenil = true;
}
}
/* ak sme žiadnu dvojicu nevymenili, môžeme skončiť. */
if (!vymenil) {
hotovo = true;
}
}
}
int maxIndex(int a[], int n) {
/* vráť index, na ktorom je najväčší prvok z prvkov a[0]...a[n-1] */
int index = 0;
for(int i=1; i<n; i++) {
if(a[i]>a[index]) {
index = i;
}
/* invariant: a[j]<=a[index] pre vsetky j=0,...,i*/
}
return index;
}
void selectionSort(int a[], int n) {
/* usporiadaj prvky v poli a od najmenšieho po najväčší */
for(int kam=n-1; kam>=1; kam--) {
/* invariant: a[kam+1]...a[n-1] sú utriedené
* a pre každé i,j také že 0<=i<=kam, kam<j<n platí a[i]<=a[j] */
int index = maxIndex(a, kam+1);
swap(a[index], a[kam]);
}
}
void insertionSort(int a[], int n) {
/* usporiadaj prvky v poli a od najmenšieho po najväčší */
for (int i = 1; i < n; i++) {
// inv1
int prvok = a[i];
int kam = i;
while (kam > 0 && a[kam - 1] > prvok) {
// inv2
a[kam] = a[kam - 1];
kam--;
}
a[kam] = prvok;
}
}
int main() {
const int maxN = 100;
int n;
int a[maxN];
readArray(a, n, maxN);
printArray(a, n);
insertionSort(a, n);
printArray(a,n);
}
Prednáška 7
Oznamy
- Začiatok semestra je pre začiatočníkov ťažký, ale programovať sa naučíte len riešením čo najväčšieho počtu príkladov
- Bez dobrej znalosti cyklov, podmienok, premenných, polí a funkcií nebudete rozumieť ďalšiemu učivu a nespravíte skúšku
- Snažte sa každý týždeň vyriešiť čo najviac príkladov
- Pred cvičením si pozrite poznámky z prednášok
- Dobre si prečítajte zadanie, vrátane príkladu vstupu a výstupu
- Cieľom príkladu vstupu je aj lepšie ilustrovať zadanie. Skúste si skontrolovať, ako sa asi výstup vypočítal zo vstupu.
- Najskôr si vymyslite postup, ako idete úlohu riešiť. Vytiahnite si papier na poznámky a náčrtky.
Domáca úloha do pondelka 25.10.
- Preštudujte si zadanie, pýtajte sa otázky
- K úlohe sa vám môže hodiť pozrieť si video z konca prednášky 5 o knižnici #SVGdraw a o ukladaní struct-ov do poľa
- Časť bodov môžete dostať aj za neúplný program, začnite od jednoduchších častí, napr. načítanie vstupu a uloženie do poľa, vykreslenie mnohouholníka a bodov jednotnou farbou
- Potom môžete prejsť na počítanie priesečníka a správne nastavovanie farieb v obrázku
- Úloha je dobrá príležitosť precvičiť si doteraz preberanú látku
- Každá domáca úloha má váhu 5% známky, t.j. zhruba ako dva týždne cvičení
Tento piatok bude na doplnkovom cvičení bonusová rozcvička za 1 bod
- Ak ste v utorok na cvičení vyriešili len 1-2 príklady, odporúčame prísť v piatok na cvičenia
Ďalšie prednášky
- Dnes ešte algoritmy, znaky, v pondelok reťazce (ďalšie precvičenie polí a funkcií, trochu nových pojmov z C)
- Budúcu stredu začneme rekurziu, potenciálne ťažké učivo
Budúci týždeň cvičenia v špeciálnom režime
- Budúci utorok rozcvička a zopár príkladov na znaky a reťazce
- Budúcu stredu po prednáške pribudne 1 menší príklad na rekurziu, v piatok bude opäť bonusová rozcvička na rekurziu
- Odporúčame budúci týždeň na doplnkové cvičenia prísť aj stredne pokročilým programátorom, ak ste ešte nerobili s rekurziou
Vyhľadávanie prvkov poľa
Chceme zistiť, či pole obsahuje prvok zadanej hodnoty.
- Musíme prejsť celé pole, lebo nevieme, kde sa prvok môže nachádzať.
- Tento algoritmus sa nazýva lineárne vyhľadávanie
/* Funkcia find vráti index výskytu prvku x
* v poli a. Ak sa x v poli nevyskytuje, vráti -1.
* Hodnota n určuje počet prvkov poľa. */
int find(int a[], int n, int x) {
for (int i = 0; i < n; i++) {
if (a[i] == x) return i;
}
return -1;
}
- Toto môžeme urobiť aj v prípade, že máme pole usporiadané.
- Ale neexistuje lepšie riešenie?
Binárne vyhľadávanie v utriedenom poli
Ak porovnáme hľadanú hodnotu x s nejakým prvkom utriedeného poľa a[i], môžu nastať tri možnosti:
- ak sme trafili pozíciu i takú, že x==a[i], máme odpoveď a môžeme skončiť s vyhľadávaním
- ak x < a[i], tak všetky prvky a[j] napravo od pozície i budú určite tiež väčšie ako x a teda ich nemusíte ďalej uvažovať, stačí hľadať vľavo od i
- ak x > a[i], tak všetky prvky a[j] naľavo od pozície i budú určite tiež menšie ako x a teda ich nemusíte ďalej uvažovať, stačí hľadať vpravo od i
Binárne vyhľadávanie v utriedenom poli teda pracuje nasledovne:
- pamätáme si ľavý a pravý okraj intervalu, kde ešte môže byť hľadaný prvok x
- vyberieme prvok a[index] v strede tohoto intervalu, teda index=(left+right)/2
- na základe porovnania s hľadaným prvkom x interval skrátime na polovicu
- ak už je interval zlý (t.j. pravý a ľavý kraj sú naopak), tak skončíme
int find(int a[], int n, int x) {
int left = 0, right = n - 1;
while (left <= right) {
int index = (left + right) / 2;
if (a[index] == x) {
return index;
}
else if (a[index] < x) {
left = index + 1;
}
else {
right = index - 1;
}
}
return -1;
}
Ukážka práce algoritmu pre dva vstupy
int a[7]={2,5,21,32,38,45,50}
x=21
left=0 right=6: index=3; A[index]>x (32>21)
left=0 right=2; index=1; A[index]<x (5<21)
left=2 right=2; index=2; A[index]=x -> return 2
x=11
left=0 right=6: index=3; A[index]>x (32>11)
left=1 right=2; index=1; A[index]<x (5<11)
left=2 right=2; index=2; A[index]>x (21>11)
left=2 right=1; left>right -> koniec while cyklu -> return -1
Intuitívne máme pocit, že binárne vyhľadávanie je lepšie, ako lineárne.
Zložitosť algoritmu
Ako sme videli napríklad pri triedení a vyhľadávaní, jednu úlohu môžeme často riešiť viacerými spôsobmi. Intuitívne máme o niektorých pocit, že sú lepšie ako iné. Pozrime sa, prečo sú niektoré riešenia lepšie a ako môžeme niečo také odhadovať.
Časová zložitosť lineárneho vyhľadávania
Často nás zaujíma, ako rýchlo nám program bude bežať. Väčšinou táto rýchlosť nejako závisí od vstupných dát. Iste bude kratšie trvať triedenie trojprvkového poľa ako poľa s milión prvkami. Časovú zložitosť teda budeme odhadovať v závislosti od veľkosti vstupu.
Pre niektoré programy môžeme spočítať počet operácií, ktoré program vykoná na vstupoch veľkosti n.
- Ukážme si túto metódu pre lineárne vyhľadávanie v neutriedenom poli
int find(int a[], int n, int x) {
for (int i = 0; i < n; i++) {
if (a[i] == x) return i;
}
return -1;
}
- Najmenej operácií spravíme, ak x je v a[0]
- Vtedy spravíme 4 kroky: i=0, i<n, a[i]==x, return i (závisí aj od toho, čo presne považujeme za "jeden krok")
- Najviac operácií spravíme, ak sa x v poli nenachádza
- Vtedy spravíme raz i=0, (n+1) krát i<n, n krát i++, n krát a[i]==x, raz return -1, spolu 3n+3 krokov
- Celkový počet krokov bude teda niečo medzi 4 a 3n+3
Vo väčších programoch však toto rozmedzie nie je jednoduché vypočítať.
- Preto uvažujeme väčšinou iba najhorší prípad, ktorý môže nastať
- Okrem toho nás nezaujímajú presné čísla, ale iba akýsi odhad (približná funkcia) závislá od vstupu.
- Pri lineárnom vyhľadávaní je v najhoršom prípade počet krokov lineárna funkcia od n, vravíme teda, že tento algoritmus má lineárnu zložitosť, značíme O(n)
- Presnú definíciu O uvidíte budúci rok na predmete Algoritmy a dátové štruktúry
Časová zložitosť binárneho vyhľadávania
- Najhorší možný scenár pre danú veľkosť vstupu n nastane, keď prvok nájdeme až v poslednom kroku alebo v poli nebude vôbec.
- V prvom kroku máme celé pole a v ňom sa pozrieme na stredný prvok a podľa jeho hodnoty zoberieme buď ľavú alebo pravú (zhruba) polovicu poľa.
- Tým pádom v druhom kroku máme pole polovičnej veľkosti a robíme na ňom zase to isté.
- V každom kroku teda máme pole o polovicu menšie, až kým nemáme pole veľkosti 1. Potom už prvok nájdeme alebo v ďalšom kroku povieme, že tam nie je.
- Akú zložitosť bude mať tento algoritmus?
- Zapíšeme si číslo n (počet prvkov) v dvojkovej sústave.
- Pri delení poľa na polovicu bude ďalšia veľkosť poľa toto číslo bez poslednej cifry.
- Počet krokov, ktoré potrebujeme, je teda zhruba počet cifier n v dvojkovej sústave, čo je log2 n.
- Vravíme teda, že zložitosť binárneho vyhľadávania je logaritmická, značíme O(log n)
- Logaritmus rastie pre veľké n oveľa pomalšie ako lineárna funkcia, čiže binárne vyhľadávanie považujeme za efektívnejší algoritmus ako lineárne vyhľadávanie
- pozor, neplatí to však pre každý vstup, iba pre porovnanie najhorších prípadov pre dosť veľké n
Pre ilustráciu som na mojom počítači som namerala, koľko sekúnd v priemere trvá lineárne a binárne vyhľadávanie v poli s n číslami:
n lineárne binárne 10 3.1e-8 3.7e-8 100 2.0e-7 6.9e-8 1000 1.8e-6 1.0e-7 10000 1.8e-5 1.4e-7 100000 1.8e-4 1.8e-7 1000000 1.8e-3 2.4e-7
Pripomíname, že napr. 1.8e-3 je 1.8 ⋅ 10-3, t.j. 0.0018. Pri hľadaní v poli dĺžky 10 je teda lineárne vyhľadávanie rýchlejšie, ale v poli dĺžky milión je už vyše 7000 krát pomalšie...
Časová zložitosť triedenia vkladaním
Triedenie vkladaním (Insertion sort) z minulej prednášky
- Pripomíname ideu: prvých i prvkov máme utriedených, prvok a[i] sa snažíme vložiť na správne miesto
- Na to musíme posunúť všetky väčšie prvky o jedna doprava, aby sme mu spravili miesto
void sort(int a[], int n) {
/* usporiadaj prvky v poli a od najmenšieho po najväčší */
for (int i = 1; i < n; i++) {
int prvok = a[i];
int kam = i;
while (kam > 0 && a[kam - 1] > prvok) {
a[kam] = a[kam - 1];
kam--;
}
a[kam] = prvok;
}
}
- V najhoršom prípade pre dané i bude a[i] menšie ako všetky doteraz utriedené prvky a teda while cyklus bude bežať i krát
- Ak je pole na začiatku usporiadané naopak, t.j. od najväčšieho prvku po najmenší, tento najhorší prípad nastane pri každej hodnote i
- Teraz si už iba spočítame: pre i=1 posúvame 1 prvok, pre i=2 dva prvky, ..., pre i=n-1 posúvame n-1 prvkov
- Teda čas, ktorý na to potrebujeme je 1+2+...+(n-1) = n(n-1)/2 = n2/2-n/2.
- Zložitosť tohto triedenia bude teda kvadratická, čiže O(n2)
- Bude sa však správať rovnako (kvadraticky) na všetkých vstupoch? Čo ak dostaneme na vstupe pole už správne utriedené?
Ostatné triedenia z prednášky (výberom a bublinkové) majú tiež v najhoršom prípade kvadratickú zložitosť
- Premyslite si prečo
- Ako dlho im to potrvá v najlepšom prípade?
Existujú však aj triedenia s časovou zložitosťou O(n log n), ako uvidíme neskôr v semestri
Cvičenie:
- Na vstupe máme n čísel usporiadaných od najmenšieho po najväčšie a číslo x, chceme zistiť, či sa x nachádza medzi n číslami
- Načítame čísla do poľa a spustíme lineárne alebo binárne vyhľadávanie
- Aká bude časová zložitosť týchto dvoch verzií programu?
- Čo ak nechceme vyhľadávať jednu hodnotu x, ale m rôznych hodnôt?
- Čo ak nie sú čísla na vstupe utriedené a pred binárnym vyhľadávaním musíme najskôr triediť?
Znaky
Doteraz sme pracovali iba s číselnými dátami, ale pri programovaní často pracujeme z reťazcami (textami).
- Reťazce budú na ďalšej prednáške, dnes si ukážeme, ako pracovať s ich jednotlivými súčasťami, znakmi (písmená, čísla, medzery,...)
- Znakové konštanty sa zapisujú v apostrofoch, napr. 'A', '1', ' ' a pod.
- Znakové premenné sú typu char, z anglického character. Ich veľkosť je spravidla 1 bajt, t.j. 8 bitov.
Znaky majú svoje kódy uvedené v tabuľke ASCII. Najbežnejšie sa budeme stretávať s týmito:
- 48...57: '0'...'9'
- 65...90: 'A'...'Z'
- 97...122: 'a'...'z'
- 32: medzera ' '
- 9: tabulátor '\t'
- 10: koniec riadku '\n'
- 0: špeciálny nulový znak (uvidíme nabudúce) '\0'
Poznámky
- bežné znaky z US klávesnice sú v rozsahu 0..127 (7 bitov)
- nakoľko char je 8-bitový, môže ešte nadobúdať hodnoty -1 ... -128 alebo 128..255 podľa kompilátora
- moderný softvér väčšinou namiesto klasických 8-bitových znakov používa Unicode, aby sa dali reprezentovať aj rôzne špeciálne symboly, znaky s diakritikou, jazyky nepoužívajúce latinku a pod.
- na tomto predmete si vystačíme s klasickými znakmi v rozsahu 0..127
Do premennej typu char môžeme priraďovať, jej obsah zapísať alebo prečítať:
char c='A';
char z;
z=c;
cout << c;
cin >> z; // prečíta jeden znak (pozor, preskakujú sa biele znaky)
Znaky môžeme porovnávať. Na konci programu vyššie platí nasledovné:
- c=='A' ... je pravda,
- c=='a' ... nie je pravda – rozlišujú sa malé a veľké písmená,
- c<='Z' ... je pravda – písmená sú usporiadané: A<B< ... <Z, a<b< ... <z, aj cifry sú usporiadané: 0<1< ... <9.
Pri čítaní zo vstupu pomocou cin do premennej typu char sa preskakujú tzv. biele znaky (napr. medzera, tabulátor, koniec riadku).
- Toto nie je vždy žiadúce a preto môžeme použiť modifikátor noskipws, ktorý zruší preskakovanie takýchto znakov. Do premennej teda budeme vedieť prečítať aj medzeru.
#include <iostream>
using namespace std;
int main(void) {
char a,b,c;
cin >> noskipws >> a >> b >> c;
cout << a << b << c;
}
Hodnota jednoduchého výrazu
Nasledujúci program spočíta hodnotu jednoduchého výrazu, ktorý pozostáva z dvoch čísel spojených znamienkom +, -, * alebo /. Okolo sú medzery (kvôli jednoduchšiemu načítaniu).
Napr. pre vstup 1 / 2 program vypíše 0.5.
#include <iostream>
#include <cstdlib>
using namespace std;
int main(void) {
double a, b;
char znamienko;
cin >> a >> znamienko >> b;
double vysledok;
if (znamienko == '+') {
vysledok = a + b;
}
else if (znamienko == '-') {
vysledok = a - b;
}
else if (znamienko == '*') {
vysledok = a * b;
}
else if (znamienko == '/') {
vysledok = a / b;
} else {
cout << "zle znamienko " << znamienko << endl;
exit(1);
}
cout << vysledok << endl;
}
Switch
- V predchádzajúcom programe bola pomerne dlhá a komplikovaná séria príkazov if, else
- Namiesto toho sa dá použiť príkaz switch, ktorý podľa hodnoty výrazu pokračuje jednou z viacerých vetiev.
V našom jednoduchom príklade by mohol switch vyzerať nasledovne:
switch (znamienko) {
case '+' :
vysledok = a + b;
break;
case '-' :
vysledok = a - b;
break;
case '*' :
vysledok = a * b;
break;
case '/' :
vysledok = a / b;
break;
default:
cout << "zle znamienko " << znamienko << endl;
exit(1);
}
Vo všeobecnosti obsahuje príkaz switch viacero rôznych prípadov vyhodnotenia výrazu v podmienke.
switch (výraz)
{
case k1: príkazy1
case k2: príkazy2
default: príkazyd
}
Takýto príkaz funguje nasledovne:
- Vyhodnotí výraz.
- Ak sa hodnota zhoduje s konštantným výrazom ki v niektorom z prípadov, pokračuje časťou príkazyi
- Ak sa nezhoduje a máme vetvu default, pokračuje sa časťou prikazyd
- Ak nie je vetva default, pokračuje sa za koncom switch bloku.
- Pozor: Na rozdiel od pascalovského case, vykonávanie nekončí vykonaním posledného príkazu v prikazyi, ale pokračuje ďalej, kým nie je prerušené príkazom break.
- Toto je častá chyba pri použití príkazu switch
#include <iostream.h>
void main () {
int n;
cout << "Zadaj n (1,2,3,4): ";
cin >> n;
switch (n) {
case 1: cout << "Jeden" << endl;
case 2: cout << "Dva" << endl;
case 3:
case 4: cout << "Tri alebo styri" << endl;
default: cout << "Chyba!" << endl;
}
cout << "Koniec." << endl;
}
Pre n=2 sa začnú vykonávať príkazy uvedené za vetvou case 2:. Vypíše sa:
Dva
Tri alebo styri
Chyba!
Koniec.
Výhodou je, že môžeme zlúčiť viacero prípadov do jednej vetvy tým, ze príkazy napíšeme až za posledný prípad (tu vidíme napr. v situácii n=3 a n=4).
Dôležité upozornenie: break switch while
Predstavme si, že v programe sa pýtame užívateľa, či chce pokračovať s ďalším vstupom, pričom odpoveď má byť znak 'A' alebo 'N'. Ak by sme program napísali takto, nefungoval by:
while (true) {
// nejaky vypocet
cout << "Chcete pokracovat? (Zadajte odpoved A alebo N)" << endl;
char odpoved;
cin >> odpoved;
switch (odpoved) {
case 'N':
break;
// spracovanie inych pripadov...
}
}
- Príkaz break nevyskočí zo všetkých cyklov, ale iba z najvnútornejšieho - a tým je v tomto prípade switch. Program teda pokračuje aj keď užívateľ zadá 'N'.
- Ak by break bol použitý s podmienkou, všetko by fungovalo: while (true) { ... if (odpoved=='N') { break; } }
Ešte znaky
Pretypovanie
Znakové premenné teda ukladajú kódy jednotlivých znakov, čo sú celé čísla.
- Preto medzi znakmi a celými číslami môžeme prechádzať jednoducho (char môžeme priradiť do int a naopak, s char môžeme tiež robiť aritmetické operácie, pozor jedine na malý rozsah char-u)
- Ale pri výpise sa výraz typu char vypisuje ako znak podľa ASCII tabuľky, výraz typu int ako číslo, niekedy teda treba pretypovať
- Podobne vstup sa inak spracúva, ak ide do premennej char vs int.
#include<iostream>
using namespace std;
int main(void) {
int i;
char c;
c = 'A'; // to iste ako c = 65
cout << c << endl; // vypise A
cout << c+1 << endl; // vypise 66 (c+1 je typu int)
cout << (char)(c+1) << endl; // pretypujeme, vypise B
cout << "Napiste cifru 0-9: ";
cin >> c;
// ak pouzivatel zada 0, do c sa ulozi '0', t.j. 48
cout << "Napiste cifru 0-9: ";
cin >> i;
// ak pouzivatel zada 0, do i sa ulozi hodnota 0
cout << c << " " << (int)c << endl;
cout << i << " " << (char)i << endl;
}
Prednáška 8
Oznamy
Prednášky a cvičenia tento týždeň
- Dnešná prednáška reťazce
- Zajtra na cvičeniach rozcvička na reťazce plus ďalšie príklady na reťazce (a znaky, polia, funkcie)
- Prednáška v stredu rekurzia
- V stredu po prednáške pribudne ďalší príklad na rekurziu a v piatok bonusová rozcvička
- V rekurzii pokračujeme aj budúci týždeň
- Domáca úloha do budúceho pondelka
Z minulej prednášky
Znaky
- Znakové premenné sú typu char, z anglického character.
- Znaky majú svoje kódy uvedené v tabuľke ASCII.
- Do premennej typu char môžeme priraďovať, jej obsah zapísať alebo prečítať. Znaky môžeme porovnávať pomocou ==, <= atď
- Znakové premenné ukladajú kódy jednotlivých znakov, čo sú celé čísla. Preto medzi znakmi a celými číslami môžeme prechádzať úplne jednoducho.
- Keď chceme aby výsledok bol konkrétneho typu, použijeme pretypovanie.
- Znakové konštanty sa píšu v apostrofoch, napr. 'A'
Switch
- Namiesto niekoľkých vnorených if s tou istou premennou v podmienke môžeme použiť switch.
- Vo všeobecnosti obsahuje príkaz switch viacero rôznych prípadov vyhodnotenia výrazu v podmienke.
switch (výraz) {
case k1: príkazy1; break;
case k2: príkazy2; break;
default: príkazyd;
}
Pozor: vykonávanie nekončí vykonaním posledného príkazu v prikazyi, ale pokračuje ďalej, kým nie je prerušené príkazom break.
- Výhodou je, že môžeme zlúčiť viacero prípadov do jednej vetvy.
Využitie znakov
Vďaka znakom môžeme spraviť kontrolu toho, čo vlastne používateľ napísal na vstup. Napríklad, či zadal správne celé číslo a nenamiešal medzi cifry nejaký iný znak.
#include <iostream>
using namespace std;
int main(void) {
int N = 0;
char c;
cout << "Zadajte cele kladne cislo: ";
cin >> noskipws >> c;
// kým je načítaný znak číslo (t.j. jedna cifra)
while ((c >= '0') && (c <= '9')) {
// prevod z kódu znaku na cifru 0..9
// ('0' má kod 48)
int cifra = c - '0';
// upravíme číslo N
N = N * 10 + cifra;
// a načítame ďalší znak
cin >> noskipws >> c;
}
if ((c == ' ') || (c == '\n')) {
// ak sme skončili medzerou alebo koncom riadku,
// tak je to pekné číslo
cout << "Zadali ste " << N << endl;
} else {
// ak sme skončili niečim iným, asi to nebude ok
cout << "Toto je cele cislo?" << endl;
}
}
Reťazce v jazyku C
Textový reťazec je v jazyku C štandardne uložený v poli ako postupnosť znakov (char) ukončená znakom s kódom 0.
- Napr. reťazec "ABC" je uložený ako pole dĺžky 4 obsahujúci kódy 65, 66, 67, 0 (resp. znaky 'A', 'B', 'C', '\0')
- Pozor, rozdiel medzi znakom s kódom 0 (píše sa aj '\0') a znakom pre cifru nula '0' s kódom 48
- Reťazce teda nemôžu obsahovať vo vnútri znak s kódom 0, ten je rezervovaný na ukončovanie
- Na reťazec s n znakmi potrebujeme pole dĺžky aspoň n+1, lebo jeden znak sa minie na ukončovací symbol
Keď sme robili funkcie na prácu s poľom čísel, museli sme poslať pole aj počet prvkov. Pri reťazcoch nemusíme zvlášť udržiavať dĺžku, tá je daná pozíciou nuly v poli.
Inicializácia reťazcov
- Chceme vytvoriť premennú str obsahujúce reťazec Ahoj spolu s koncom riadku
- Prvý spôsob je zdĺhavý:
char str[6];
str[0] = 'A';
str[1] = 'h';
str[2] = 'o';
str[3] = 'j';
str[4] = '\n'; // znak pre koniec riadku
str[5] = 0;
- Alebo ako inicializácia poľa: char str[10]={'A','h','o','j','\n',0};
- Namiesto toho sa používa špeciálna skratka: char str[6]="Ahoj\n";
- Ako vytvoríme prázdny reťazec?
Reťazec je naozaj pole
Znaky reťazca môžeme meniť
char a[100] = "vlk";
char ch = a[0]; // ch obsahuje hodnotu 'v'
char b[100] = "pes";
b[0] = ch; // Výsledkom je 'ves'.
b[0] = 'd'; // Výsledkom je 'des'.
b[0] = a[1]; // Výsledkom je 'les'.
Reťazec sa nedá kopírovať jednoduchým priradením, nemôžeme teda spraviť
char a[100];
a = "Ahoj"; // chyba
char b[100] = "Ahoj"; // ok - inicializacia
a = b; // chyba
Reťazce sa nedajú ani porovnávať pomocou ==, !=, < atď
Kopírovanie a porovnávanie si musíme naprogramovať cez cykly, alebo použiť hotové funkcie z knižníc.
Knižnica cstring
Obsahuje mnohé funkcie na prácu s reťazcami, napríklad tieto:
- strlen(retazec): vráti dĺžku reťazca
- strcpy(kam, co): skopíruje reťazec co do reťazca kam (pole kam musí byť dosť dlhé)
- strcat(kam, co): za koniec reťazca kam pridá reťazec co (pole kam musí byť dosť dlhé)
- strcmp(retazec1, retazec2): vráti nulu ak sa reťazce rovnajú, kladné číslo keď je prvý neskôr v abecednom poradí, záporné číslo, ak je skôr. Pozor, to či je skôr alebo neskôr sa berie podľa kódov znakov, takže napr. 'Z' je skôr ako 'a'.
Všetky tieto funkcie by sme si však vedeli naprogramovať aj sami. Tu je napríklad výpočet dĺžky:
int myStrLen(char a[]) {
int n = 0;
while(a[n] != 0) { n++; }
return n;
}
- čo bude funkcia robiť ak reťazcu chýba na konci 0?
Dve verzie kopírovania:
void myStrCpy(char a[], char b[]) {
/* Skopiruj obsah retazca b do retazca a.
* Pole a musi mat dost miesta. */
int n = 0;
while (b[n] != 0) {
a[n] = b[n];
n++;
}
a[n] = 0; // reťazec musí končiť 0
}
void myStrCpy2(char a[], char b[]) {
/* Skopiruj obsah retazca b do retazca a.
* Pole a musi mat dost miesta. */
for (int i = 0; i <= strlen(b); i++) {
a[i] = b[i];
}
}
- Ktorá je rýchlejšia pre dlhé reťazce?
- Aká je ich zložitosť ako funkcia dĺžky reťazca n?
Namiesto strcmp naprogramujeme len test na rovnosť:
bool rovnostRetazcov(char a[], char b[]) {
/* vrati true ak su retazce a, b rovnake, inak vrati false */
for (int i = 0; a[i] != 0 || b[i] != 0; i++) {
if (a[i] != b[i]) return false;
}
return true;
}
- Ako bude prebiehať funkcia, ak jeden reťazec je začiatkom druhého?
Načítavanie a vypisovanie reťazcov
- Bežné načítanie z konzoly do reťazca (cin >> str) načíta jedno slovo
- Preskočí biele znaky (medzery, konce riadkov, tabulátory), potom prečíta všetko po ďalší biely znak (alebo koniec vstupu) a uloží do premennej.
- Pri čítaní je vhodné nastaviť maximálny počet znakov na načítanie, aby sme nevyšli z poľa
- Na načítanie jedného riadku je možné použiť funkciu getline. Načíta až po koniec riadku, ten zahodí.
- Vypisovanie funguje normálne pomocou cout << str
#include <iostream>
using namespace std;
int main(void) {
const int maxN = 100;
char str[maxN], str2[maxN], str3[maxN];
// načíta celý riadok, ale najviac maxN-1 znakov
cin.getline(str, maxN);
// najbližšie načíta najviac maxN-1 znakov
cin.width(maxN);
// načíta jedno slovo
cin >> str2;
// načítanie ďalšieho slova, width treba opakovať
cin.width(maxN);
cin >> str3;
cout << "str: \"" << str << "\"" << endl;
cout << "str2: \"" << str2 << "\"" << endl;
cout << "str3: \"" << str3 << "\"" << endl;
}
Príklad behu programu (prvé dva riadky zadal užívateľ, na začiatku a konci každého je medzera)
a b c g h i str: " a b c " str2: "g" str3: "h"
Algoritmy s reťazcami
Prácu s reťazcami si precvičíme na niekoľkých menších príkladoch.
Vyhľadávanie podreťazca
Chceme zistiť, či a kde sa v reťazci nachádza určité slovo alebo iná vzorka.
#include <iostream>
#include <cstring>
using namespace std;
int find(char text[], char pattern[]) {
/* Vráti polohu prvého výskytu reťazca pattern
* v reťazci text, alebo -1 ak sa nevyskytuje. */
int n = strlen(text);
int m = strlen(pattern);
for (int i = 0; i < n - m + 1; i++) {
bool zhoda = true;
for (int j = 0; j < m; j++) {
if (text[i + j] != pattern[j]) {
zhoda = false;
break;
}
}
if (zhoda) {
return i;
}
}
return -1;
}
int main(void) {
const int maxN = 2000;
char A[maxN], B[maxN];
cout << "Zadaj text: ";
cin.getline(A,maxN);
cout << "Zadaj vzorku: ";
cin.getline(B,maxN);
cout << find(A,B) << endl;
}
- Predpočítame si dĺžky a uložíme do premenných, aby sa zbytočne nerátali znova a znova
- Ako by sme zmenili program aby hľadal posledný výskyt namiestoi prvého?
- Vedeli by sme do poľa uložiť polohy všetkých výskytov?
Prevod čísla na reťazec
Máme danú premennú x typu int, chceme ju uložiť v desiatkovej sústave do reťazca.
- Zvyšok po delení 10 je posledná cifra, uložíme si ju do reťazca, vydelíme x desiatimi
- Opakujeme, kým nespracujeme celé číslo.
- Prevod z čísla c (0..9) na cifru: '0'+c
- Nezabudneme na ukončovací znak 0
- Dostaneme číslo v opačnom poradí, napr pre x=12 budeme mať reťazec {'2', '1', 0}
- Preto ešte celé číslo otočíme naopak.
void reverse(char a[]) {
int n = strlen(a);
int i = 0;
int j = n - 1;
while (i < j) {
char tmp = a[i];
a[i] = a[j];
a[j] = tmp;
i++; j--;
}
}
void int2str(int x, char a[]) {
/* prevedie kladne cele cislo x na retazec,
* vysledok ulozi do retazca a, ktory musi mat dost miesta. */
assert(x > 0);
int n = 0;
while(x > 0) {
a[n] = '0' + x % 10;
x /= 10;
n++;
}
a[n] = 0;
/* teraz je cislo naopak, treba otocit */
reverse(a);
}
- Ako upravíme funkciu, aby fungovala aj pre x=0, prípadne záporné x?
- Pozor na rozdiel medzi znakom 0 a '0' (a medzi reťazcom "0")
Formátovanie čísla
- Chceme číslo zapísať do reťazca a doplniť naľavo medzerami na šírku width.
const int maxN = 100;
void formatInt(int x, char A[], int width) {
/* číslo x konvertujeme na reťazec
* a uložíme do poľa A zarované doprava na šírku width */
/* najprv x uložíme do pomocného reťazca B a zrátame jeho dĺžku n */
char B[maxN];
int2str(x, B);
int n = strlen(B);
/* do A dáme width-n medzier a ukončovaciu 0 */
assert(n <= width);
int i;
for (i = 0; i < width - n; i++) {
A[i] = ' ';
}
A[i] = 0;
/* za A prikopírujeme B */
strcat(A, B);
}
- Čo by sa stalo, ak by sme nedali do A ukončovaciu 0?
- Vedeli by ste prepísať program, aby pracoval priamo v poli A (bez poľa B)?
Využijeme na vypísanie pekne zarovnanej tabuľky faktoriálov:
int factorial(int n) {
int result = 1;
for (int i = 1; i <= n; i++) {
result *= i;
}
return result;
}
int main(void) {
char A[maxN];
int n = 12;
for (int i = 1; i <= n; i++) {
int x = factorial(i);
formatInt(i, A, 2);
cout << A << "! = ";
formatInt(x, A, 10);
cout << A << endl;
}
}
1! = 1 2! = 2 3! = 6 4! = 24 5! = 120 6! = 720 7! = 5040 8! = 40320 9! = 362880 10! = 3628800 11! = 39916800 12! = 479001600
Dalo by sa aj jednoduchšie pomocou nastavenia width v cin:
int main(void) {
int n = 12;
for (int i = 1; i <= n; i++) {
int x = factorial(i);
cout.width(2);
cout << i << "! = ";
cout.width(10);
cout << x << endl;
}
}
Zalamovanie riadkov
Pre zaujímavosť: ukážka trochu dlhšieho programu na prácu s textom
- Máme reťazec s nejakým textom, v ktorom sa vyskytujú rôzne biele znaky, napríklad medzery a konce riadkov. Máme danú šírku riadku W, napr. 80 znakov. Úlohou je ho upraviť tak:
- aby na každom riadku bolo najviac W znakov, pričom nový riadok začína tam, kde by už ďalšie slovo presahovalo cez W
- medzi dvoma slovami má byť vždy buď jedna medzera alebo jeden koniec riadku
- predpokladáme, že žiadne slovo nemá viac ako W znakov
Zadavaj text ukonceny prazdnym riadkom. A AA A AAA A A AA AAA AAA A AA AA A Zadaj sirku riadku: 5 Sformatovany odstavec: A AA A AAA A A AA AAA AAA A AA AA A
Zadavaj text ukonceny prazdnym riadkom. Martin Kukucin: Do skoly. Vakacie sa koncia. Ondrej Rybar sa vse zamysli nad marnostou sveta i vsetkeho, co je v nom. Predstupuje mu tu i tu pred oci profesor, ako stoji pred ciernou tabulou, drziac kruzidlo v ruke a demonstruje pamatnu poucku Pytagorovu. A zimomriavky naskakuju na chrbat, lebo s geometriou stoji od pociatku na nohe valecnej. Ani matematika nenie lepsia, menovite odvtedy, co sa do nej vplichtili miesto cisel vsakove litery. Neraz hutal, naco ich ucenci vpustili do matematiky - ved i bez nich je dost strapata: ci sa im malilo cisel a tak preto vsantrocili medzi ne a a b a ci fantazia sa im tak rozihrala, ze prekrocila hranice cisel celych, zlomkov obycajnych i desatinnych i bohvieakych, a zabludila na nivy, kde rastu nestastne litery? ,Uz akokolvek,' huta Ondro, ,litery tam nemaju co hladat. Tazko je uverit, ze a/b = c, lebo nevies, co je a, alebo b.' Zadaj sirku riadku: 50 Sformatovany odstavec: Martin Kukucin: Do skoly. Vakacie sa koncia. Ondrej Rybar sa vse zamysli nad marnostou sveta i vsetkeho, co je v nom. Predstupuje mu tu i tu pred oci profesor, ako stoji pred ciernou tabulou, drziac kruzidlo v ruke a demonstruje pamatnu poucku Pytagorovu. A zimomriavky naskakuju na chrbat, lebo s geometriou stoji od pociatku na nohe valecnej. Ani matematika nenie lepsia, menovite odvtedy, co sa do nej vplichtili miesto cisel vsakove litery. Neraz hutal, naco ich ucenci vpustili do matematiky - ved i bez nich je dost strapata: ci sa im malilo cisel a tak preto vsantrocili medzi ne a a b a ci fantazia sa im tak rozihrala, ze prekrocila hranice cisel celych, zlomkov obycajnych i desatinnych i bohvieakych, a zabludila na nivy, kde rastu nestastne litery? ,Uz akokolvek,' huta Ondro, ,litery tam nemaju co hladat. Tazko je uverit, ze a/b = c, lebo nevies, co je a, alebo b.'
Plán: úlohu si rozdelíme na viac častí
- Prerobíme reťazec tak, aby sme všetky biele znaky nahradili medzerami. Na rozpoznanie bielych znakov použijeme funkciu isspace z knižnice cctype.
- Každý súvislý úsek medzier nahradíme práve jednou medzerou, zmažeme medzery na začiatku a na konci.
- Viac možností na riešenie, napríklad znaky presýpame do nového poľa. My ale použijeme len jedno pole
- Niektoré medzery nahradíme koncom riadku, aby každý riadok mal šírku najviac W.
- Spravíme načítanie a vypísanie.
#include <iostream>
#include <cstring>
#include <cctype>
#include <cassert>
using namespace std;
void simplify(char A[]) {
/* V retazci A nahradi kazdy suvisly usek bielych znakov prave jednou medzerou.
* Na zaciatku a konci retazca nebudu medzery. */
/* prepis hocijake biele znaky na medzeru */
for (int i = 0; A[i] != 0; i++) {
if (isspace(A[i])) {
A[i] = ' ';
}
}
int kam = 0; /* prve este neobsadene miesto */
char prev = ' '; /* predchadzajuci znak */
for (int i = 0; A[i] != 0; i++) {
/* ak nemame viac medzier po sebe, skopirujeme znak */
if (A[i] != ' ' || prev != ' ') {
A[kam] = A[i];
kam++;
}
/* zapamatame si posledny znak */
prev = A[i];
}
/* zrusime pripadnu medzeru na konci */
if (kam > 0 && A[kam - 1] == ' ') {
kam--;
}
/* retazec ukoncime nulou */
A[kam] = 0;
}
bool breakLines(char A[], int width) {
/* Preformatuje odstavec na sirku riadku width, vyhodi zbytocne medzery.
* Dlzka kazdeho slova musi byt najviac width, inak funkcia vrati false */
simplify(A);
int n = strlen(A);
int zac = 0; /* index prveho pismena v riadku */
while (zac < n) {
int kon = zac + width; /* potencialny koniec riadku */
/* ak uz nemame dost pismen na cely riadok */
if (kon > n) {
kon = n;
}
/* ak sme na konci, pridame koniec riadku za koniec retazca */
if (kon == n) {
A[kon] = '\n';
A[kon + 1] = 0;
n++;
} else {
/* ideme späť, kým nenájdeme medzeru */
while (kon > zac && A[kon] != ' ') {
kon--;
}
/* nenašli sme medzeru: slovo bolo príliš dlhé. */
if (kon == zac) {
return false;
}
/* medzeru prepíšeme na koniec riadku */
assert(A[kon]==' ');
A[kon] = '\n';
}
/* za koncom riadku bude novy zaciatok */
zac = kon + 1;
}
return true;
}
int main(void) {
const int maxN = 2000;
char A[maxN];
A[0] = 0;
cout << "Zadavaj text ukonceny prazdnym riadkom." << endl;
while (true) {
/* nacitame jeden riadok */
char tmp[maxN];
cin.getline(tmp, maxN);
/* ak je prazdny, koncime nacitavanie */
if (strcmp(tmp, "") == 0) {
break;
}
/* ak je miesto v poli A, pridame do neho novy riadok */
if (strlen(A) + strlen(tmp) + 2 < maxN) {
strcat(A, tmp);
strcat(A, "\n");
} else {
cout << "Text je prilis dlhy." << endl;
return 1;
}
}
cout << "Zadaj sirku riadku:" << endl;
int width;
cin >> width;
breakLines(A, width);
cout << "Sformatovany odstavec:" << endl;
cout << A;
}
- Akú zložitosť má načítanie vzhľadom na celkový počet načítaných písmen? Dalo by sa zlepšiť?
Zhrnutie
- Reťazec je pole znakov, za posledným znakom reťazca dáme špeciálny znak s kódom 0
- V knižnici cstring sú funkcie na porovnávanie a kopírovanie reťazcov atď. a pomocou cin a cout môžeme reťazce načítavať a vypisovať.
- Ďalšie funkcie si vieme naprogramovať aj sami, zvyčajne jednoduchá práca s poľom
Prednáška 9
Oznamy
Domáca úloha do pondelka
- Časť bodov môžete dostať aj za neúplný program
- Na doplnkových cvičeniach vám môžeme poradiť, ak máte otázky
- Nenechávajte všetku prácu na poslednú chvíľu
Cvičenia
- Dnes pribudne do cvičení ďalší príklad na rekurziu, v piatok bonusová rozcvička za jeden bod
- Študentom, ktorí ešte nepracovali s rekurziou, odporúčame prísť na doplnkové cvičenia v piatok
Klasické úvodné príklady na rekurziu
Rekurzia je metóda, pri ktorej definujeme objekt (funkciu, pojem, . . . ) pomocou jeho samého.
Na začiatok sa pozrieme na klasické príklady algoritmov využívajúcich rekurziu.
Výpočet faktoriálu
Faktoriál prirodzeného čísla n značíme n! a je to súčin všetkých celých čísel od 1 po n. Pre úplnosť 0! definujeme ako 1.
Výpočet pomocou cyklu z prednášky 3:
int factorial(int n) {
int result = 1;
for (int i = 1; i <= n; i++) {
result = result * i;
}
return result;
}
Rekurzívna definícia faktoriálu:
- n! = 1 ak n≤1
- n! = n ⋅ (n-1)! inak
Túto matematickú definíciu môžeme priamočiaro prepísať do rekurzívnej funkcie:
int factorial(int n) {
if (n <= 1) return 1;
else return n * factorial(n-1);
}
Aby sa rekurzia nezacyklila, mali by sme dodržiavať nasledujúce zásady:
- Rekurzívna funkcia musí obsahovať vetvu pre triviálny prípad niektorého vstupu. Táto vetva nebude obsahovať rekurzívne volanie funkcie, ktorú práve definujeme.
- Rekurzívne volanie funkcie by malo mať vhodne redukovaný niektorý vstup, aby sme sa časom dopracovali k triviálnemu prípadu.
Najväčší spoločný deliteľ (Euklidov algoritmus)
Ďalším tradičným príkladom na rekurziu je počítanie najväčšieho spoločného deliteľa.
- Euklidov algoritmus z prednášky 3 bol založený na rovnosti gcd(a,b) = gcd(b, a mod b)
- Tú sme použili v cykle:
int gcd(int a, int b) {
while (b != 0) {
int r = a % b;
a = b;
b = r;
}
return a;
}
Avšak opäť to isté môžeme ešte kratšie a elegantnejšie napísať rekurziou:
int gcd(int a, int b) {
if (b == 0) return a;
else return gcd(b, a % b);
}
Fibonacciho čísla
Nemôžeme vynechať obľúbený rekurzívny príklad - Fibonacciho čísla, ktoré sme videli na prednáške 4. Aj tam sa rekurzia priam pýta, keďže Fibonacciho čísla sú definované rekurzívne:
- F(0)=0
- F(1)=1
- F(n)=F(n-1)+F(n-2) pre n>=2
Z tejto definície vieme opäť urobiť rekurzívnu funkciu jednoducho:
int fib(int n){
if (n == 0) {
return 0;
} else if (n == 1) {
return 1;
} else {
return fib(n - 1) + fib(n - 2);
}
}
Toto je opäť krajšie ako nerekurzívna verzia:
int fibonacci(int n) {
if (n == 0) {
return 0;
} else if (n == 1) {
return 1;
} else {
int F_posledne = 1;
int F_predposledne = 0;
for (int i = 2; i <= n; i++) {
int F_n = F_posledne + F_predposledne;
F_predposledne = F_posledne;
F_posledne = F_n;
}
return F_posledne;
}
}
Binárne vyhľadávanie
Aj binárne vyhľadávanie prvku v utriedenom poli z prednášky 7 sa dá pekne zapísať rekurzívne.
Pôvodná nerekurzívna funkcia vrátila polohu prvku x v poli a alebo hodnotou -1, ak sa tam nenachádzal:
int find(int a[], int n, int x) {
int left = 0, right = n - 1;
while (left <= right) {
int index = (left + right) / 2;
if (a[index] == x) {
return index;
}
else if (a[index] < x) {
left = index + 1;
}
else {
right = index - 1;
}
}
return -1;
}
V rekurzívnej verzii si okraje aktuálneho úseku poľa si v rekurzii posielame ako parametre:
int find(int a[], int left, int right, int x) {
if (left > right) {
return -1;
}
int index = (left + right) / 2;
if (a[index] == x) {
return index;
}
else if (a[index] < x) {
return find(a, index+1, right, x);
}
else {
return find(a, left, index - 1, x);
}
}
Ak chceme vyhľadať x v poli a s n prvkami, voláme find(a, 0, n-1, x).
Na zamyslenie:
- Táto funkcia má dva triviálne (nerekurzívne) prípady. Ktoré?
- Aká veličina klesá v každom rekurzívnom volaní?
Tu je ešte trochu iná verzia binárneho vyhľadávania s niekoľkými rozdielmi:
- vraciame iba či sa x nachádza v poli alebo nie (dalo by sa rozšíriť aj na index)
- pri porovnávaní x a a[index] rozlišujeme iba dva prípady, nie tri
- končíme pri intervale dĺžky 1, nie 0
bool contains (int a[], int left, int right, int x){
if (left == right) {
return (a[left] == x);
}
int index = (left + right) / 2;
if (x <= a[index]) {
return contains(a, left, index, x);
}
else {
return contains(a, index+1, right, x);
}
}
int main() {
const int N = 9;
int a[N] = {1, 5, 7, 12, 45, 55, 72, 95, 103};
cout << contains(a, 0, N-1, 467) << endl;
cout << find(a, 0, N-1, 467) << endl;
}
Zhrnutie
Pri rekurzii vyjadríme riešenie nejakej úlohy pomocou riešenia jednej alebo viacerých úloh toho istého typu, ale s menším vstupom plus ďalšie potrebné nerekurzívne výpočty
- výpočet n! vyjadríme pomocou výpočtu (n-1)! a násobenia
- výpočet gcd(a, b) vyjadríme pomocou výpočtu gcd(b, a % b)
- výpočet F[n] vyjadríme pomocou výpočtu F[n-1] a F[n-2]
- binárne vyhľadávanie v dlhšom intervale vyjadríme pomocou binárneho vyhľadávania v kratšom intervale
Všimnite si, že občas musíme zoznam parametrov nejakej funkcie rozšíriť pre potreby rekurzie
- napr. funkcia find by prirodzene dostávala pole a, dĺžku n a hľadaný prvok, ale kvôli rekurzii potrebuje ľavý a pravý okraj
- pre pohodlie užívateľa môžeme pridať pomocnú funkciu (wrapper):
int find(int a[], int n, int x) {
return find(a, 0, n-1, x);
}
Viac o rekurzii
Nepriama rekurzia
- Všetky doteraz uvedené funkcie sú príkladom priamej rekurzie, kde definovaná funkcia používa seba samú priamo.
- V nepriamej rekurzii funkcia neodkazuje vo svojej definícii priamo na seba, ale využíva inú funkciu, ktorá sa odkazuje naspäť na prvú (všeobecnejšie sa kruh môže uzavrieť na viac krokov).
- Ako príklad uveďme rekurzívne testovanie párnosti a nepárnosti (len ilustračný príklad, párnosť je lepšie testovať pomocou n%2):
// deklaracia funkcie odd, aby sa dala pouzit v even
bool odd(int n);
bool even(int n) {
if (n == 0) return true;
else return odd(n - 1);
}
bool odd(int n) {
if (n == 0) return false;
else return even(n - 1);
}
Rekurzia pomocou zásobníka - ako je rekurzia implementovaná
O rekurzívne volania sa stará zásobník volaní (call stack)
- Ide o všeobecnú štruktúru potrebnú aj v nerekurzívnych programoch s funkciami
- Po zavolaní nejakej funkcie f sa pre ňu vytvorí na zásobníku záznam, ktorý obsahuje všetky lokálne premenné a argumenty funkcie
- Keď potom z funkcie f zavoláme nejakú funkciu g (pričom v rekurzii môže byť aj f=g), tak sa vytvorí nový záznam pre g. Navyše v zázname pre f si uložíme aj to, v ktorom kroku sme prestali s výpočtom, aby sme vedeli správne pokračovať
- Po skončení výpočtu funkcie g sa jej záznam zruší zo zásobníka. Vrátime sa k záznamu pre funkciu f a pokračujeme vo výpočte so správnymi hodnotami všetkých premenných a od správneho miesta.
Záznamy v zásobníku si môžeme predstaviť uložené v stĺpci jeden nad druhým
- vrchný záznam je aktuálny, pre funkciu, ktorá sa vykonáva
- pod ním je záznam pre funkciu, ktorá ju volala atď
- na spodku je záznam pre funkciu main
Teraz si môžeme jednoduchý zásobník odsimulovať napríklad na výpočte faktoriálu.
int factorial(int n) {
if (n < 2) return 1;
else return n * factorial(n-1);
}
Zložitejšie príklady rekurzie
Každý z predchádzajúcich príkladov sme vedeli pomerne jednoducho zapísať aj bez rekurzie, aj keď rekurzívny výpočet bol často prehľadnejší, zrozumiteľnejší, kratší a krajší.
Ukážeme si však aj príklady, ktoré by sa bez rekurzie písali obtiažne (aj keď ako si neskôr ukážeme, rekurzia sa dá vždy odstrániť, v najhoršom prípade simuláciou zásobníka). Príklady, kde rekurzia veľmi pomáha, uvidíme na zvyšku dnešnej prednášky, ale aj na dvoch ďalších a k rekurzii sa vrátime aj neskôr v semestri a samozrejme na ďalších predmetoch.
Odbočka: korytnačia grafika v SVGdraw
Náš prvý dnešný príklad rekurzie budú rekurzívne obrázky, fraktály. Aby sa nám lepšie vykresľovali, v knižnici #SVGdraw je možnosť kresliť pomocou korytnačej grafiky.
- Vytvoríme si virtuálnu korytnačku, ktorá má určitú polohu a natočenie.
- Môžeme jej povedať, aby sa otočila doľava alebo doprava o určitý počet stupňov (turtle.turnLeft(uhol) a turtle.turnRight(uhol)).
- Môžeme jej povedať, aby išla o určitú dĺžku dopredu (turtle.forward(dlzka))
- Keď ide korytnačka dopredu, zanecháva v piesku chvostom čiarku (vykreslí teda čiaru do nášho obrázku).
Napríklad na vykreslenie štvorca s dĺžkou strany 100 môžeme korytnačke striedavo prikazovať ísť o 100 dopredu a otáčať sa o 90 stupňov doľava.
- Na obrázku sa animuje pohyb korytnačky (pozri tu)
- Program by sa dal ľahko rozšíriť na vykresľovanie pravidelného n-uholníka (stačí zmeniť uhol otočenia a počet opakovaní cyklu)
#include "SVGdraw.h"
int main(void) {
/* Vytvor korytnačku na súradniciach (25,175)
* otočenú doprava na obrázku s rozmermi 200x200,
* ktorý bude uložený v súbore stvorec.svg. */
Turtle turtle(200, 200, "stvorec.svg", 25, 175, 0);
for (int i = 0; i < 4; i++) {
// vykresli čiaru dĺžky 150
turtle.forward(150);
// otoč sa doľava o 90 stupňov
turtle.turnLeft(90);
}
/* strany boli vykreslené v poradí
* dolná, pravá, horná, ľavá */
/* Ukonči vypisovanie obrázka. */
turtle.finish();
}
Fraktály
Fraktály sú útvary, ktorých časti na rôznych úrovniach zväčšenia sa podobajú na celý útvar. Mnohé fraktály vieme definovať a vykresliť pomocou jednoduchej rekurzie.
Kochova krivka

Príkladom fraktálu je Kochova krivka. Ako vzniká?
- Predstavme si úsečku, ktorá meria d centimetrov.
- Spravíme s ňou nasledujúcu transformáciu:
- Úsečka sa rozdelí na tretiny a nad strednou tretinou sa zostrojí rovnostranný trojuholník. Základňa trojuholníka v krivke nebude.
- Dostávame tak útvar pozostávajúci zo štyroch úsečiek s dĺžkou d/3
- Tú istú transformáciu môžeme teraz spraviť na každej zo štyroch nových úsečiek, t.j. dostávame 16 úsečiek dĺžky d/9
- Takéto transformácie môžeme robiť do nekonečna
Druhá možnosť je popísať krivku pomocou dvoch parametrov: dĺžka d a stupeň n
- Kochova krivka stupňa 0 je úsečka dĺžky d
- Kochova krivka stupňa n pozostáva zo štyroch kriviek stupňa n-1 a dĺžky n/3
- na presný popis umiestnenia a natočenia týchto kriviek nižšieho stupňa použijeme korytnačiu grafiku, čo máme spravené vo funkcii nižšie.
#include "SVGdraw.h"
void drawKoch(double d, int n, Turtle& turtle){
if (n==0) turtle.forward(d);
else {
drawKoch(d/3, n-1, turtle);
turtle.turnLeft(60);
drawKoch(d/3, n-1, turtle);
turtle.turnRight(120);
drawKoch(d/3, n-1, turtle);
turtle.turnLeft(60);
drawKoch(d/3, n-1, turtle);
}
}
int main(void) {
int width = 310; /* rozmery obrazku */
int height = 150;
double d = 300; /* velkost krivky */
int n = 5; /* stupen krivky */
/* Vytvor korytnačku otočenú doprava. */
Turtle turtle(width, height, "fraktal.svg",
1, height-10, 0);
/* nakresli Kochovu krivku rekurzívne */
drawKoch(d, n, turtle);
/* Schovaj korytnačku. */
turtle.finish();
}
Rekurzívny strom
A ešte jeden príklad fraktálu: strom definovaný nasledovne:
- strom má dva parametre: veľkosť d a stupeň n
- strom stupňa 0 je prázdna množina
- strom stupňa n pozostáva z kmeňa, ktorý tvorí úsečka dĺžky d a z dvoch podstromov, ktoré sú stromy stupňa n-1, veľkosti d/2 a otočené o 30 stupňov doľava a doprava od hlavnej osi stromu (pozri obrázky nižšie)

Strom stupňa 1

Strom stupňa 2
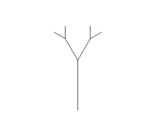
Strom stupňa 3

Strom stupňa 5




Rekurzívnu funkciu na vykresľovanie stromu napíšeme tak, aby sa po skončení vrátila na miesto a otočenie, kde začala
- Bez toho by sa sme nevedeli, kde korytnačka je po vykreslení ľavého podstromu a nemohli by sme teda kresliť pravý
- Korytnačka teda prejde po každej vetve dvakrát, raz smerom dopredu a raz naspäť (animácia)
#include "SVGdraw.h"
void drawTree(double d, int n, Turtle& turtle) {
if (n == 0) {
/* stupen 0 - nerob nic */
return;
} else {
/* kmen stromu */
turtle.forward(d);
turtle.turnLeft(30);
/* lava cast koruny */
drawTree(d / 2, n - 1, turtle);
turtle.turnRight(60);
/* prava cast koruny */
drawTree(d / 2, n - 1, turtle);
turtle.turnLeft(30);
/* navrat na spodok kmena */
turtle.forward(-d);
}
}
int main(void) {
/* rozmery obrazku */
int width = 150;
int height = 200;
/* velkost stromu */
double d = 100;
/* stupen krivky */
int n = 5;
/* vytvor korytnačku otočenú hore */
Turtle turtle(width, height, "fraktal.svg",
width / 2, height - 10, 90);
/* nakresli strom rekurzívne */
drawTree(d, n, turtle);
/* schovaj korytnačku */
turtle.finish();
}
Cvičenie
Ako by sme zistili, čo robí rekurzívna funkcia, napríklad takáto obmena Fibonacciho postupnosti?
int f(int n) {
if (n <= 2) return 1; else return f(n-1) + f(n-3);
}
Prednáška 10
Oznamy
- Dnes 22:00 termín odovzdania DÚ1
- Dnes po prednáške sa objaví zadanie DÚ2
- Zajtrajšia rozcvička bude z dnešnej prednášky
- Tento týždeň neplánujeme na piatok bonusovú rozcvičku, cvičenia sa však budú konať
- Budúci pondelok je sviatok, prednáška nebude
- Budúci utorok prvú polovicu cvičení bude rozcvička na papieri (krátky test podobne ako na prednáške 4.10.).
- Bude zahŕňať učivo po dnešnú prednášku
- Môžete si priniesť ťahák 1 list A4. Používanie počítača nebude povolené.
- Po odovzdaní testu môžete riešiť zadané úlohy na počítači (bude ich menej)
Opakovanie rekurzie
- Rekurzívna definícia: určitý objekt definujeme pomocou menších objektov toho istého typu
- Napr. Fibonacciho čísla F(n) = F(n-1) + F(n-2)
- Nezabudnime na triviálne prípady, napr. F(0)=0, F(1)=1
- Rekurzívne definície vieme často priamočiaro zapísať do rekurzívnych funkcií
int fib(int n){
if (n == 0) {
return 0;
} else if (n == 1) {
return 1;
} else {
return fib(n - 1) + fib(n - 2);
}
}
- V rekurzívnej funkcii riešime problém pomocou menších podproblémov toho istého typu
- Napríklad aby sme našli číslo x v utriedenom poli medzi indexami left a right, potrebujeme ho porovnať so stredným prvkom tohoto intervalu a potom riešiť tú istú úlohu pre menší interval
- Aj keď sme pôvodne chceli hľadať prvok v celom poli, úlohu rozšírime o parametre left a right, aby sa dala spraviť rekurzia
int find(int a[], int left, int right, int x) {
if (left > right) {
return -1;
}
int index = (left + right) / 2;
if (a[index] == x) {
return index;
}
else if (a[index] < x) {
return find(a, index+1, right, x);
}
else {
return find(a, left, index - 1, x);
}
}
Zásobník volaní
Druhý pohľad na rekurziu je dynamický: môžeme simulovať, čo sa v programe deje so zásobníkom volaní (call stack)
- Skúsme napríklad odsimulovať, čo sa deje ak vo funkcii main zavoláme fib(3)
- Kvôli prehľadnosti si fib rozpíšeme na viac riadkov:
#include <iostream>
using namespace std;
int fib(int n) {
if (n == 0) {
return 0;
} else if (n == 1) {
return 1;
} else {
int a = fib(n - 1); // riadok (A)
int b = fib(n - 2); // riadok (B)
return a+b;
}
}
int main() {
int x = fib(3); // riadok (C)
cout << x << endl;
}
Tu je priebeh programu (obsah zásobníka)
(1) (2) (3)
fib n=2
fib n=3 fib n=3, a=?, b=?, riadok A
main, x=? main, x=?, riadok C main, x=?, riadok C
(4) (5)
fib n=1
fib n=2, a=?, b=?, riadok A fib n=2, a=1, b=?, riadok A
fib n=3, a=?, b=?, riadok A fib n=3, a=?, b=?, riadok A
main, x=?, riadok C main, x=?, riadok C
(6) (7)
fib n=0
fib n=2, a=1, b=?, riadok B fib n=2, a=1, b=0, riadok B
fib n=3, a=?, b=?, riadok A fib n=3, a=?, b=?, riadok A
main, x=?, riadok C main, x=?, riadok C
(8) (9)
fib n=1
fib n=3, a=1, b=?, riadok A fib n=3, a=1, b=?, riadok B
main, x=?, riadok C main, x=?, riadok C
(10) (11)
fib n=3, a=1, b=1, riadok B
main, x=?, riadok C main, x=2, riadok C
Postupnosť volaní počas výpočtu vieme znázorniť aj stromovým diagramom:

Pozor, priamočiary rekurzívny zápis výpočtu Fibonacciho čísel je neefektívny, lebo výpočet Fibonacciho čísel sa opakuje
- Napr. pre n=5 počítame fib(2) trikrát, pre n=6 päťkrát a pre n=20 až 4181-krát
Vypisovanie variácií s opakovaním
Vypíšte všetky trojice cifier, pričom každá cifra je z množiny {0..n-1} a cifry sa môžu opakovať (variácie 3-tej triedy z n prvkov). Napr. pre n=2:
000 001 010 011 100 101 110 111
Veľmi jednoduchý program s troma cyklami:
#include <iostream>
using namespace std;
int main() {
int n;
cin >> n;
for(int i=0; i<n; i++) {
for(int j=0; j<n; j++) {
for(int k=0; k<n; k++) {
cout << i << j << k << endl;
}
}
}
}
Rekurzívne riešenie pre všeobecné k
Čo ak chceme k-tice pre všeobecné k? Využijeme rekurziu.
- Variácie k-tej triedy vieme rozdeliť na n skupín podľa prvého prvku:
- tie čo začínajú na 0, tie čo začínajú na 1, ..., tie čo začínajú na n-1.
- V každej skupine ak odoberieme prvý prvok, dostaneme variácie triedy k-1
#include <iostream>
using namespace std;
void vypis(int a[], int k) {
for (int i = 0; i < k; i++) {
cout << a[i];
}
cout << endl;
}
void generuj(int a[], int i, int k, int n) {
/* v poli a dlzky k mame prvych i cifier,
* chceme vygenerovat vsetky moznosti
* poslednych k-i cifier */
if (i == k) {
vypis(a, k);
} else {
for (int x = 0; x < n; x++) {
a[i] = x;
generuj(a, i + 1, k, n);
}
}
}
int main() {
const int maxK = 100;
int a[maxK];
int k, n;
cout << "Zadajte k a n: ";
cin >> k >> n;
generuj(a, 0, k, n);
}
Strom rekurzívnych volaní pre k=3, n=2 (generuj je skrátené na gen, červenou je zobrazený obsah poľa a):

Ďalšie rozšírenia
- Čo ak chceme všetky k-tice písmen A-Z?
- Čo ak chceme všetky DNA reťazce dĺžky k (DNA pozostáva z "písmen" A,C,G,T)?
// pouzi n=26
void vypis(int a[], int k) {
for (int i = 0; i < k; i++) {
char c = 'A'+a[i];
cout << c;
}
cout << endl;
}
// pouzi n=4
void vypis(int a[], int k) {
char abeceda[5] = "ACGT";
for (int i = 0; i < k; i++) {
cout << abeceda[a[i]];
}
cout << endl;
}
Cvičenia
- Ako by sme vypisovali všetky k-ciferné hexadecimálne čísla (šestnástková sústava), kde používame cifry 0-9 a písmená A-F?
- Ako by sme vypisovali všetky k-tice písmen v opačnom poradí, od ZZZ po AAA?
Variácie bez opakovania
Teraz chceme vypísať všetky k-tice cifier z množiny {0, ..., n-1}, v ktorých sa žiaden prvok neopakuje (pre k=n dostávame permutácie)
Príklad pre k=3, n=3
012 021 102 120 201 210
Skúšanie všetkých možností
- Jednoduchá možnosť: použijeme predchádzajúci program a pred výpisom skontrolujeme, či je riešenie správne
Prvý pokus:
bool spravne(int a[], int k, int n) {
/* je v poli a dlzky k kazde cislo
* od 0 po n-1 najviac raz? */
bool bolo[maxN];
for (int i = 0; i < n; i++) {
bolo[i] = false;
}
for (int i = 0; i < k; i++) {
if (bolo[a[i]]) return false;
bolo[a[i]] = true;
}
return true;
}
void generuj(int a[], int i, int k, int n) {
/* v poli a dlzky k mame prvych i cifier,
* chceme vygenerovat vsetky moznosti
* poslednych k-i cifier */
if (i == k) {
if (spravne(a, k, n)) {
vypis(a, k);
}
} else {
for (int x = 0; x < n; x++) {
a[i] = x;
generuj(a, i + 1, k, n);
}
}
}
Cvičenie: ako by sme napísali funkciu spravne, ak by nedostala ako parameter hodnotu n?
Prehľadávanie s návratom, backtracking
- Predchádzajúce riešenie je neefektívne, lebo prechádza cez všetky variácie s opakovaním a veľa z nich zahodí.
- Napríklad pre k=7 a n=10 pozeráme 107 variácií s opakovaním, ale iba 604800 z nich je správnych, čo je asi 6%
- Len čo sa v poli a vyskytne opakujúca sa cifra, chceme túto vetvu prehľadávania ukončiť, lebo doplnením ďalších cifier problém neodstránime
- Spravíme funkciu moze(a,i,x), ktorá určí, či je možné na miesto i v poli a dať cifru x
- Testovanie správnosti vo funkcii generuj sa dá vynechať
bool moze(int a[], int i, int x) {
/* Mozeme dat hodnotu x na poziciu i v poli a?
* Mozeme, ak sa nevyskytuje v a[0..i-1] */
for (int j = 0; j < i; j++) {
if (a[j] == x) return false;
}
return true;
}
void generuj(int a[], int i, int k, int n) {
/* v poli a dlzky k mame prvych i cifier,
* chceme vygenerovat vsetky moznosti
* poslednych k-i cifier */
if (i == k) {
vypis(a, k);
} else {
for (int x = 0; x < n; x++) {
if (moze(a, i, x)) {
a[i] = x;
generuj(a, i + 1, k, n);
}
}
}
}
Možné zrýchlenie: vytvoríme trvalé pole bolo, v ktorom bude zaznamené, ktoré cifry sa už vyskytli a to použijeme namiesto funkcie moze.
- Po návrate z rekurzie nesmieme zabudúť príslušnú hodnotu odznačiť!
void generuj(int a[], bool bolo[], int i, int k, int n) {
/* v poli a dlzky k mame prvych i cifier,
* v poli bolo su zaznamenane pouzite cifry,
* chceme vygenerovat vsetky moznosti
* poslednych k-i cifier */
if (i == k) {
vypis(a, k);
} else {
for (int x = 0; x < n; x++) {
if (!bolo[x]) {
a[i] = x;
bolo[x] = true;
generuj(a, bolo, i + 1, k, n);
bolo[x] = false;
}
}
}
}
int main() {
const int maxK = 100;
const int maxN = 100;
int a[maxK];
bool bolo[maxN];
int k, n;
cout << "Zadajte k a n (k<=n): ";
cin >> k >> n;
for (int i = 0; i < n; i++) {
bolo[i] = false;
}
generuj(a, bolo, 0, k, n);
}
Cvičenie: ako potrebujeme zmeniť program, aby sme generovali všetky postupnosti k cifier z množiny {0,..,n-1}, také, že z každej cifry sú v postupnosti najviac 2 výskyty?
Technika rekurzívneho prehľadávania všetkých možností s orezávaním beznádejných vetiev sa nazýva prehľadávanie s návratom alebo backtracking.
- Hľadáme všetky postupnosti, ktoré spĺňajú nejaké podmienky
- Vo všeobecnosti nemusia byť rovnako dlhé
- Ak máme celú postupnosť, vieme otestovať, či spĺňa podmienku (funkcia spravne)
- Ak máme časť postupnosti a nový prvok, vieme otestovať, či po pridaní tohto prvku má ešte šancu tvoriť časť riešenia (funkcia moze)
- Funkcia moze nesmie vrátiť false, ak ešte je možné riešenie
- Môže vrátiť true, ak už nie je možné riešenie, ale nevie to ešte odhaliť
- Snažíme sa však odhaliť problém čím skôr
Všeobecná schéma
void generuj(int a[], int i) {
/* v poli a dlzky k mame prvych i cisel z riesenia */
if (spravne(a, i)) {
/* ak uz mame cele riesenie, vypiseme ho */
vypis(a, i);
} else {
pre vsetky hodnoty x {
if (moze(a,i,x)) {
a[i] = x;
generuj(a, i + 1);
}
}
}
}
Prehľadávanie s návratom môže byť vo všeobecnosti veľmi pomalé, čas výpočtu exponenciálne rastie.
Generovanie všetkých podmnožín
Chceme vypísať všetky podmnožiny množiny {0,..,m-1}. Na rozdiel od variácií nám v podmnožine nezáleží na poradí (napr. {0,1} = {1,0}), prvky teda budeme vždy vypisovať od najmenšieho po najväčší. Napr. pre m=2 máme podmnožiny
{}
{0}
{1}
{0,1}
Podmnožinu vieme vyjadriť ako binárne pole dĺžky m,
- a[i]=0 znamená, že i nepatrí do množiny a a[i]=1 znamená, že patrí.
- Napríklad podmnožinu {0,2,3} množiny {0,1,2,3,4} sa zapíše ako pole 1,0,1,1,0.
Teda môžeme použiť predchádzajúci program pre n=2, k=m a zmeniť iba výpis:
void vypis(int a[], int m) {
cout << "{";
bool prve = true;
for (int i = 0; i < m; i++) {
if (a[i] == 1) {
if (prve) {
cout << "" << i;
prve=false;
} else {
cout << "," << i;
}
}
}
cout << "}" << endl;
}
- V premennej prve si pamätáme, či máme oddeliť ďalšie vypisované číslo od predchádzajúceho.
- Ak ešte žiadne nebolo, oddeľovač je prázdny reťazec.
- Ak už sme niečo vypísali, oddeľovač je čiarka.
Namiesto poľa intov môžeme použiť pole boolovských hodnôt a celý program trochu prispôsobiť tomu, že generujeme podmnožiny:
#include <iostream>
#include <cstring>
using namespace std;
void vypis(bool a[], int m) {
cout << "{";
bool prve = true;
for (int i = 0; i < m; i++) {
if (a[i]) {
if (prve) {
cout << "" << i;
prve=false;
} else {
cout << "," << i;
}
}
}
cout << "}" << endl;
}
void generuj(bool a[], int i, int m) {
/* v poli a dlzky k mame rozhodnutie o prvych i
* prvkoch, chceme vygenerovat vsetky podmnoziny
* prvkov {i..m-1} */
if (i == m) {
vypis(a, m);
} else {
a[i] = true;
generuj(a, i + 1, m);
a[i] = false;
generuj(a, i + 1, m);
}
}
int main() {
const int maxM = 100;
int m;
cin >> m;
bool a[maxM];
generuj(a, 0, m);
}
Pre n=3 program vypíše:
{0,1,2}
{0,1}
{0,2}
{0}
{1,2}
{1}
{2}
{}
Cvičenie: Čo by program vypísal, ak by sme prehodili true a false v rekurzii?
Generovanie podmnožín využijeme na budúcej prednáške na riešenie problému batoha, čo je jeden z dôležitých praktických problémov, pre ktoré nepoznáme efektívne algoritmy.
Problém 8 dám
Prehľadávanie s návratom sa dá využiť aj na riešenie rôznych hlavolamov. Tu si ukážeme jeden z nich. Program nebol podrobnejšie rozberaný na prednáške, tu je uvedený pre záujemcov.
Cieľom je rozmiestniť n dám na šachovnici nxn tak, aby sa žiadne dve navzájom neohrozovali, tj. aby žiadne dve neboli v rovnakom riadku, stĺpci, ani na rovnakej uhlopriečke.
Príklad pre n=4:
. * . . . . . * * . . . . . * .
- V každom riadku bude práve jedna dáma, teda riešenie môžeme reprezentovať ako pole damy dĺžky n, kde damy[i] je stĺpec, v ktorom je dáma na riadku i
- Príklad vyššie by v poli damy mal čísla 1,3,0,2
- Podobne ako pri generovaní variácií bez opakovania chceme do poľa dať čísla od 1 po n, aby spĺňali ďalšie podmienky (v každom stĺpci a na každej uhlopriečke najviac 1 dáma)
- Vytvoríme polia, kde si pre každý stĺpec a uhlopriečku pamätáme, či už je obsadená
- Uhlopriečky v oboch smeroch očíslujeme číslami od 0 po 2n-2
- V jednom smere majú miesta na uhlopriečke rovnaký súčet, ten teda bude číslom uhlopriečky
- V druhom smere majú rovnaký rozdiel, ten však môže byť aj záporný, pričítame n-1
- Podobne ako pri problému batoha, aj tu použijeme niekoľko globálnych premenných


#include <iostream>
using namespace std;
/* globalne premenne */
const int maxN = 100;
int n;
int damy[maxN]; /* damy[i] je stlpec s damou v riadku i*/
bool bolStlpec[maxN]; /* bolStlpec[i] je true ak stlpec i obsadeny */
/* polia ktore obsahuju true ak uhlopriecky obsadene */
bool bolaUhl1[2 * maxN - 1];
bool bolaUhl2[2 * maxN - 1];
int pocet; /* pocet najdenych rieseni */
int uhl1(int i, int j) {
/* na ktorej uhlopriecke je riadok i, stlpec j v smere 1? */
return i + j;
}
int uhl2(int i, int j) {
/* na ktorej uhlopriecke je riadok i, stlpec j v smere 2? */
return n - 1 + i - j;
}
void vypis() {
/* vypis sachovnicu textovo a zvys pocitadlo rieseni */
pocet++;
for (int i = 0; i < n; i++) {
for (int j = 0; j < n; j++) {
if (damy[i] == j) cout << " *";
else cout << " .";
}
cout << endl;
}
cout << endl;
}
void generuj(int i) {
/* v poli damy mame prvych i dam, dopln dalsie */
if (i == n) {
vypis();
} else {
for (int j = 0; j < n; j++) {
/* skus dat damu na riadok i, stlpec j */
if (!bolStlpec[j]
&& !bolaUhl1[uhl1(i, j)]
&& !bolaUhl2[uhl2(i, j)]) {
damy[i] = j;
bolStlpec[j] = true;
bolaUhl1[uhl1(i, j)] = true;
bolaUhl2[uhl2(i, j)] = true;
generuj(i + 1);
bolStlpec[j] = false;
bolaUhl1[uhl1(i, j)] = false;
bolaUhl2[uhl2(i, j)] = false;
}
}
}
}
int main() {
cout << "Zadajte velkost sachovnice: ";
cin >> n;
for (int i = 0; i < n; i++) {
bolStlpec[i] = false;
}
for (int i = 0; i < 2 * n + 1; i++) {
bolaUhl1[i] = false;
bolaUhl2[i] = false;
}
/* rekuzia */
pocet = 0;
generuj(0);
cout << "Pocet rieseni: " << pocet << endl;
}
Zhrnutie
- Videli sme ako rekurzívne generovať všetky postupnosti spĺňajúce určité požiadavky
- Ak máme špeciálne požiadavky, napr. že žiadne číslo sa neopakuje, môžeme buď generovať všetky k-tice a testovať to pred výpisom, alebo už počas generovania urezávať neperspektívne vetvy výpočtu, čo je rýchlejšie
- Táto technika sa volá prehľadávanie s návratom (backtracking)
- Pozor, čas výpočtu prudko (exponenciálne) rastie s dĺžkou postupností, takže vhodné len pre malé vstupy.
- Dve ukážky: problém batoha, problém 8 dám.
Prednáška 11
Oznamy
- DÚ2 je zverejnená, odovzdávajte do pondelka 15.11. 22:00
- Budúci pondelok je sviatok, prednáška nebude
- Budúci utorok prvú polovicu cvičení bude rozcvička na papieri (krátky test podobne ako na prednáške 4.10.).
- Bude zahŕňať učivo po prednášku 10
- Môžete si priniesť ťahák 1 list A4. Používanie počítača nebude povolené.
- Po odovzdaní testu môžete riešiť zadané úlohy na počítači (bude ich menej)
- Plán na dnes: najskôr si ukážeme dva rekurzívne algoritmy na triedenie, potom sa vrátime k minulej téme prehľadávania s návratom.
Rýchle triedenia prostredníctvom paradigmy „rozdeľuj a panuj”
Doposiaľ sme prebrali tri triediace algoritmy: Bubble Sort, Insertion Sort a Max Sort. Všetky sú jednoduché, ale pomalé: majú kvadratickú zložitosť O(n2).
Dnes pridáme ďalšie dve triedenia, ktoré budú pre veľké polia omnoho rýchlejšie: Merge Sort a Quick Sort. Obe sú založené na paradigme rozdeľuj a panuj (angl. divide and conquer, lat. divide et impera).
Rozdeľuj a panuj je paradigma rekurzívneho riešenia problémov pracujúca v troch fázach:
- Rozdeľuj – problém rozdelíme na menšie časti (t.j. podproblémy), ktoré sa dajú riešiť samostatne.
- Vyrieš podproblémy – rekurzívne vyriešime úlohu pre každý podproblém.
- Panuj – riešenia podproblémov spojíme do riešenia pôvodného problému.
Triedenie zlučovaním (Merge Sort)
Triedenie zlučovaním (angl. Merge Sort) pracuje nasledovne:
- Pole rozdelíme na dve približne rovnaké časti
- Každú časť zvlášť rekurzívne utriedime
- Vo fáze „panuj” sa tieto dve utriedené postupnosti zlúčia (angl. merge) do výsledného utriedeného poľa.
Triedenie zlučovaním tak bude vyzerať nasledovne (pričom zostáva doimplementovať funkciu merge):
void mergesort(int a[], int left, int right) {
/* Funkcia utriedi prvky pola a[] od indexu left po index right (vratane). */
/* Trivialne pripady: */
if (left >= right) {
return;
}
/* Rozdeluj -- spocitaj priblizny stred triedeneho useku: */
int middle = (left + right) / 2;
/* Rekurzivne vyries podproblemy: */
mergesort(a, left, middle);
mergesort(a, middle + 1, right);
/* Panuj -- zluc obe utriedene casti do jednej: */
merge(a, left, middle, right);
}
Zlúčenie dvoch utriedených podpostupností
Zostáva doprogramovať zlúčenie dvoch utriedených podpostupností a[left..middle], a[middle+1..right] do jednej utriedenej postupnosti. Zlúčenú postupnosť budeme postupne ukladať do pomocného poľa aux, pričom postupovať budeme nasledovne:
- Prvým prvkom poľa aux bude menší z prvkov a[left] a a[middle+1].
- Ostanú nám postupnosti a[left+1..middle] a a[middle+1..right] alebo a[left..middle] a a[middle+2..right].
- Vo všeobecnosti máme postupnosti a[i..middle] a a[j..right].
- Ďalším prvkom poľa aux bude menčí z prvkov a[i] a a[j]
- Ostanú nám postupnosti a[i+1..middle] a a[j..right] alebo a[i..middle] a a[j+1..right].
- Toto robíme dovtedy, kým niektorú z postupností nevyčerpáme celú. Potom už len na koniec poľa aux dokopírujeme zvyšok druhej postupnosti.
Po spojení oboch postupností do utriedeného poľa aux toto pole prekopírujeme naspäť do poľa a.
void merge(int a[], int left, int middle, int right) {
int aux[maxN];
int i = left; // index v prvej postupnosti
int j = middle + 1; // index v druhej postupnosti
int k = 0; // index v poli aux
while (i <= middle && j <= right) {
// Kym su obe postupnosti a[i..middle], a[j..right] neprazdne,
// mensi z prvkov a[i], a[j] uloz do aux[k] a posun indexy
if (a[i] <= a[j]) {
aux[k] = a[i];
i++;
k++;
} else {
aux[k] = a[j];
j++;
k++;
}
}
while (i <= middle) {
// Ak nieco ostalo v prvej postupnosti, dokopiruj ju na koniec
aux[k] = a[i];
i++;
k++;
}
while (j <= right) {
// Ak nieco ostalo v druhej postupnosti, dokopiruj ju na koniec
aux[k] = a[j];
j++;
k++;
}
for (int t = left; t <= right; t++) {
// Prekopiruj pole aux naspat do pola a
a[t] = aux[t - left];
}
}
Výsledný program
#include <iostream>
using namespace std;
const int maxN = 1000;
void merge(int a[], int left, int middle, int right) {
int aux[maxN];
int i = left;
int j = middle + 1;
int k = 0;
while (i <= middle && j <= right) {
if (a[i] <= a[j]) {
aux[k] = a[i];
i++;
k++;
} else {
aux[k] = a[j];
j++;
k++;
}
}
while (i <= middle) {
aux[k] = a[i];
i++;
k++;
}
while (j <= right) {
aux[k] = a[j];
j++;
k++;
}
for (int t = left; t <= right; t++) {
a[t] = aux[t - left];
}
}
void mergesort(int a[], int left, int right) {
if (left >= right) {
return;
}
int middle = (left + right) / 2;
mergesort(a, left, middle);
mergesort(a, middle+1, right);
merge(a, left, middle, right);
}
int main() {
int N;
int a[maxN];
cout << "Zadaj pocet cisel: ";
cin >> N;
cout << "Zadaj " << N << " cisel: ";
for (int i = 0; i < N; i++) {
cin >> a[i];
}
mergesort(a,0,N-1);
cout << "Utriedene cisla:";
for (int i = 0; i < N; i++) {
cout << " " << a[i];
}
cout << endl;
}
Ukážka na príklade
Uvažujme pole a = {6, 1, 5, 7, 2, 4, 8, 9, 3, 0}.
Volanie mergesort(a,0,9) potom utriedi pole a pomocou nasledujúcich rekurzívnych volaní (mergesort(a,l,h) je na obrázku skrátené na sort(l,h) a merge(a,l,m,h) na merge(l,m,h), žltou sú vyznačené pozície v poli, ktoré sa v danom volaní triedia):

Pole a sa počas týchto volaní mení nasledovne:
merge(a,0,0,1): |6|1|5 7 2 4 8 9 3 0 -> |1 6|5 7 2 4 8 9 3 0 merge(a,0,1,2): |1 6|5|7 2 4 8 9 3 0 -> |1 5 6|7 2 4 8 9 3 0 merge(a,3,3,4): 1 5 6|7|2|4 8 9 3 0 -> 1 5 6|2 7|4 8 9 3 0 merge(a,0,2,4): |1 5 6|2 7|4 8 9 3 0 -> |1 2 5 6 7|4 8 9 3 0 merge(a,5,5,6): 1 2 5 6 7|4|8|9 3 0 -> 1 2 5 6 7|4 8|9 3 0 merge(a,5,6,7): 1 2 5 6 7|4 8|9|3 0 -> 1 2 5 6 7|4 8 9|3 0 merge(a,8,8,9): 1 2 5 6 7 4 8 9|3|0| -> 1 2 5 6 7 4 8 9|0 3| merge(a,5,7,9): 1 2 5 6 7|4 8 9|0 3| -> 1 2 5 6 7|0 3 4 8 9| merge(a,0,4,9): |1 2 5 6 7|0 3 4 8 9| -> |0 1 2 3 4 5 6 7 8 9|
Odhad zložitosti
Zlučovanie dvoch postupností, ktoré spolu obsahujú N prvkov, trvá čas O(N). Prečo?
V algoritme máme log2 N úrovní rekurzie:
- na prvej spracovávame úseky dĺžky N,
- na druhej N/2, na tretej N/4 atď,
- po log2 N úrovniach dostaneme úseky dĺžky 1.
Na každej úrovni je každý prvok najviac v jednom zlučovaní, teda celkový čas zlučovaní na každej úrovni je O(N). Celkový čas výpočtu je O(N log N).
Quick Sort
Quick Sort je tiež založený na metóde rozdeľuj a panuj. Postupuje ale nasledovne:
- V rámci fázy rozdeľuj vyberie niektorý prvok poľa (napríklad jeho prvý prvok), ktorý nazve pivotom. Prvky poľa následne preusporiada na tri skupiny: v ľavej časti poľa budú prvky menšie ako pivot, za nimi pivot samotný a napokon v pravej časti prvky väčšie alebo rovné ako pivot.
- Rekurzívne utriedi prvú a tretiu skupinu (druhá skupina má iba jeden prvok)
- Vo fáze panuj už potom nemusí robiť nič – po utriedení spomínaných dvoch skupín totiž vznikne utriedené pole.
Základ triedenia tak bude vyzerať nasledovne (pričom zostáva implementovať funkciu partition):
void quicksort(int a[], int left, int right) {
/* Utriedi cast pola a[] od indexu left po index right (vratane) */
/* Trivialne pripady: */
if (left >= right) {
return;
}
/* Rozdel pole na tri podpostupnosti: */
int middle = partition(a, left, right);
// Po vykonani funkcie:
// a[left..middle-1] su mensie ako pivot
// a[middle] je pivot
// a[middle+1..right] su vacsie ako pivot
/* Rekurzivne utried a[left..middle-1], a[middle+1..right]: */
quicksort(a, left, middle-1);
quicksort(a, middle+1, right);
}
Funkcia partition
Funkcia partition na vstupe dostane pole a spolu s hraničnými indexami left a right. Prvok a[left] vyberie ako pivot a postupnosť a[left..right] preusporiada tak, aby pre nejakú hodnotu middle takú, že left <= middle <= right platilo nasledovné:
- Prvky a[left],...,a[middle-1] sú menšie, než pivot.
- Prvok a[middle] je pivot.
- Prvky a[middle+1],...,a[right] sú väčšie alebo rovné ako pivot.
Hodnotu middle potom funkcia partition vráti ako svoj výstup.
Funkcia partition udržiava nasledujúce invarianty:
- Prvok a[left] je pivot.
- Prvky a[left+1],...,a[lastSmaller] sú menšie ako pivot.
- Prvky a[lastSmaller+1],...,a[unknown-1] sú väčšie alebo rovné ako pivot.
- Prvky a[unknown],...,a[right] sa ešte s pivotom neporovnávali.
Funkcia partition zakaždým porovnáva prvok a[unknown] s pivotom:
- Ak je menší ako pivot, je nutné „presunúť ho doľava”; vymení ho teda s a[lastSmaller+1] a hodnotu lastSmaller zvýši o jedna.
- Ak je väčší alebo rovný ako pivot, môže ostať na svojom mieste.
Následne zvýši index unknown o jedna a tento postup opakuje, až kým prejde cez všetky prvky danej časti poľa.
Nakoniec je ešte nutné vymeniť a[left] s a[lastSmaller], čím sa pivot dostane na svoje miesto.
void swap (int &x, int &y) {
int tmp = x;
x = y;
y = tmp;
}
int partition(int a[], int left, int right) {
// Ak za pivot chceme zvolit iny prvok, vymenime ho najprv s a[left]
int pivot = a[left];
int lastSmaller = left;
for (int unknown = left + 1; unknown <= right; unknown++) {
if (a[unknown] < pivot) {
lastSmaller++;
swap(a[unknown], a[lastSmaller]);
}
}
swap(a[left],a[lastSmaller]);
return lastSmaller;
}
Výsledný program
#include <iostream>
using namespace std;
const int maxN = 1000;
void swap (int &x, int &y) {
int tmp = x;
x = y;
y = tmp;
}
int partition(int a[], int left, int right) {
int pivot = a[left];
int lastSmaller = left;
for (int unknown = left + 1; unknown <= right; unknown++) {
if (a[unknown] < pivot) {
lastSmaller++;
swap(a[unknown], a[lastSmaller]);
}
}
swap(a[left],a[lastSmaller]);
return lastSmaller;
}
void quicksort(int a[], int left, int right) {
if (left >= right) {
return;
}
int middle = partition(a, left, right);
quicksort(a, left, middle-1);
quicksort(a, middle+1, right);
}
int main() {
int N;
int a[maxN];
cout << "Zadaj pocet cisel: ";
cin >> N;
cout << "Zadaj " << N << " cisel: ";
for (int i = 0; i <= N-1; i++) {
cin >> a[i];
}
quicksort(a,0,N-1);
cout << "Utriedene cisla:";
for (int i = 0; i <= N-1; i++) {
cout << " " << a[i];
}
cout << endl;
}
Ukážka na príklade
Opäť uvažujme pole a = {6, 1, 5, 7, 2, 4, 8, 9, 3, 0}.
Volanie quicksort(0,9) potom utriedi pole a pomocou nasledujúcich rekurzívnych volaní (namiesto quicksort(a,l,h) píšeme zakaždým len sort(l,h)):
sort(0,9) sort(0,5) sort(0,-1)
. sort(1,5) sort(1,0)
. . sort(2,5) sort(2,4) sort(2,2)
. . . . sort(4,4)
. . . sort(6,5)
sort(7,9) sort(7,8) sort(7,7)
. sort(9,8)
sort(10,9)
Volania funkcie partition sú počas tohto behu nasledovné:
partition(a,0,9): |6 1 5 7 2 4 8 9 3 0| -> |0 1 5 2 4 3|6|9 7 8| partition(a,0,5): |0 1 5 2 4 3|6 9 7 8 -> |0|1 5 2 4 3|6 9 7 8 partition(a,1,5): 0|1 5 2 4 3|6 9 7 8 -> 0|1|5 2 4 3|6 9 7 8 partition(a,2,5): 0 1|5 2 4 3|6 9 7 8 -> 0 1|3 2 4|5|6 9 7 8 partition(a,2,4): 0 1|3 2 4|5 6 9 7 8 -> 0 1|2|3|4|5 6 9 7 8 partition(a,7,9): 0 1 2 3 4 5 6|9 7 8| -> 0 1 2 3 4 5 6|8 7|9| partition(a,7,8): 0 1 2 3 4 5 6|8 7|9 -> 0 1 2 3 4 5 6|7|8|9
Cvičenie:
- Ako sa bude Quick Sort správať, keď na vstupe dostane už utriedené pole?
- Ako sa bude správať, keď na vstupe dostane zostupne utriedené pole?
Odhad zložitosti
V ideálnom prípade pivot rozdelí pole na dve rovnako veľké časti. Vtedy je čas výpočtu O(N log N), podobne ako pre Mergesort.
Nepríjemné je, keď pivot je vždy najmenší alebo najväčší prvok v danom úseku. Vtedy je čas O(N2).
- Aby sme sa vyhli problémom, v praxi sa ako pivot často vyberá náhodný prvok z intervalu.
Iná implementácia
Občas sa možno stretnúť aj s nasledujúcou implementáciou triedenia Quick Sort. Skúste samostatne odôvodniť jej správnosť.
void quicksort(int a[], int left, int right) {
if (left >= right) {
return;
}
/* partition */
int pivot = a[(left + right)/2];
int i = left;
int j = right;
while (i <= j) {
while (a[i] < pivot) i++;
while (a[j] > pivot) j--;
if (i <= j) {
swap(a[i],a[j]);
i++; j--;
}
}
/* rekurzia */
quicksort(a, left, j);
quicksort(a, i, right);
}
Triediace algoritmy: zhrnutie
Jednoduché triedenia: Bubble Sort, Insertion Sort, Max Sort.
- Jednoduché, ale pomalé: zložitosť O(n2).
Rekurzívne triedenia založené na technike rozdeľuj a panuj.
- Rýchlejšie, zložitejšie.
- Merge Sort: zložitosť O(n log n).
- Quick Sort: zložitosť O(n2) v najhoršom prípade, pre väčšinu vstupov O(n log n), väčšinou rýchlejší ako Merge Sort.
Reálnu rýchlosť triedení na náhodne zvolenom veľkom vstupe možno porovnať napríklad nasledujúcim programom:
#include <iostream>
#include <cstdlib>
#include <ctime>
using namespace std;
const int maxN = 100000;
void insertionsort(int a[], int n) {
for (int i = 1; i < n; i++) {
int prvok = a[i];
int kam = i;
while (kam > 0 && a[kam - 1] > prvok) {
a[kam] = a[kam - 1];
kam--;
}
a[kam] = prvok;
}
}
void merge(int a[], int left, int mid, int right) {
int aux[maxN];
int i = left;
int j = mid + 1;
int k = 0;
while ((i <= mid) && (j <= right)) {
if (a[i] <= a[j]) {
aux[k] = a[i];
i++;
k++;
} else {
aux[k] = a[j];
j++;
k++;
}
}
while (i <= mid) {
aux[k] = a[i];
i++;
k++;
}
while (j <= right) {
aux[k] = a[j];
j++;
k++;
}
for (int k = left; k <= right; k++) {
a[k] = aux[k - left];
}
}
void mergesort(int a[], int left, int right) {
if (left >= right) {
return;
}
int mid = (left + right) / 2;
mergesort(a, left, mid);
mergesort(a, mid + 1, right);
merge(a, left, mid, right);
}
void swap(int &x, int &y) {
int tmp = x;
x = y;
y = tmp;
}
int partition(int a[], int left, int right) {
int pivot = a[left];
int lastSmaller = left;
for (int unknown = left + 1; unknown <= right; unknown++) {
if (a[unknown] < pivot) {
lastSmaller++;
swap(a[unknown], a[lastSmaller]);
}
}
swap(a[left], a[lastSmaller]);
return lastSmaller;
}
void quicksort(int a[], int left, int right) {
if (left >= right) {
return;
}
int mid = partition(a, left, right);
quicksort(a, left, mid - 1);
quicksort(a, mid + 1, right);
}
int main() {
int N;
int a1[maxN];
int a2[maxN];
int a3[maxN];
cout << "Zadaj pocet nahodnych cisel v poli: ";
cin >> N;
srand(time(NULL));
for (int i = 0; i <= N - 1; i++) {
a1[i] = rand() % 1000;
a3[i] = a2[i] = a1[i];
}
clock_t start1, end1, start2, end2, start3, end3;
start1 = clock();
insertionsort(a1, N);
end1 = clock();
start2 = clock();
mergesort(a2, 0, N - 1);
end2 = clock();
start3 = clock();
quicksort(a3, 0, N - 1);
end3 = clock();
cout << "Insertion sort: "
<< (end1 - start1) * 1.0 / CLOCKS_PER_SEC << " CPU sekund" << endl;
cout << "Merge sort: "
<< (end2 - start2) * 1.0 / CLOCKS_PER_SEC << " CPU sekund" << endl;
cout << "Quick sort: "
<< (end3 - start3) * 1.0 / CLOCKS_PER_SEC << " CPU sekund" << endl;
}
Pre N = 100000 môžeme dostať napríklad nasledujúci výstup (líši sa od počítača k počítaču a od volania k volaniu):
Insertion sort: 7.474 CPU sekund Merge sort: 0.076 CPU sekund Quick sort: 0.032 CPU sekund
Problém batoha (Knapsack problem)
Dnes sme videli ako použiť rekurziu v rýchlych algoritmoch, teraz sa však vráťme k prehľadávaniu s návratom z minulej prednášky, čo je pomalá metóda pre prípady, keď nepoznáme lepší algoritmus.
Metódu prehľadávania s návratom využijeme na riešenie problému batoha. Ide o dôležitý problém, s ktorým sa ešte počas štúdia stretnete. Predstaviť si ho môžeme napríklad takto:
- Zlodej sa vlúpal do obchodu, v ktorom našiel niekoľko predmetov.
- Pozná cenu aj hmotnosť predmetov.
- Z obchodu dokáže odniesť iba lup nepresahujúci nosnosť svojho batoha.
- Ktoré predmety má zlodej odcudziť, aby ich celková hmotnosť nepresahovala nosnosť batoha a aby odišiel s čo najcennejším lupom?
Vstup nášho programu bude vyzerať napríklad nejako takto:
Zadaj pocet predmetov v obchode: 3 Zadaj hmotnost a cenu predmetu 1: 5 9 Zadaj hmotnost a cenu predmetu 2: 4 6 Zadaj hmotnost a cenu predmetu 3: 4 4 Zadaj nosnost batoha: 8
Výstup programu na horeuvedenom vstupe potom bude takýto:
Zober nasledujuce predmety: 2 3 Celkova hodnota lupu: 10
Pri reálnom použití nosnosť batoha môže reprezentovať dostupné zdroje, napr. výpočtový čas na serveri, dostupných pracovníkov, veľkosť rozpočtu a pod, a predmety sú potenciálne úlohy, z ktorých si chceme vybrať podmnožinu, ktorú by sme s danými zdrojmi vedeli vykonať a dosiahnuť čo najvyšší zisk alebo iný ukazovateľ.
Prvé riešenie: preskúmanie všetkých podmnožín
- Preskúmame všetky podmnožiny množiny predmetov v obchode, čiže všetky potenciálne lupy.
- Na to upravíme program generujúci všetky podmnožiny danej množiny.
- Pre každú podmnožinu namiesto výpisu spravíme nasledovné:
- Spočítame celkovú hmotnosť a cenu nájdeného potenciálneho lupu.
- Ak hmotnosť tohto lupu nepresahuje nosnosť batoha, porovnáme jeho cenu s najlepším doposiaľ nájdeným lupom.
- Ak je cennejší, ako doposiaľ najlepší lup, ide o nového kandidáta na optimálny lup a zapamätáme si ho.
- Pre jednoduchosť použijeme v programe globálne premenné, lebo potrebujeme veľa údajov
- Globálne premenné spôsobujú problémy vo väčších programoch: mená premenných sa môžu "biť", môžeme si omylom prepísať číslo dôležité v inej časti programu
- Mohli by sme si tiež spraviť struct obsahujúci všetky premenné potrebné v rekurzii a odovzdávať si ten
Podmnožiny budeme reprezentovať poľom typu bool, v ktorom si pre každý predmet pamätáme, či do danej podmnožiny patrí.
#include <iostream>
using namespace std;
const int maxN = 100;
/* Struktura reprezentujuca jeden predmet */
struct predmet {
int hmotnost;
int cena;
};
/* Globalne premenne pouzivane v rekurzii: */
// pocet predmetov v obchode
int N;
// pole s udajmi o jednotlivych predmetoch
predmet a[maxN];
// nosnost batoha
int nosnost;
// najcennejsi doposial najdeny lup
bool najlepsiLup[maxN];
// jeho cena (kazdy lup bude urcite cennejsi ako -1)
int cenaNajlepsiehoLupu = -1;
int spocitajHmotnostLupu(bool lup[]) {
int hmotnost = 0;
for (int i = 0; i < N; i++) {
if (lup[i]) {
hmotnost += a[i].hmotnost;
}
}
return hmotnost;
}
int spocitajCenuLupu(bool lup[]) {
int cena = 0;
for (int i = 0; i < N; i++) {
if (lup[i]) {
cena += a[i].cena;
}
}
return cena;
}
void vypisLup(bool lup[]) {
cout << "Zober nasledujuce predmety:";
for (int i = 0; i < N; i++) {
if (lup[i]) {
cout << " " << i + 1;
}
}
cout << endl;
}
/* Generovanie vsetkych moznych lupov (podmnozin predmetov) */
void generujLupy(bool lup[], int index) {
/* V poli lup[] dlzky N postupne generujeme podmnoziny.
O hodnotach lup[0],...,lup[index-1] uz je rozhodnute.
Postupne vygenerujeme vsetky moznosti
pre lup[index],...,lup[N-1].
Kazdy lup porovname s doposial najlepsim
a v pripade potreby optimum aktualizujeme.
*/
if (index == N) {
// Lup je vygenerovany; zisti, ci ho batoh unesie.
if (spocitajHmotnostLupu(lup) <= nosnost) {
// Ak ano, porovnaj cenu s doposial najlepsim.
int cenaLupu = spocitajCenuLupu(lup);
if (cenaLupu > cenaNajlepsiehoLupu) {
// Ak je najdeny lup drahsi, uloz ho
cenaNajlepsiehoLupu = cenaLupu;
for (int i = 0; i < N; i++) {
najlepsiLup[i] = lup[i];
}
}
}
} else {
// Lup este nie je vygenerovany,
// skus obe moznosti pre lup[index].
lup[index] = false;
generujLupy(lup, index+1);
lup[index] = true;
generujLupy(lup, index+1);
}
}
int main() {
cout << "Zadaj pocet predmetov v obchode: ";
cin >> N;
for (int i = 0; i < N; i++) {
cout << "Zadaj hmotnost a cenu predmetu "
<< (i+1) << ": ";
cin >> a[i].hmotnost >> a[i].cena;
}
cout << "Zadaj nosnost batoha: ";
cin >> nosnost;
bool lup[maxN];
generujLupy(lup, 0);
vypisLup(najlepsiLup);
cout << "Celkova hodnota lupu: "
<< cenaNajlepsiehoLupu << endl;
}
Cvičenie: Čo bude program robiť, keď každý predmet má hmotnosť väčšiu ako nosnosť batoha?
Optimalizácia č. 1: ukončenie prehľadávania vždy, keď je prekročená nosnosť
Keď je už po vygenerovaní nejakej podmnožiny (čiže prvých niekoľko hodnôt poľa lup) jasné, že hmotnosť lupu bude presahovať nosnosť batoha, možno túto vetvu prehľadávania ukončiť.
Okrem samotnej funkcie generujLupy je potrebné prispôsobiť aj funkciu spocitajHmotnostLupu tak, aby ju bolo možné aplikovať aj na neúplne vygenerované podmnožiny.
/* Potrebujeme vediet spocitat hmotnost len pre cast predmetov: */
int spocitajHmotnostLupu(bool lup[], int pokial) {
int hmotnost = 0;
for (int i = 0; i <= pokial; i++) {
if (lup[i]) {
hmotnost += a[i].hmotnost;
}
}
return hmotnost;
}
void generujLupy(bool lup[], int index) {
if (spocitajHmotnostLupu(lup, index-1) > nosnost) {
// Ak dosial vygenerovana cast lupu presahuje nosnost batoha,
// mozno prehladavanie ukoncit
return;
}
if (index == N) {
int cenaLupu = spocitajCenuLupu(lup);
if (cenaLupu > cenaNajlepsiehoLupu) {
cenaNajlepsiehoLupu = cenaLupu;
for (int i = 0; i < N; i++) {
najlepsiLup[i] = lup[i];
}
}
} else {
lup[index] = false;
generujLupy(lup, index+1);
lup[index] = true;
generujLupy(lup, index+1);
}
}
Cvičenie: Čo bude program robiť, keď každý predmet má hmotnosť väčšiu ako nosnosť batoha?
Optimalizácia č. 2: hmotnosť a cenu lupu netreba zakaždým počítať odznova
Predchádzajúci program vždy znovu a znovu prepočítava hmotnosť a cenu lupu, aj keď sa zoznam vybraných predmetov zmení iba trochu. Namiesto toho môžeme cenu a hmotnosť doposiaľ vygenerovanej časti lupu predávať funkcii generuj ako parameter.
#include <iostream>
using namespace std;
const int maxN = 100;
struct predmet {
int hmotnost;
int cena;
};
int N;
predmet a[maxN];
int nosnost;
bool najlepsiLup[maxN];
int cenaNajlepsiehoLupu = -1;
void vypisLup(bool lup[]) {
cout << "Zober nasledujuce predmety:";
for (int i = 0; i < N; i++) {
if (lup[i]) {
cout << " " << i + 1;
}
}
cout << endl;
}
void generujLupy(bool lup[], int index, int hmotnostLupu, int cenaLupu) {
if (hmotnostLupu > nosnost) {
return;
}
if (index == N) {
if (cenaLupu > cenaNajlepsiehoLupu) {
cenaNajlepsiehoLupu = cenaLupu;
for (int i = 0; i < N; i++) {
najlepsiLup[i] = lup[i];
}
}
} else {
lup[index] = false;
generujLupy(lup, index+1, hmotnostLupu, cenaLupu);
lup[index] = true;
generujLupy(lup, index+1,
hmotnostLupu + a[index].hmotnost,
cenaLupu + a[index].cena);
}
}
int main() {
cout << "Zadaj pocet predmetov v obchode: ";
cin >> N;
for (int i = 0; i < N; i++) {
cout << "Zadaj hmotnost a cenu predmetu "
<< (i+1) << ": ";
cin >> a[i].hmotnost >> a[i].cena;
}
cout << "Zadaj nosnost batoha: ";
cin >> nosnost;
bool lup[maxN];
// Doposial nie je nic vygenerovane;
// hmotnost aj cena lupu su zatial nulove
generujLupy(lup, 0, 0, 0);
cout << endl;
vypisLup(najlepsiLup);
cout << "Celkova hodnota lupu: "
<< cenaNajlepsiehoLupu << endl;
}
Prednáška 12
Ukazovateľ, smerník, pointer
- Pamäť v počítači je rozdelená na dieliky, do ktorých sa zapisujú hodnoty premenných
- Väčšinou k týmto dielikom pristupujeme pomocou mien premenných
- Každý dielik má adresu (niečo ako poradové číslo)
- Ukazovateľ (resp. smerník alebo pointer) je premenná, ktorej hodnota je adresa iného dieliku pamäte
- Na obrázku je na adrese [adresa 2] uložená premenná typu int, ktorej hodnota je 12345.
- Na adrese [adresa 1] je uložený smerník, ktorého hodnota je [adresa 2].
- Hovoríme, že smerník ukazuje na pamäťovú adresu [adresa 2], budeme to kresliť ako šípku.

Definovanie smerníka
Smerník ukazujúci na premennú typu T sa definuje ako T *p, napríklad:
int *p1; // smerník p1 na int
char *p2; // smerník p2 na char
double *p3; // smerník p3 na double
// atď
Smerníky ukazujúce na premenné rôznych typov sú takisto rôznych typov. Bez pretypovania sa nedá medzi nimi priraďovať.
int *p1;
int *p2;
double *p3;
p1 = p2; // korektné priradenie
p3 = p1; // chyba
Operátor & (adresa)
- Adresu premennej vieme zistiť operátorom &
- Tú potom môžeme priradiť do premennej typu smerník
int n = 12345;
int *p;
p = &n;
Premenná p teraz ukazuje na miesto, kde je uložená celočíselná premenná n.

- Operátor & možno aplikovať aj na prvky poľa
- Operátor & nemožno aplikovať na konštanty ani na výrazy
int n = 0;
int a[5] = {1, 2, 3, 4, 5};
int *p;
p = &n; // korektné priradenie
p = &a[2]; // korektné priradenie
p = &(n+1); // chyba (výraz nemá adresu)
p = &42; // chyba (konštanta 42 nemá adresu)
Operátor * (dereferencia, dáta na adrese)
- Ak p je smerník, pomocou *p môžeme pristúpiť k údajom na adrese reprezentovanej smerníkom p.
- Tieto údaje potom možno aj meniť
int n = 12345;
int *p;
p = &n; // smerník p ukazuje na adresu premennej n
cout << *p << endl; // vypíše hodnotu z adresy p, t.j. 12345
*p = 9; // hodnota na adrese p sa zmení na 9
cout << n << endl; // vypíše hodnotu premennej n, t.j. 9
(*p)++; // hodnota na adrese p sa zmení na 10
cout << n << endl; // vypíše hodnotu premennej n, t.j. 10
n = 42;
cout << *p << endl; // vypíše hodnotu na adrese p, t.j. 42
Smerník NULL
Dôležitým špeciálnym prípadom smerníka je konštanta NULL reprezentujúca smerník, ktorý nikam neukazuje.
- Je definovaná vo viacerých štandardných knižniciach, ako napríklad cstdlib alebo iostream.
- Možno ju priradiť do smerníka ľubovoľného typu.
Pozor, ak do premennej typu smerník nič nepriradíme, má nedefinovanú hodnotu, ukazuje na náhodné miesto v pamäti, alebo niekde mimo.
Smerník ako parameter funkcie
Namiesto odovzdávania parametrov referenciou ich môžeme odovzdať pomocou smerníka. Tu je napríklad smerníková verzia funkcie swap, ktorá vymieňa hodnoty dvoch premenných.
#include <iostream>
using namespace std;
void swap(int *px, int *py) { // parametre sú smerníky
// hodnotu z adresy px uložíme do tmp:
int tmp = *px;
// na adresu px uložíme hodnotu z adresy py:
*px = *py;
// na adresu py uložíme tmp:
*py = tmp;
}
int main() {
int x, y;
cout << "Zadaj x,y: ";
cin >> x >> y;
// ako parametre pošleme adresy premenných x,y
swap(&x, &y);
cout << "x = " << x
<< ", y = " << y << endl;
}
Knižničné funkcie v C často používajú predávanie parametrov referenciou.
Smerníky a polia
Smerníky a polia v jazyku C spolu veľmi úzko súvisia.
- Pole je vlastne smerník na nultý prvok.
- Môžeme ho nakopírovať do premennej typu T *.
- Na premenné typu T * môžeme použiť operátor [].
int a[4] = {10, 20, 30, 40};
int *p;
p = a; // p ukazuje na nulty prvok pola a
cout << a[1]; // vypise 20
cout << p[1]; // vypise 20
- Polia v C pozostávajú z políčok rovnakej veľkosti uložených v pamäti jedno za druhým, veľkosť políčka je daná typom prvku
- Výraz p[i] zoberie adresu uloženú v p, zvýši ju o veľkosť_políčka * i a pozrie sa na príslušnú adresu
- p[0] je teda to isté ako *p
- Pozor, C umožní p[i] použiť aj keď p neukazuje na pole, vtedy pristupuje do pamäte s neznámym obsahom, program môže skončiť s chybou alebo sa správať "záhadne"
int x = 10;
int *p;
p = &x;
cout << p[1]; // ??? pristupuje do pamäte za premennou x
// môže to mať nepríjemné dôsledky
Pozor, polia sú konštantné smerníky, nemožno ich zmeniť
int a[4] = {10, 20, 30, 40};
int b[3] = {1, 2, 3};
int *p = b; // ok
a = b; // nedá sa
a = p; // nedá sa
Vo funkciách pracujúcich s poliami môžeme namiesto parametra int a[] aj int *a a kód ani použitie funkcie sa nemení.
#include <iostream>
using namespace std;
void vypisPole(int a[], int n) {
for (int i = 0; i < n; i++) {
cout << a[i] << " ";
}
cout << endl;
}
void vypisPole2(int *a, int n) {
for (int i = 0; i < n; i++) {
cout << a[i] << " ";
}
cout << endl;
}
int main() {
const int N = 4;
int a[N] = {10, 20, 30, 40};
int *b = a;
//styrikrat vypiseme to iste
vypisPole(a, N);
vypisPole(b, N);
vypisPole2(a, N);
vypisPole2(b, N);
}
Dynamická alokácia a dealokácia pamäte
Doteraz sme videli:
- Globálne premenné, ktoré majú vopred známu veľkosť a vyhradenú pamäť.
- Lokálne premenné, ktoré majú vopred známu veľkosť, ale pamäť sa im prideľuje až pri volaní funkcie na zásobníku volaní funkcií (call stack).
Program si ale počas behu môže podľa potreby vyhradiť aj ďalšiu pamäť:
- Používa sa na to operátor new.
- Pamäť sa vyhradí v oblasti zvanej halda (heap).
- Keď už pamäť nepotrebujeme, uvoľníme ju príkazom delete.
- Uvoľnená pamäť môže byť znovu použitá pri ďalších volaniach new.
Alokácia pamäte na jednu premennú
int *p;
// new vyhradí úsek pamäte pre jednu hodnotu typu int
// adresa tohto úseku sa uloží do smerníka p
p = new int;
// do alokovanej pamäte sa uloží hodnota 50
*p = 50;
cout << *p << endl; // výpis 50
delete p; // uvoľnenie alokovanej pamäte
Alokácia pamäte pre pole
int *p;
// new vyhradí úsek pamäte pre poli 5 hodnôt typu int
p = new int[5];
// premenná p sa dá použiť ako pole dĺžky 5
for(int i=0; i<5; i++) {
p[i] = i;
}
delete[] p; // uvoľnenie alokovanej pamäte
- Pozor, ak alokujeme pole, pamäť uvoľnujeme cez delete[], nie delete
- Ak zamieňate delete[] a delete, správanie programu môže byť nedefinované
int *p; p = new int; // ... delete p; p = new int[5]; // ... delete[] p;
Dynamickú alokáciu polí možno využiť napríklad na vytvorenie poľa, ktorého veľkosť zadá používateľ.
#include <iostream>
using namespace std;
int main(void) {
cout << "Zadaj pocet cisel: ";
int N;
cin >> N;
int *a = new int[N];
cout << "Zadavaj " << N << " cisel:" << end;
for (int i = 0; i <= N-1; i++) {
cin >> a[i];
}
cout << "Tu su cisla odzadu:" << endl;
for (int i = N-1; i >= 0; i--) {
cout << a[i] << " ";
}
cout << endl;
delete[] a;
}
Poznámka:
- V našich programoch sme vytvárali polia, ktorých veľkosť bola konštanta const int maxN = 100; int a[maxN];
- Niektoré kompilátory dovolia vytvoriť aj pole, ktorého veľkosť sa zistí počas behu programu int N; cin >> N; int a[N];
- Nefunguje to však vždy, navyše môže byť problém s veľkými poliami, lebo veľkosť zásobníka volaní môže byť obmedzená
- Pri alokovaní poľa pomocou new vždy môžeme použiť veľkosť, ktorá sa zistila až počas behu int N; cin >> N; int *a = new int[N];
- Alokovanie má aj ďalšie výhody, takto vytvorené pole sa napríklad dá vrátiť ako výsledok funkcie
Aplikácia smerníkov: dynamické polia
V praxi často narazíme na nasledujúci problém: chceme zo vstupu načítať do poľa nejaké údaje, ale vopred nevieme, koľko ich bude a teda aké veľké pole potrebujeme vytvoriť.
- Doteraz sme to riešili konštantou MaxN ohraničujúcou maximálnu povolenú veľkosť vstupu, ale to má problémy:
- Ak je vstup väčší ako MaxN, nevieme ho spracovať, aj ak by inak kapacity počítača postačovali
- Ak je vstup oveľa menší ako MaxN, zbytočne zaberáme pamäť veľkým poľom, ktorého veľká časť je nevyužitá
- Pre jednoduchosť budeme uvažovať na vstupe postupnosť nezáporných čísel ukončenú -1, napr. 7 3 0 4 3 -1
- Do poľa chceme uložiť všetko okrem poslednej -1
- Používateľ nám vopred nezadá počet prvkov
Riešením je postupne alokovať väčšie a väčšie polia podľa potreby
- Začneme s malým poľom (napr. veľkosti 2)
- Vždy keď sa pole zaplní, alokujeme nové pole dvojnásobnej veľkosti, prvky do neho skopírujeme a staré pole odalokujeme
- Presúvanie prvkov dlho trvá, preto pole vždy zdvojnásobíme, aby sme nemuseli presúvať často
- Spolu pri načítaní n prvkov robíme najviac 2n presunov jednotlivých prvkov
Takáto verzia poľa, ktorá rastie podľa potreby, sa nazýva dynamické pole
- V štandardných C++ knižniciach je definovaná dátová štruktúra vector, ktorá sa správa podobne.
- My teraz implementujeme zjednodušenú verziu tejto štruktúry.
- Pre jednoduchosť napíšeme iba verziu dynamického poľa pre typ int. Analogicky by sme postupovali pre iné typy.
Dynamické pole celých čísel budeme reprezentovať ako štruktúru typu dynArray, ktorá bude pozostávať z nasledujúcich troch zložiek:
- Zo smerníku p ukazujúceho na prvý prvok poľa (čiže vlastne pole samotné).
- Z celočíselnej premennej size, v ktorej bude uchovávaná veľkosť alokovanej pamäte pre pole p.
- Z celočíselnej premennej length, v ktorej bude uchovávaný počet prvkov doposiaľ pridaných do poľa.
Štruktúra dynArray teda v sebe združuje pole aj jeho dĺžku, stačí posielať jeden parameter
Napíšeme niekoľko funkcií, pomocou ktorých budeme s dynamickými poľami manipulovať.
- Funkcia void init(dynArray &a) inicializuje dynamické pole a, pričom mu alokuje nejaký malý objem pamäte (u nás dva prvky).
- Funkcia void add(dynArray &a, int x) pridá na koniec dynamického poľa a prvok s hodnotou x. V prípade potreby ešte predtým realokuje pamäť.
- Funkcia int get(dynArray a, int index) vráti prvok dynamického poľa a na pozícii index. V prípade, že index nereprezentuje korektnú pozíciu prvku poľa (teda je menší ako 0 alebo väčší, než a.length - 1), ukončí vykonávanie programu pomocou assert.
- Funkcia void set(dynArray &a, int index, int x) nastaví prvok dynamického poľa na pozícii index na hodnotou x. Ak index nereprezentuje korektnú pozíciu prvku poľa, ukončí vykonávanie programu pomocou assert.
- Funkcia int length(dynArray a) vráti počet prvkov doposiaľ uložených do dynamického poľa a.
- Funkcia void destroy(dynArray &a) zlikviduje dynamické pole a (uvoľní pamäť).
Bez ohľadu na implementáciu samotného dynamického poľa už teda vieme napísať kostru programu, ktorý ho využíva, napríklad na výpis vstupu odzadu.
#include <iostream>
#include <cassert>
using namespace std;
struct dynArray {
// ...
};
// definície funkcií init, add, get, set, length, destroy
int main() {
dynArray a;
init(a); // inicializuje a
int k;
cin >> k;
// pridavame prvky, kym su nezaporne
while (k >= 0) {
add(a,k);
cin >> k;
}
// vypise prvky pola od konca
for (int i = length(a) - 1; i >= 0; i--) {
cout << get(a, i) << " ";
}
cout << endl;
// ukazka pouzitia get a set
set(a, 0, 42);
cout << get(a, 0) << endl;
destroy(a); // uvolni pamat
}
Implementácia dynamického poľa
#include <iostream>
#include <cassert>
using namespace std;
/* Dynamicke pole celych cisel */
struct dynArray {
int *p; // smernik na prvy prvok pola
int size; // velkost alokovaneho pola
int length; // pocet prvkov pridanych do pola
};
void init(dynArray &a) {
/* Inicializuje dynamicke pole velkosti 2 */
a.size = 2;
a.length = 0;
a.p = new int[a.size];
}
void add(dynArray &a, int x) {
/* Prida na koniec dynamickeho pola prvok x
* a v pripade potreby realokuje pole */
// ak uz sa x do pola nevojde
if (a.length == a.size) {
// zdvojnasobime velkost
a.size *= 2;
// alokujeme vacsie pole
int *newp = new int[a.size];
// prekopirujeme stare pole do noveho
for (int i = 0; i <= a.length - 1; i++) {
newp[i] = a.p[i];
}
// uvolnime stare pole
delete[] a.p;
a.p = newp; // a.p teraz ukazuje na nove pole
}
// teraz je pole urcite dost velke
// pridame x a zvysime pocet prvkov
a.p[a.length] = x;
a.length++;
}
int get(dynArray &a, int index) {
/* Vrati prvok dynamickeho pola a na pozicii index
* (ak ide o korektnu poziciu)*/
assert(index >= 0 && index <= a.length - 1);
return a.p[index];
}
void set(dynArray &a, int index, int x) {
/* Ulozi na poziciu index dynamickeho pola a hodnotu x
* (ak ide o korektnu poziciu)*/
assert(index >= 0 && index <= a.length - 1);
a.p[index] = x;
}
int length(dynArray &a) {
/* Vrati pocet prvkov v dynamickom poli a */
return a.length;
}
void destroy(dynArray &a) {
/* Uvolni alokovanu pamat pre pole a */
delete[] a.p;
}
int main() {
dynArray a;
init(a); // inicializuje a
int k;
cin >> k;
// pridavame prvky, kym su nezaporne
while (k >= 0) {
add(a,k);
cin >> k;
}
// vypise prvky pola od konca
for (int i = length(a) - 1; i >= 0; i--) {
cout << get(a, i) << " ";
}
cout << endl;
// ukazka pouzitia get a set
set(a, 0, 42);
cout << get(a, 0) << endl;
destroy(a); // uvolni pamat
}
Ladenie programov so smerníkmi
- Smerníky (a polia) môžu byť nepríjemným zdrojom chýb, keďže kompilátor nekontroluje, či sú používané správne.
- Napríklad možno čítať aj zapisovať mimo alokovanej pamäte.
- S odchytávaním takýchto chýb môžu pomôcť automatizované nástroje, ako napríklad Valgrind (pre Linux) alebo Dr. Memory (pre Windows aj Linux).
- Návod na prácu s programom valgrind
Zhrnutie
- Smerník, ukazovateľ, pointer je premenná, v ktorej je uložená adresa nejakého pamäťového miesta
- Typ smerníku určuje, na aký typ premennej by mal ukazovať, napr. int *p
- Do smerníku môžeme priradiť NULL, adresu nejakej premennej (&i), novoalokovanú pamäť pomocou new, iný smerník toho istého typu
- Ku políčku, na ktoré ukazuje smerník p, pristupujeme pomocou (*p)
- Pole je vlastne smerník na svoj prvý (nultý) prvok
- Pole určitej dĺžky (ktorá je známa až počas behu) alokujeme pomocou new typ[pocet]
- Pamäť alokovanú cez new by sme mali odalokovať pomocou delete alebo delete[] (podľa toho, či to bolo pole)
- Pri práci so smerníkmi ľahko spravíme chybu, pomôcť nám môže napríklad valgrind
Prednáška 13
Oznamy
- Od dnes prechádzame na hybridnú výučbu, viac informácií na stránke o #MS Teams.
- V piatok bude na cvičeniach bonusová rozcvička za jeden bod.
- V prípade riadnej aj bonusovej rozcvičky je potrebné byť na cvičeniach osobne alebo online.
- Domácu úlohu 2 odovzdávajte do 15.11. 22:00.
- Na domácich úlohách neodpisujte!
Opakovanie smerníkov
Smerníky na jednoduché premenné:
int n = 7; // premenná typu int int *p = NULL; // smerník na premennú typu int p = &n; // p ukazuje na n *p = 8; // v premennej n je teraz 8 n = (*p)+1; // v premennej n je teraz 9
Smerníky a polia, alokovanie poľa:
int a[3]; int *b = a; // a,b sú teraz takmer rovnocenné premenné *b = 3; b[1] = 4; a[2] = 5; // v poli sú teraz čísla 3,4,5 b = new int[a[1]]; // b teraz ukazuje na nové pole dĺžky 4 delete[] b; // uvoľníme pamäť alokovanú pre nové pole
Dvojrozmerné polia
- Doteraz sme stále pracovali s jednorozmerným poľom, čo však ak potrebujeme dvojrozmerné pole, maticu?
- Napríklad na matice z algebry, alebo na dvojrozmerné tabuľky napr. body študentov z domácich úloh
- Podobne môžeme potrebovať aj polia väčších rozmerov, pracuje sa s nimi analogicky ako s dvojrozmenrnými
Dvojrozmerné polia s konštantnou veľkosťou
- Ak je veľkosť dvojrozmerného poľa vopred známa konštanta, môžeme ho vytvoriť veľmi jednoducho
- napr. int a[2][5] vytvorí tabuľku s dvomi riadkami a piatimi stĺpcami
- a[i][j] je potom prvok na riadku i a stĺpci j
- Rozmery poľa musíme uviesť aj ak pole posielame do funkcie, napr. void vypis(int a[2][5])
- Tento spôsob však nebudeme ďalej používať, lebo väčšinou chceme rozmery prispôsobiť potrebám daného vstupu
#include <iostream>
using namespace std;
int main() {
/* Vytvorime pole s dvoma riadkami a piatimi stlpcami
* a rovno ho aj inicializujeme: */
int a[2][5] = {{1,2,3,4,5},{6,7,8,9,10}};
/* Vypiseme pole ako tabulku: */
for (int i = 0; i < 2; i++) {
for (int j = 0; j < 5; j++) {
cout << a[i][j] << " ";
}
cout << endl;
}
}
Dvojrozmerné pole pomocou poľa smerníkov
- Omnoho flexibilnejšou alternatívou sú polia smerníkov.
- Každý riadok tabuľky bude jedno dynamicky alokované pole a smerník na jeho začiatok si uložíme do poľa smerníkov
- Tabuľka s m riadkami a n sĺpcami bude v pamäti uložená nejako takto:

Nasledujúci program načíta rozmery dvojrozmernej tabuľky, potom jej prvky a spočíta priemer čísel v každom stĺpci.
#include <iostream>
using namespace std;
int main() {
int m, n;
cout << "Zadaj pocet riadkov: ";
cin >> m;
cout << "Zadaj pocet stlpcov: ";
cin >> n;
/* Alokuj pole smernikov na riadky: */
int **a;
a = new int *[m];
/* Alokuj jednotlive riadky: */
for (int i = 0; i < m; i++) {
// a[i] je smernik na i-ty riadok
a[i] = new int[n];
}
/* Nacitanie prvkov tabulky: */
cout << "Zadaj cisla tabulky:" << endl;
for (int i = 0; i < m; i++) {
for (int j = 0; j < n; j++) {
// nacitaj j-ty prvok i-teho riadku
cin >> a[i][j];
}
}
/* Spocitaj a vypis priemery jednotlivych stlpcov: */
for (int j = 0; j < n; j++) {
int sum = 0;
for (int i = 0; i < m; i++) {
sum += a[i][j];
}
cout << "Priemer hodnot v stlpci " << j
<< " je " << ((double)sum) / m << endl;
}
/* Uvolnenie pamate: */
for (int i = 0; i < m; i++) {
delete[] a[i];
}
delete[] a;
}
Cvičenie:
- Ako by ste spočítali priemery stĺpcov vstupnej tabuľky s využitím iba jednorozmerného poľa? (Celú tabuľku teda nechceme ukladať.)
- Ako by vyzeralo vytvorenie a použitie trojrozmernej tabuľky?
- Ako by sme navzájom vymenili prvý a druhý riadok tabuľky? Ako prvý a druhý stĺpec?
Príklad: výšková mapa
Pokračujme ukážkou o niečo väčšieho programu využívajúceho dvojrozmerné tabuľky (matice)
- Maticu uložíme ako dynamicky alokované pole smerníkov
- V programe je niekoľko funkcií, ktoré sa môžu zísť aj v iných programoch na prácu s maticami
- int ** vytvorMaticu(int m, int n) alokuje pamäť pre maticu s m riadkami a n stĺpcami a vráti smerník na pole smerníkov
- void zmazMaticu(int **a, int m) uvolní pamäť alokovanú pre maticu a s m riadkami (počet stĺpcov nepotrebujeme)
- void nacitajMaticu(int **a, int m, int n) dostane už alokovanú maticu s m riadkami a n stĺpcami a vyplní ju číslami načítanými zo vstupu
Všimnite si, že funkciám potrebujeme dávať aj rozmery matice. Namiesto toho by sme si mohli spraviť štruktúru podobne ako pri dynamickom poli:
struct matica {
int m, n;
int **a;
}
Cieľ programu
Náš program bude v obdĺžnikovej tabuľke celých čísel uchovávať výškovú mapu
- Bude to obdĺžniková tabuľka s m riadkami a n stĺpcami
- Každé políčko obsahovať nadmorskú výšku od 0 po 2000 metrov nad morom (nadmorská výška 0 znamená more a kladná nadmorská výška znamená pevninu)
- Program na vstupe najprv dostane rozmery tabuľky m a n a následne nadmorské výšky všetkých štvorčekov.
- Takto zadanú mapu program vykreslí pomocou knižnice SVGdraw, pričom každý štvorček dostane určitú farbu podľa svojej nadmorskej výšky.
- Následne zavolá funkciu najvyssiVrch, ktorá nájde najvyšší bod (resp. jeden z najvyšších bodov) vykresľovaného územia a v mape ho zvýrazní rámikom.
Príklad vstupu a výstupu:

22 11 0 0 0 0 0 0 0 0 0 0 0 0 20 40 60 80 100 120 140 120 0 0 0 40 80 120 160 200 240 280 190 100 0 0 60 120 180 240 300 360 420 260 100 0 0 80 160 240 320 400 480 560 260 100 0 0 100 200 300 400 500 600 700 330 100 0 0 120 240 360 480 600 720 840 400 100 0 0 140 280 420 560 700 840 980 470 100 0 0 160 320 480 640 800 960 700 200 0 0 0 180 360 540 720 900 700 500 0 0 0 0 200 400 600 800 1000 1200 1400 680 100 0 0 220 440 660 880 1100 1320 1540 750 100 0 0 240 480 720 960 1200 1440 1680 820 100 0 0 260 520 780 1040 1300 1560 1820 1200 400 0 0 280 560 840 1120 1400 1680 1960 1500 600 0 0 240 480 720 960 1200 1440 1680 1000 400 0 0 200 400 600 800 1000 1200 1400 680 100 0 0 160 320 480 640 800 960 1120 540 100 0 0 120 240 360 480 600 720 840 400 100 0 0 80 160 240 320 400 480 560 260 100 0 0 40 80 120 160 200 240 280 120 0 0 0 0 0 0 0 0 0 0 0 0 0
Program výšková mapa
#include <iostream>
#include "SVGdraw.h"
using namespace std;
/* velkost stvorceka mapy v pixeloch */
const int stvorcek = 15;
int ** vytvorMaticu(int m, int n) {
/* Vytvori a vrati maticu (obdlznikovu tabulku)
* s m riadkami a n stlpcami. */
int **a;
a = new int *[m];
for (int i = 0; i < m; i++) {
a[i] = new int[n];
}
return a;
}
void zmazMaticu(int **a, int m) {
/* Uvolni z pamate maticu
* s m riadkami a n stlpcami. */
for (int i = 0; i < m; i++) {
delete[] a[i];
}
delete[] a;
}
void nacitajMaticu(int **a, int m, int n) {
/* Nacita hodnoty do uz vytvorenej matice
* velkosti m krat n. */
for (int i = 0; i < m; i++) {
for (int j = 0; j < n; j++) {
cin >> a[i][j];
}
}
}
void nastavFarbu(int vyska, SVGdraw &drawing) {
/* podla nadmorskej vysky nastavi farbu ciary
* aj vyplne
* modra -- more (nadmorska vyska 0)
* zelena -- niziny (nadmorska vyska 1,...,200)
* hneda -- "pohoria" (nadmorska vyska 200,...,2000) */
// premenne pre cervenu, zelenu a modru zlozku farby
int r, g, b;
// nastavenie farby podla hodnoty
if (vyska == 0) { // modre more
r = 0;
g = 0;
b = 255;
} else if (vyska <= 200) { // zelena nizina
double x = vyska / 200.0;
r = x * 255;
g = 127 + x * 127;
b = 0;
} else { // zlto-hnede hory
double x = (vyska - 200) / 1800.0;
r = 255 - x * 150;
g = 255 - x * 200;
b = 0;
}
/* Nastavi farbu ciary aj vyplne na dane hodnoty. */
drawing.setLineColor(r, g, b);
drawing.setFillColor(r, g, b);
}
void vykresliStvorcek(int riadok, int stlpec, SVGdraw &drawing) {
/* Vykresli stvorcek pre dany riadok a stlpec mapy.
* Pouzije pri tom aktualne nastavene farby.
* Pozor, pri vykreslovani
* uvadzame najskor x (stlpec), potom y (riadok) */
drawing.drawRectangle(stlpec * stvorcek,
riadok * stvorcek,
stvorcek, stvorcek);
}
void vykresliMapu(int **a, int m, int n, SVGdraw &drawing) {
/* Vykresli mapu rozmerov m krat n do obrazku.
* Jednotlive stvorceky mapy ofarbi podla ich nadmorskej vysky */
for (int i = 0; i < m; i++) {
for (int j = 0; j < n; j++) {
nastavFarbu(a[i][j], drawing);
vykresliStvorcek(i, j, drawing);
}
}
}
void maximumMatice(int **a, int m, int n, int &riadok, int &stlpec) {
/* Najde v matici a o rozmeroch m krat n
* policko s maximalnou hodnotou
a jeho suradnice ulozi do premennych riadok, stlpec. */
riadok = 0;
stlpec = 0;
for (int i = 0; i < m; i++) {
for (int j = 0; j < n; j++) {
if (a[i][j] > a[riadok][stlpec]) {
riadok = i;
stlpec = j;
}
}
}
}
int main(void) {
/* nacitaj rozmery matice */
int m, n;
cin >> m >> n;
/* vytvor a nacitaj maticu */
int **a = vytvorMaticu(m, n);
nacitajMaticu(a, m, n);
/* zobraz maticu, pozor vymena suradnice */
SVGdraw drawing(n * stvorcek, m * stvorcek,
"mapa.svg");
vykresliMapu(a, m, n, drawing);
/* najdi najvyssi vrch a zvyrazni ho stvorcekom */
int riadok, stlpec;
maximumMatice(a, m, n, riadok, stlpec);
drawing.setLineColor("black");
drawing.setLineWidth(3);
drawing.setNoFill();
vykresliStvorcek(riadok, stlpec, drawing);
/* ukonci vykreslovanie */
drawing.finish();
/* uvolni pamat matice */
zmazMaticu(a, m);
}
Polia reťazcov
- Dvojrozmerné polia v C/C++ nemusia mať všetky riadky rovnako dlhé. To sa hodí napríklad na ukladanie viacerých reťazcov.
- Spomeňte si, že v C je reťazec jednoducho pole char-ov, kde za posledným znakom ide špeciálny znak 0
- Pole reťazcov bude teda dvojrozmerné pole char-ov
- Môžeme načítavať napr. vstup po riadkoch, pričom každý riadok načítame do dlhého poľa, ktoré by malo stačiť a potom do prekopírujeme do akurát veľkého riadku v poli
- Vstup je ukončený prázdnym riadkom
- Nakoniec program riadky vypíše odzadu
- Ak by sme vopred alokovali maxN riadkov, každý veľkosti maxRiadok, vyšlo by potenciálne na zmar oveľa viac pamäte.
#include <iostream>
#include <cstring>
using namespace std;
const int maxN = 1000;
const int maxRiadok = 1000;
int main() {
char *a[maxN]; // pole maxN smernikov na char
char riadok[maxRiadok];
int n = 0;
while (true) {
// nacitame jeden riadok
cin.getline(riadok, maxRiadok);
// ak je prazdny alebo sa minuli polozky pola A,
// koncime nacitavanie
if (strcmp(riadok, "") == 0 || n == maxN) {
break;
}
// alokujeme pamat pre n-ty retazec pola a
// pozor, je o jedna dlhsi ako dlzka retazca (kvoli 0 na konci)
a[n] = new char[strlen(riadok)+1];
// prekopirujeme riadok
strcpy(a[n], riadok);
n++;
}
// vypiseme riadky odzadu
for(int i = n-1; i >= 0; i--) {
cout << a[i] << endl;
}
// uvolnime pamat
for (int i = 0; i < n; i++) {
delete[] a[i];
}
}
Cvičenia:
- Prečo nemáme na konci programu delete[] a?
- Čo by sa stalo, ak by sme namiesto a[n] = new char[strlen(riadok)+1]; strcpy(a[n], riadok) dali a[n] = riadok?
- Prerobte program tak, aby namiesto poľa a fixnej veľkosti maxN používal dynamické pole.
- Vedeli by sme dynamické polia nejako použiť aj na načítavanie jednotlivých riadkov?
Vstupy do funkcie main
Často vidíte v programoch funkciu main s nasledujúcou hlavičkou:
int main(int argc, char** argv) {
Vstupné argumenty argc a argv sa používajú pri spúšťaní programu na príkazovom riadku.
- argv je pole C-čkových reťazcov a argc je počet reťazcov v tomto poli
- Prvý reťazec, argv[0], je meno samotného programu a ostatné sú argumenty programu
- Videli sme napríklad spúšťanie kompilátora na príkazovom riadku:
g++ program.cpp
- Tu g++ je meno programu, ktoré je nasledované argumentom program.cpp, ktorý dáva kompilátoru informáciu o tom, ktorý zdrojový súbor má kompilovať.
Nasledujúci jednoduchý program vypíše všetky argumenty, ktoré dostal z príkazového riadku, vrátane mena programu.
#include <iostream>
using namespace std;
int main(int argc, char **argv) {
for (int i = 0; i < argc; i++) {
cout << argv[i] << endl;
}
}
Deklarácie so smerníkmi a poľami
Príklady na prácu s maticami uvedené vyššie môžete modifikovať vo vlastných programoch, ale je dobré trochu lepšie rozumieť logike práce so smerníkmi v C/C++.
- Operátor [ ] je zľava asociatívny, t.j. a[2][3] je to isté ako (a[2])[3]
- Operátor * je sprava asociatívny, t.j. **p je to isté ako *(*p).
- Operátor [ ] má vyššiu prioritu ako *, t.j. *a[10] je to isté ako *(a[10]).
- Ak x je pole smerníkov na int, tak *(x[10]) znamená, že vezmeme pole x, pozrieme sa na jeho desiaty prvok a následne na tento desiaty prvok aplikujeme dereferenciu, čím dostaneme int.
- Ak x je smerník na pole int-ov, (*x)[10] znamená, že vezmeme x, aplikujeme dereferenciu, ktorej výsledkom je pole int-ov a pozrieme sa na desiaty prvok tohto poľa.
Cvičenie:
- Premennú x sme vytvorili príkazom int **x = vytvorMaticu(20,20). S ktorými prvkami tabuľky potom pracujú výrazy *(x[10]) a (*x)[10]?
Komplikácie nastávajú aj pri pochopení typov premenných. Pomôžu nasledujúce rady.
- Deklaráciu premennej int *p môžeme čítať takto: Ak vezmeme smerník p a aplikujeme na neho operátor *, získame hodnotu typu int
- Deklarácia int *a[10] je to isté ako int *(a[10]) znamená: Ak vezmeme a, pozrieme sa na niektorý z desiatich prvkov tohto poľa a nakoniec aplikujeme dereferenciu, dostaneme hodnotu typu int. Vytvorili sme teda desaťprvkové pole smerníkov na int.
- Deklarácia int (*a)[10] znamená: Ak vezmeme a, aplikujeme dereferenciu, dostaneme pole a keď sa pozrieme na niektorý prvok tohto poľa, dostaneme int. Riadok teda vytvorí smerník na pole desiatich celých čísel. Tento smerník však zatiaľ ukazuje na náhodné miesto pamäte, žiadne nové pole nevzniklo. To sa nám málokedy zíde, premennú a môžeme zadefinovať radšej ako int **a.
- Deklarácia int *(*(a[10])) vytvorí desaťprvkové pole smerníkov na smerníky na int. Dá sa zapísať aj bez zátvoriek int **a[10]
Zhrnutie
- Hlavnou náplňou dnešnej prednášky bolo vytvorenie a používanie dvojrozmerných polí pomocou poľa smerníkov na riadky
- Môžete používať a podľa potreby upravovať funkcie int ** vytvorMaticu(int m, int n), void zmazMaticu(int **a, int m) a void nacitajMaticu(int **a, int m, int n) z programu s výškovou mapou
- Pole reťazcov je vlastne dvojrozmerná tabuľka znakov, ktorej riadky môžu mať rôznu dĺžku (a každý je správne ukončený nulou)
- Pozor na správnu alokáciu a dealokáciu. Pri práci so smerníkmi sa oplatí nakresliť si obrázok, čo kam ukazuje.
Prednáška 14
Oznamy
- V piatok na cvičeniach aj bonusová rozcvička za 1 bonusový bod.
- Ak chcete prísť osobne, vyplňte svoje meno do tabuľky.
- Môžete sa pýtať aj otázky ohľadom domácej úlohy.
- Druhú domácu úlohu treba odovzdať do pondelka 15.11. 22:00.
- Budúci týždeň 16.11. je v utorok od 12:00 rektorské voľno kvôli protestu.
- Nebude teda rozcvička, zverejníme ale nejaké úlohy. Poskytneme online konzultácie počas bežného času cvičení a tiež budú cvičenia v piatok
Dynamická množina
Motivačný príklad
- Na fakulte sa dvere do niektorých miestností otvárajú priložením čipovej karty k čítačke
- Každá karta má v sebe uložené identifikačné číslo
- Čítačka má v pamäti zoznam identifikačných čísel oprávnených osôb (študenti, vyučujúci a pod.)
- Po priložení karty z nej prečíta číslo a zisťuje, či ho má vo svojom zozname
- Administrátor tiež potrebuje vedieť pridávať a uberať oprávnené osoby
- Ako asi môže byť systém pracujúci so zoznamom identifikačných čísel naprogramovaný?
Dynamická množina
Chceli by sme vytvoriť dátovú štruktúru s nasledujúcou špecifikáciou
- Máme množinu A, ktorá sa bude postupne meniť, preto ju nazývame dynamická množina.
- Funkcia contains dostane množinu A a hodnotu x a zistí, či x patrí do A.
- Funkcia add dostane množinu A a hodnotu x a pridá x do A.
- Funkcia remove dostane množinu A a prvok x a odoberie x z A.
- Pre jednoduchosť funkciu remove nebudeme dnes uvažovať.
- Niekedy sa môžu zísť aj iné operácie.
Problém príslušnosti k množine sa vyskytuje aj v mnohých iných situáciách.
- Ako dnes uvidíme, dynamickú množinu môžeme implementovať rôznymi spôsobmi.
- Hovoríme, že dynamická množina je abstraktný dátový typ, špecifikuje totiž iba rozhranie, ktoré má dátová štruktúra poskytovať používateľovi, nie jeho implementáciu.
- Ak by sme zmenili implementáciu z jednej na inú, nemusíme nutne meniť programy, ktoré dynamickú množinu využívajú, pokiaľ k nej pristupujú iba pomocou uvedených funkcií.
Implementácie dynamických množín
- Pre jednoduchosť budeme uvažovať iba dynamickú množinu celých čísel.
- Dynamickú množinu budeme uchovávať v štruktúre set.
- Navyše budeme mať implementovaných niekoľko funkcií, ktoré s dynamickými množinami pracujú.
- Kostra programu teda bude vyzerať pre ľubovoľnú implementáciu dynamickej množiny takto:
/* Struktura reprezentujuca dynamicku mnozinu. */
struct set {
// ...
};
/* Funkcia vytvori prazdnu dynamicku mnozinu. */
void init(set &s) {
// ...
}
/* Funkcia zisti, ci prvok x patri do mnoziny s. */
bool contains(set &s, int x) {
// ...
}
/* Funkcia prida prvok x do mnoziny s. */
void add(set &s, int x) {
// ...
}
/* Funkcia uvolni mnozinu s z pamate. */
void destroy(set &s) {
// ...
}
Bez ohľadu na implementáciu štruktúry set a uvedených funkcií už teraz môžeme napísať program, ktorý ich využíva. Z konzoly číta príkazy a postupne ich vykonáva.
#include <iostream>
#include <cstring>
using namespace std;
// ...
const int maxlength = 100;
int main(void) {
set A;
init(A);
while (true) {
char prikaz[maxlength];
cin.width(maxlength);
cin >> prikaz;
if (strcmp(prikaz, "contains") == 0) {
int x;
cin >> x;
cout << contains(A, x) << endl;
} else if (strcmp(prikaz, "add") == 0) {
int x;
cin >> x;
add(A, x);
} else if (strcmp(prikaz, "end") == 0) {
break;
}
}
destroy(A);
}
Ukážeme si teraz niekoľko rôznych implementácii dynamickej množiny; začneme s dvoma, ktoré sú nám už známe.
Dynamická množina ako pole
Dynamickú množinu môžeme implementovať tak, že jej prvky budeme ukladať do poľa v ľubovoľnom poradí.
- Funkcia contains musí zakaždým prejsť celé pole lineárnym prehľadávaním (nie je teda zrovna rýchla).
- Funkcia add je naopak veľmi rýchla: stačí pridať prvok na koniec poľa.
- Je ale potrebné dávať pozor na prekročenie kapacity poľa (mohli by sme použiť dynamické pole).
#include <cassert>
// ...
const int maxN = 1000;
struct set {
int *p; // Smerník na nultý prvok poľa
int length; // Počet prvkov v poli
};
void init(set &s) {
s.p = new int[maxN];
s.length = 0;
}
bool contains(set &s, int x) {
for (int i = 0; i < s.length; i++) {
if (s.p[i] == x) {
return true;
}
}
return false;
}
void add(set &s, int x) {
assert(s.length < maxN);
s.p[s.length] = x;
s.length++;
}
void destroy(set &s) {
delete[] s.p;
}
Dynamická množina ako utriedené pole
Prvky množiny môžeme v poli uchovávať aj utriedené od najmenšieho po najväčšie.
- Funkcia contains potom môže použiť binárne vyhľadávanie. Je teda rýchlejšia, ako v predchádzajúcom prípade (v poli veľkosti n sa pozrie len na približne log n pozícií; napríklad pre miliónprvkové pole sa pozrieme asi na 20 prvkov poľa).
- Funkcia add ale musí vložiť prvok na správne miesto v utriedenom poli; je teda o dosť pomalšia.
#include <cassert>
// ...
const int maxN = 1000;
struct set {
int *p; // Smernik na nulty prvok pola.
int length; // Momentalna dlzka pola.
};
void init(set &s) {
s.p = new int[maxN];
s.length = 0;
}
bool contains(set &s, int x) {
int left = 0;
int right = s.length - 1;
while (left <= right) {
int index = (left + right) / 2;
if (s.p[index] == x) {
return true;
} else if (s.p[index] > x) {
right = index - 1;
} else {
left = index + 1;
}
}
return false;
}
void add(set &s, int x) {
assert(s.length < maxN);
int kam = s.length;
while (kam > 0 && s.p[kam - 1] > x) {
s.p[kam] = s.p[kam - 1];
kam--;
}
s.p[kam] = x;
s.length++;
}
void destroy(set &s) {
delete[] s.p;
}
Ďalšie možnosti implementácie dynamickej množiny (plán na dnes)
Dnes uvidíme ďalšie dva spôsoby implementácie dynamickej množiny:
- Množina ako spájaný zoznam:
- Ľahko pridáme nové prvky, nepotrebujeme vopred vedieť veľkosť.
- Nedá sa rýchlo binárne vyhľadávať.
- Založené na smerníkoch.
- Množina pomocou hašovania:
- Často veľmi rýchle vyhľadávanie.
- Použijeme polia aj spájané zoznamy.
Odbočka: smerníky a struct
Opakovanie základnej práce so smerníkmi
int n = 7; // premenná typu int
int *p = &n; // smerník na int
// n, *p teraz znamenajú to iste
int *p2 = new int; // p2 ukazuje na alokovanu pamäť pre jeden int
*p2 = 7; // pomocou *p2 pracujem s touto pamäťou
delete p2; // uvoľním pamäť
p2 = p; // tu mením samotný semerník
p = NULL; // NULL "nikam neukazuje"
Smerníky a struct
Smerník môže ukazovať aj na struct. Operátory . (prístup k prvku štruktúry) a [] (prístup k prvku poľa) majú vyššiu prioritu ako operátory * (dereferencia smerníka) a & (adresa). Preto napríklad:
- Zápis *s.cokolvek je to isté ako *(s.cokolvek) a vyjadruje dereferenciu smerníka s.cokolvek.
- Zápis (*p).cokolvek vyjadruje prvok cokolvek štruktúry získanej dereferenciou smerníka p.
- Zvyčajne je potrebnejší zápis (*p).cokolvek; existuje preň preto skratka p->cokolvek.
struct bod {
int x, y;
};
// ...
bod b;
b.x = 0;
b.y = 0;
bod *p = &b; // p ukazuje na bod b
bod *p2 = new bod; // alokovanie nového bodu
(*p2).x = 20; // bod, na ktorý ukazuje p2, bude mať x 20
p2->y = 10; // bod, na ktorý ukazuje p2, bude mať y 10
delete p2; // uvoľnenie pamäte
Spájané zoznamy
Spájaný zoznam (angl. linked list) je postupnosť uzlov rovnakého typu usporiadaných za sebou. Každý uzol pritom pozostáva z dvoch častí:
- Samotné dáta; v našom prípade jedno číslo typu int.
- Smerník next, ktorý ukazuje na nasledujúci prvok zoznamu.
- Tieto smerníky umožňujú pohybovať sa po zozname zľava doprava.
- Posledný uzol zoznamu nemá následníka, smerník next bude mať hodnotu NULL.
Štruktúra spájaného zoznamu je znázornená na nasledujúcom obrázku:

Uzol jednosmerne spájaného zoznamu budeme reprezentovať pomocou struct-u node:
/* Struktura reprezentujuca uzol jednosmerne spajaneho zoznamu: */
struct node {
int data; // Hodnota ulozena v danom uzle
node *next; // Smernik na nasledujuci uzol
};
Vo vnútri definície typu node teda používame smerník na samotný typ node.
Samotná množina reprezentovaná spájaným zoznamom je potom štruktúra set obsahujúca iba smerník na prvý prvok zoznamu. Ak je zoznam prázdny, bude tento smerník NULL.
/* Struktura implementujuca mnozinu ako spajany zoznam: */
struct set {
node *first; // Smernik na prvy uzol zoznamu
};
void init(set &s) {
s.first = NULL;
}
Vkladanie na začiatok zoznamu
Nasledujúca funkcia na začiatok zoznamu vloží nový uzol s dátami x:
void add(set &s, int x) {
node *p = new node; // Vytvoríme nový uzol ...
p->data = x; // ... jeho data nastavíme na x.
p->next = s.first; // ... jeho nasledníkom bude doposiaľ prvý prvok zoznamu
s.first = p; // ... a uzol p bude novým prvým prvkom
}
Vyhľadávanie v zozname
Funkcia vyhľadávajúca číslo x v zozname bude pracovať tak, že postupne prehľadáva zoznam od jeho začiatku, s využitím smerníkov na nasledujúce prvky:
bool contains(set &s, int x) {
node *p = s.first;
while (p != NULL) {
if (p->data == x) {
return true;
}
p = p->next;
}
return false;
}
Uvoľnenie zoznamu
Funkcia realizujúca uvoľnenie zoznamu z pamäti pracuje podobne: prechádza postupne zoznam od začiatku až po jeho koniec a uvoľňuje z pamäte jednotlivé uzly. Treba si tu však dať pozor na to, aby sme smerník na nasledujúci uzol získali ešte predtým, než z pamäti uvoľníme ten predošlý.
void destroy(set &s) {
node *p = s.first;
while (p != NULL) {
node *p2 = p->next;
delete p;
p = p2;
}
}
Výpis zoznamu
Môžeme napísať aj nasledujúcu funkciu, ktorá po zavolaní vypíše obsah celého zoznamu:
void print(set &s) {
node *p = s.first;
while (p != NULL) {
cout << p->data << " ";
p = p->next;
}
cout << endl;
}
Varianty spájaných zoznamov
- V našom zozname si v každom uzle pamätáme iba smerník na následníka, hovoríme o jednosmerne spájanom zozname.
- Často sú užitočné aj obojsmerne spájané zoznamy, kde sa v každom uzle uchováva aj smerník na predchodcu; takéto zoznamy sú ale o niečo náročnejšie na údržbu.
- Používajú sa dokonca aj cyklické zoznamy, kde posledný prvok ukazuje späť na prvý prvok zoznamu
Hašovanie
Implementácia množiny priamym adresovaním
Úplne odlišným spôsobom implementácie dynamickej množiny je tzv. priame adresovanie (angl. direct addressing).
- Množinu všetkých možných hodnôt, ktoré v danej implementácii môžeme chcieť do množiny pridať, nazveme univerzum U
- Predchádzajúce implementácie sa ľahko dali upraviť na rôzne univerzá (celé čísla, desatinné čísla, smerníky na zložitejšie štruktúry, napr. struct, pole, reťazec)
- Na rozdiel od toho sa priame adresovanie dá použiť iba ak univerzum je U = {0,1,...,m-1} pre nejaké rozumne malé prirodzené číslo m
- Podmnožinu A univerza U potom môžeme reprezentovať ako pole booleovských hodnôt dĺžky m, kde i-ty prvok poľa bude true práve vtedy, keď i patrí do A.
- Túto reprezentáciu sme používali napríklad v poli bolo pri prehľadávaní s návratom.
- Funkcie contains aj add sú potom veľmi jednoduché a rýchle.
- Problémom tohto prístupu je ale vysoká pamäťová zložitosť, ak je číslo m veľké.
- Veľmi efektívne pre malé univerzá (napr. cifry 0,...,9, všetky znaky anglickej abecedy, všetky znaky s ASCII hodnotami od 0 po 255, a pod.).
#include <cassert>
const int m = 1000;
/* Struktura implementujuca mnozinu priamym adresovanim: */
struct set {
bool *p;
};
void init(set &s) {
s.p = new bool[m];
for (int i = 0; i < m; i++) {
s.p[i] = false;
}
}
bool contains(set &s, int x) {
assert(x >= 0 && x <= m - 1);
return s.p[x];
}
void add(set &s, int x) {
assert(x >= 0 && x <= m - 1);
s.p[x] = true;
}
void destroy(set &s) {
delete[] s.p;
}
Jednoduché hašovanie
Priame adresovanie sa nehodí pre veľké univerzá, lebo by vyžadovalo veľa pamäte.
Hašovanie (angl. hashing) je jednoduchá finta, ktorá funguje nasledovne:
- Nech U je univerzum všetkých možných prvkov množiny.
- Vytvoríme hašovaciu tabuľku (angl. hash table), čo je pole nejakej rozumnej veľkosti m.
- Naprogramujeme hašovaciu funkciu, ktorá transformuje prvky univerza U na indexy hašovacej tabuľky; pôjde teda o funkciu h: U -> {0, 1, ... , m−1}.
- Najjednoduchšia hašovacia funkcia pre celočíselné prvky je h(x) = |x| mod m.
- |x| spočítame funkciou abs z knižnice cstdlib
- Absolútnu hodnotu používame, lebo napríklad -10 % 3 je -1, čo mimo rozsahu indexov tabuľky
- V praxi sa používajú zložitejšie hašovacie funkcie. Ideálne je hašovacia funkcia jednoduchá a rýchla, ale pritom hodnoty do tabuľky distribuuje rovnomerne, aby sa príliš často nestávalo, že dva prvky sa namapujú na to isté políčko
int hash(int x, int m) {
return abs(x) % m;
}
Pre m = 5 je táto funkcia znázornená na nasledujúcom obrázku.

Prvý pokus o prácu hašovacou tabuľkou by teda mohol vyzerať takto:
Vkladanie prvku x:
- Spočítame index = hash(x, m) a prvok vložíme na pozíciu hashtable[index].
Vyhľadávanie prvku x:
- Ak je prvok s kľúčom x v tabuľke, musí byť na indexe hash(x, m).
- Skontrolujeme túto pozíciu a ak tam je niečo iné ako x, prvok x sa v tabuľke nenachádza.
Problémy:
- Na akú hodnotu inicializovať prvky poľa hashtable?
- Čo ak budeme potrebovať vložiť prvok na miesto, kde je už niečo uložené?
Kolízie
- Pri vkladaní prvku sme narazili na problém, ak na už obsadené miesto chceme vložiť iný prvok.
- Ak sa dva prvky x a y sa zahašujú na rovnakú pozíciu h(x) = h(y), hovoríme, že nastala kolízia
- Existuje niekoľko metód na riešenie kolízií.
- Existujú rôzne prístupy na riešenie kolízií, môžeme napríklad hľadať iné voľné miesto v tabuľke.
- V našom programe kolízie vyriešime tak, že v každom políčku tabuľky uložíme spájaný zoznam všetkých prvkov, ktoré sa tam zahašovali.
- Táto situácia je znázornená na nasledujúcom obrázku, v ktorom šípky zodpovedajú vkladaniam prvkov (celých čísel) do množiny reprezentovanej hašovacou tabuľkou.

#include <cstdlib>
/* Hasovacia funkcia: */
int h(int x, int m) {
return abs(x) % m;
}
/* Struktura reprezentujuca jeden prvok spajaneho zoznamu: */
struct node {
int data;
node *next;
};
/* Struktura implementujuca dynamicku mnozinu pomocou hasovania: */
struct set {
node **hashtable; // Pole smernikov na zaciatky jednotlivych zoznamov
int m; // Velkost hasovacej tabulky
};
void init(set &s, int m) { // Velkost tabulky bude parametrom funkcie init
s.m = m;
s.hashtable = new node *[m];
for (int i = 0; i < m; i++) {
s.hashtable[i] = NULL;
}
}
bool contains(set &s, int x) {
int index = h(x, s.m); // Spocitame spravne policko hasovacej tabulky
node *p = s.hashtable[index]; // Smernik p ukazuje na prvy prvok spajaneho
// zoznamu na danom policku
while (p != NULL) { // Prechadzame zoznam, hladame x
if (p->data == x) {
return true;
}
p = p->next;
}
return false;
}
void add(set &s, int x) {
int index = h(x, s.m); // Spocitame spravne policko hasovacej tabulky
node *p = new node; // Vytvorime novy uzol do spajaneho zoznamu
p->data = x;
p->next = s.hashtable[index]; // Vlozime uzol temp na zaciatok zoznamu.
s.hashtable[index] = p;
}
void destroy(set &s) {
for (int i = 0; i < s.m; i++) {
node *p = s.hashtable[i]; // Uvolni zoznam s.hashtable[i]
while (p != NULL) {
node *p2 = p->next;
delete p;
p = p2;
}
}
delete[] s.hashtable;
}
Cvičenie: Ako bude vyzerať hašovacia tabuľka pri riešení kolízií pomocou spájaných zoznamov, ak hašovacia funkcia je |x| mod 5 a vkladáme prvky 13, -2, 0, 8, 10, 17?
Zložitosť
- Rýchlosť závisí od veľkosti tabuľky m, hašovacej funkcie a počtu kolízií.
- V najhoršom prípade sa všetky prvky zahašujú do toho istého políčka, a teda musíme pri hľadaní prejsť všetky prvky množiny.
- Ak máme šťastie a v každom políčku máme len málo prvkov, bude aj vyhľadávanie rýchle.
- Ak je tabuľka dosť veľká a hašovacia funkcia vhodne zvolená, tento prípad je pomerne obvyklý.
- Hašovacie tabuľky sa často používajú v praxi.
- Viac budúci rok na predmete Algoritmy a dátové štruktúry.
Prednáška 15
Oznamy
- DÚ2 odovzdávajte dnes do 22:00, posledná DÚ bude zverejnená budúci týždeň.
- Zajtra od 12:00 rektorské voľno kvôli protestu.
- Nebude teda rozcvička, ale pre záujemcov poskytneme konzultácie počas bežného času cvičení cez MS Teams.
- Príklady na tento týždeň sa objavia už dnes po prednáške.
- V stredu je štátny sviatok, nebude teda prednáška.
- Na piatkových doplnkových cvičeniach bude bonusová rozcvička (za 1 bonusový bod), bude sa týkať spájaných zoznamov.
- Môžete sa pýtať aj k ostatným príkladom na tento týždeň.
- Ak sa chcete zúčastniť osobne, zapíšte sa do štvrtka 16:00 do formulára, môžete ale prísť aj online.
Smerníková aritmetika
Na smerníkoch možno vykonávať určité operácie, ktoré sa zvyknú nazývať smerníková aritmetika. Uvažujme číslo n typu int a smerníky p a q na nejaký typ T
int n;
T *p, *q;
- p + n je smerník na n-té políčko za adresou p, pričom veľkosť políčka je daná typom T
- p + n je teda to isté ako &(p[n]) a *(p+n) je to isté ako p[n].
- p++ je skratkou pre p = p + 1, posunie nám teda smerník p o políčko doprava.
- Výraz p[n] je len skratkou pre *(p+n).
- p[n] aj p + n teda chceme používať iba ak p ukazuje na prvok poľa, za ktorým v poli ide ešte aspoň n ďalších políčok
- Podobne p - n je smerník na n-té políčko pred adresou p.
- p - n teda chceme používať iba ak p ukazuje na prvok poľa, pred ktorým v poli ide ešte aspoň n ďalších políčok
- Ak p a q sú adresami prvkov v tom istom poli, p - q je celé číslo k také, že p == q + k, t.j. o koľko políčok je p ďalej vpravo od q.
- Ak p a q sú adresami prvkov v tom istom poli, môžeme ich tiež porovnávať pomocou <, >, <=, >=
- Ľubovoľné dva smerníky toho istého typu vieme porovnávať pomocou ==, !=.
Tu je napr. zvláštny spôsob ako vypísať pole a:
const int n = 4;
int a[n] = {4, 3, 2, 1};
for (int *smernik = a; smernik < a + n; smernik++) {
cout << "Prvok " << smernik - a << " je " << *smernik << endl;
}
Podobný kód sa ale občas používa na prechádzanie reťazcov. Napríklad nasledujúca funkcia spočíta počet medzier v reťazci:
int zratajMedzery(char str[]) { // mohli by sme dat aj char *str
int pocet = 0;
while(*str != 0) { // kym nenajdeme ukoncovaciu nulu v retazci
if(*str == ' ') { // skontroluj znak, na ktory ukazuje smernik
pocet++;
}
str++; // posun smernik na dalsi znak
}
return pocet;
}
Funkcie z knižnice cstring so smerníkovou aritmetikou
- strstr(text, vzorka) vracia smerník na char
- NULL ak sa vzorka nenachádza v texte, smerník na začiatok prvého výskytu inak
- pozíciu výskytu zistíme smerníkovou aritmetikou:
char *text = "Hello world!";
char *vzorka = "or";
char *where = strstr(text, vzorka);
if(where != NULL) {
int position = where - text;
}
- Ako by ste spočítali počet výskytov vzorky v texte?
- Podobne strchr hľadá prvý výskyt znaku v texte
Práca s konzolou na spôsob jazyka C: printf a scanf
- Doposiaľ sme s konzolou pracovali prostredníctvom knižnice iostream, ktorá patrí medzi štandardné knižnice jazyka C++ a v ktorej sú definované prúdy cin a cout.
- Dnes si ukážeme alternatívny prístup k práci s konzolou založený na knižnici cstdio, ktorá je štandardnou knižnicou jazyka C.
Výpis formátovaných dát na konzolu: printf
- S použitím knižnice cstdio možno na konzolu písať pomocou funkcie printf.
- Tu sú príklady jej použitia:
#include <cstdio>
#include <cmath>
using namespace std;
int main() {
int x = 10;
double y = sqrt(x);
printf("Ahoj svet, este raz!\n");
printf("Odmocnina cisla %d je %f.\n", x, y);
}
Tento program vypíše:
Ahoj svet, este raz!
Odmocnina cisla 10 je 3.162278.
Vo všeobecnosti vyzerá volanie printf nasledovne:
printf(format, hodnota1, hodnota2, ...)
- Prvý argument je formátovací reťazec, za ním môže nasledovať niekoľko ďalších argumentov.
- Bežné znaky z formátovacieho reťazca sa priamo vypíšu na výstup.
- Koniec riadku sa píše pomocou "\n".
- Symbol % začína takzvanú špecifikáciu konverzie a má za následok vypísanie ďalšieho argumentu funkcie (prvého, ktorý sa nepoužil).
- V jednoduchých príkladoch za znakom % nasleduje znak reprezentujúci typ vypísanej hodnoty.
- Pozor, typy jednotlivých argumentov musia byť v súlade s formátovacím reťazcom.
- %d: celé číslo (typ int).
- %ld: dlhé celé číslo (typ long int).
- %f: reálne číslo (typ double).
- %e: reálne číslo vo vedeckej notácii, napr. 5.4e7 (typ double).
- %c: znak (typ char).
- %s: reťazec (typ char *).
- %%: vypíše samotný znak %.
Formátovanie výstupu
- Formát vypísania daného argumentu možno upraviť nepovinnými parametrami medzi symbolom % a znakom konverzie.
- Napríklad:
- %.2f: vypíše reálne číslo na 2 desatinné miesta,
- %4d: ak má celé číslo menej ako 4 cifry, doplní vľavo medzery,
- %04d: podobne, ale dopĺňa nuly.
Nasledujúci program vo vhodnom formáte vypíše hodnoty faktoriálu prirodzených čísel od 1 po 20 použitím typu long long int, ktorý garantuje aspoň 64 bitové číslo:
#include <cstdio>
using namespace std;
long long int factorial(int n) {
if (n == 0) {
return 1;
} else {
return n * factorial(n-1);
}
}
int main() {
for (int i = 1; i <= 20; i++) {
printf("%2d! = %22lld\n", i, factorial(i));
}
}
1! = 1
2! = 2
3! = 6
4! = 24
5! = 120
6! = 720
7! = 5040
8! = 40320
9! = 362880
10! = 3628800
11! = 39916800
12! = 479001600
13! = 6227020800
14! = 87178291200
15! = 1307674368000
16! = 20922789888000
17! = 355687428096000
18! = 6402373705728000
19! = 121645100408832000
20! = 2432902008176640000
Nasledujúci program vypíše zadaný dátum vo formáte typu 02.01.2019:
#include <cstdio>
using namespace std;
void vypisDatum(int d, int m, int r) {
printf("%02d.%02d.%04d\n", d, m, r);
}
int main() {
vypisDatum(2, 1, 2019);
}
Celá špecifikácia konverzie pozostáva z nasledujúcich častí:
- Z povinného úvodného znaku %.
- Z nepovinných príznakov, napríklad -, ktorého použitie vyústi v zarovnanie vypisovaného textu vľavo (bez jeho použitia sa text zarovná vpravo). Ďalšími príznakmi sú napríklad 0 (dopĺňanie núl naľavo), + (vypíše znamienko + pri kladných číslach), atď.
- Z nepovinného celého čísla udávajúceho minimálnu šírku výpisu (minimálny počet „políčok”, do ktorých sa text vypíše).
- Z nepovinnej bodky nasledovanej celým číslom udávajúcim presnosť výpisu (pri reálnych číslach napríklad počet desatinných miest; presnosť má však svoju interpretáciu aj pri iných typoch dát).
- Z nepovinného modifikátora l, ll, alebo h pre long, long long, resp. short.
- Z povinného symbolu konverzie (napr. d, f, s, ...).
Načítanie formátovaných dát z konzoly: scanf
Vstup z konzoly sa dá načítať funkciou scanf s typickým volaním
scanf(format, adresa1, adresa2, ...)
- Napríklad scanf("%d", &x) načíta celočíselnú hodnotu do premennej x.
- Zatiaľ čo argumentmi printf sú priamo hodnoty, scanf potrebuje adresy premenných, pretože ich modifikuje.
Pomocou scanf možno načítať aj viacero premenných naraz:
#include <cstdio>
using namespace std;
void vypisDatum(int d, int m, int r) {
printf("%02d.%02d.%04d\n", d, m, r);
}
int main() {
int d, m, r;
printf("Zadaj den, mesiac a rok: ");
scanf("%d %d %d", &d, &m, &r);
vypisDatum(d, m, r);
}
Formátovací reťazec sa v scanf interpretuje nasledovne:
- Špecifikácia typu načítavaných premenných je podobná ako pri funkcii printf.
- %d načíta int
- %lf načíta double (pozor, tu je rozdiel od printf, kde sa double vypisuje pomocou %f)
- %s načíta reťazec, konkrétne jedno slovo, t.j. postupnosť nebielych znakov. Ako argument sa zadá hodnota typu char*, ktorá má ukazovať na dostatočne veľké pole.
- %100s načíta slovo, ale najviac 100 znakov. Pole má mať veľkosť aspoň 101.
- %c načíta jeden znak. Na rozdiel od všetkých predchádzajúcich typov, tu sa nepreskakujú biele znaky pred prvým nebielym
- Biele znaky (angl. whitespace, t.j. medzery, konce riadkov, tabulátory) vo formátovacom reťazci spôsobia, že funkcia scanf číta a ignoruje všetky biele znaky pred ďalším nebielym znakom. Jeden biely znak vo formátovacom reťazci tak umožní ľubovoľný počet bielych znakov na vstupe.
- Ostatné znaky formátovacieho reťazca musia presne zodpovedať vstupu.
Nasledujúci príkaz tak napríklad načíta dátum vo formáte deň.mesiac.rok:
scanf("%d.%d.%d", &d, &m, &r);
Kontrola správnosti vstupu
Funkcia scanf vracia počet úspešne načítaných hodnôt zo vstupu.
- V prípade chyby hneď na začiatku vstupu tak napríklad vráti 0.
- Ak hneď na začiatku narazí na koniec vstupu, vráti hodnotu EOF (typicky -1).
- Vstup z konzoly sa dá ukončiť pod Linuxom ako Ctrl+D resp. pod Windowsom ako Ctrl+Z a Enter
Príklad: zadávanie dátumu vo formáte deň.mesiac.rok s kontrolou vstupu:
#include <cstdio>
using namespace std;
void vypisDatum(int d, int m, int r) {
printf("%02d.%02d.%04d\n", d, m, r);
}
int main() {
int d, m, r;
printf("Zadaj datum: ");
if (scanf("%d.%d.%d", &d, &m, &r) == 3) {
printf("Datum je ");
vypisDatum(d,m,r);
} else {
printf("Nebol zadany korektny datum.\n");
}
}
Ďalší program počíta súčet postupne zadávaných čísel, až kým je zadané nekorektné číslo alebo koniec súboru:
#include <cstdio>
using namespace std;
int main() {
double sum = 0;
double x;
while (scanf("%lf", &x) == 1) {
sum += x;
}
printf("Sucet je %.2f\n", sum);
}
Textové súbory
Na načítavanie a vypisovanie dát sme doposiaľ používali výhradne konzolu. V praxi však často potrebujeme spracovávať dáta uložené v súboroch.
- Zameriame sa na súbory v textovom formáte, s ktorými sa pracuje podobne ako s konzolou.
- V C++ existujú ekvivalenty cin >> a cout << aj pre súbory, nájdete ich v knižnici fstream.
Základy: typ FILE * a funkcie fopen, fclose, fprintf, fscanf
So súbormi sa pri použití knižnice cstdio pracuje pomocou typu FILE * (veľkými písmenami).
- Je to smerník na štruktúru typu FILE, ktorá obsahuje informácie o súbore, s ktorým sa práve pracuje.
- Premenné pre prácu so súbormi tak možno definovať napríklad takto:
FILE *fr, *fw;
Otvorenie súboru pre čítanie
- fr = fopen("vstup.txt", "r");
- Otvorí súbor s názvom vstup.txt (prípadne možno zadať kompletnú cestu k súboru).
- Ak taký súbor neexistuje alebo sa nedá otvoriť, do fr priradí NULL.
- Z otvoreného súboru môžeme čítať napríklad pomocou fscanf, ktorá je analógiou k scanf.
- Napríklad fscanf(fr, "%d", &x);
Otvorenie súboru pre zápis
- fw = fopen("vystup.txt", "w");
- Vytvorí súbor s názvom vystup.txt. Ak už existoval, zmaže jeho obsah (keby sme vo volaní fopen namiesto "w" použili "a", pridávalo by sa na koniec existujúceho súboru).
- Ak sa nepodarí súbor otvoriť, do fw priradí NULL.
- Do otvoreného súboru môžeme zapisovať napr. pomocou funkcie fprintf, ktorá je analógiou k printf.
- Napr. fprintf(fw, "%d", x);
Zatvorenie súboru
- Po ukončení práce so súborom je ho potrebné zavrieť pomocou fclose(f);
- Počet súčasne otvorených súborov je obmedzený.
Príklad
Nasledujúci program načíta číslo n a následne n celých čísel zo súboru vstup.txt. Do súboru vystup.txt vypíše vstupné čísla v opačnom poradí.
#include <cstdio>
#include <cassert>
using namespace std;
int main() {
// otvorime subory a skontrolujeme, ze nie su NULL
FILE *fr = fopen("vstup.txt", "r");
FILE *fw = fopen("vystup.txt", "w");
assert(fr != NULL && fw != NULL);
// nacitame pocet cisel
int n, r;
r = fscanf(fr, "%d", &n);
assert(r == 1 && n >= 0);
// alokujeme pole a nacitame cisla
int *a = new int[n];
for (int i = 0; i < n; i++) {
r = fscanf(fr, "%d", &a[i]);
assert(r == 1);
}
fclose(fr);
// vypiseme cisla odzadu
for (int i = n-1; i >= 0; i--) {
fprintf(fw, "%d ", a[i]);
}
fclose(fw);
delete[] a;
}
Štandardný vstup a výstup ako súbor
So štandardným vstupom a výstupom sa pracuje rovnako ako so súborom. V cstdio sú definované dva konštantné smerníky
FILE *stdin, *stdout;
pre štandardný vstupný a výstupný prúd. Tie tak môžu byť použité v ľubovoľnom kontexte, v ktorom sa očakáva súbor. Napríklad volanie fscanf(stdin, "%d", &x) je ekvivalentné volaniu scanf("%d", &x).
Ten istý kód sa tak dá použiť na prácu so súbormi aj so štandardným vstupom resp. výstupom – stačí len podľa potreby nastaviť premennú typu FILE *. Typické použitie je napríklad nasledovné:
// do retazca str nacitame z konzoly meno suboru alebo pomlcku
char str[101];
scanf("%100s", str);
// do fw otvorime subor alebo pouzijeme konzolu
FILE *fw;
if (strcmp(str, "-") == 0) {
fw = stdout;
} else {
fw = fopen(str, "w");
}
// zapiseme nieco do fw
fprintf(fw, "Hello world!\n");
// ak treba, zatvorime subor
if (strcmp(str, "-") != 0) {
fclose(fw);
}
Testovanie konca súboru
Existujú dve možnosti testovania, či sme dosiahli koniec súboru:
- V knižnici cstdio je definovaná symbolická konštanta EOF, ktorá má väčšinou hodnotu -1. Ak sa funkcii fscanf nepodarí načítať žiadnu hodnotu, pretože načítavanie dospelo ku koncu súboru, vráti konštantu EOF ako svoj výstup.
- Funkcia feof(subor) vráti true práve vtedy, keď sa funkcia fscanf (alebo nejaká iná funkcia) už niekedy pokúšala čítať za koncom súboru subor.
Spracovanie vstupu pozostávajúceho z postupnosti čísel
Často na vstupe očakávame postupnosť číselných hodnôt oddelených bielymi znakmi. Pozrime sa na tri obvyklé možnosti, ako môže byť takýto vstup zadaný a spracovaný pomocou funkcie fscanf.
Formát 1: N (počet čísel) a následne N ďalších čísel.
#include <cstdio>
#include <cassert>
using namespace std;
int main() {
FILE *f;
const int MAXN = 100;
int a[MAXN], N, kod;
f = fopen("vstup.txt", "r");
assert(f != NULL);
kod = fscanf(f, "%d ", &N);
assert(kod == 1 && N >= 0 && N <= MAXN);
for (int i = 0; i < N; i++) {
kod = fscanf(f, "%d ", &a[i]);
assert(kod == 1);
}
fclose(f);
// tu pride spracovanie dat v poli a
}
Formát 2: postupnosť čísel ukončená číslom -1 alebo inou špeciálnou hodnotu.
// otvorime subor f ako vyssie
N = 0;
int x;
kod = fscanf(f, "%d ", &x);
assert(kod == 1);
while (x != -1) {
assert(N < MAXN);
a[N] = x;
N++;
kod = fscanf(f, "%d ", &x);
assert(kod == 1);
}
// zatvorime subor a spracujeme data
Formát 3: čísla, až kým neskončí súbor (najtypickejší prípad v praxi).
Priamočiary prístup nefunguje vždy správne:
// otvorime subor f ako vyssie
N = 0;
while (!feof(f)) {
assert(N < MAXN);
kod = fscanf(f, "%d", &a[N]);
assert(kod == 1); // bude tu padat
N++;
}
// zatvorime subor a spracujeme data
- Tento program nefunguje, ak po poslednom čísle v súbore nasleduje ešte koniec riadku (čo je obvyklé)
- Pri načítaní tohto čísla skončíme na symbole konca riadku, fscanf sa teda nepokúsi čítať za koncom súboru.
- Spustí sa teda ďalšie opakovanie cyklu, v ktorom sa už ale nepodarí ďalšie číslo načítať a assert ukončí program s chybovou hláškou.
- Aj bez príkazu assert by sme mali problém, že do poľa by sa uložila nezmyselná hodnota.
Tento nedostatok môžeme napraviť napríklad tak, že vo volaní funkcie fscanf dáme vo formátovacom reťazci za %d medzeru. Tá sa bude pokúšať preskočiť všetky biele znaky až po najbližší nebiely; pritom natrafí na koniec súboru a feof(f) už bude vracať true.
#include <cstdio>
#include <cassert>
using namespace std;
int main() {
FILE *f;
const int MAXN = 100;
int a[MAXN], N, kod;
f = fopen("vstup.txt", "r");
assert(f != NULL);
N = 0;
while (!feof(f)) {
assert(N < MAXN);
kod = fscanf(f, "%d ", &a[N]);
assert(kod == 1);
N++;
}
fclose(f);
// tu pride spracovanie dat v poli a
}
Cvičenie: upravte úryvky programu vyššie tak, aby pracoval s číslami typu double alebo so slovami.
Prednáška 16
Oznamy
- Na testovači pribudne zadanie tretej (a poslednej) domácej úlohy s odovzdaním do 6. decembra, 22:00.
- Cvičenia tento týždeň sa budú týkať práce so súbormi (táto a minulá prednáška).
- Ak chcete prísť osobne, nezabudnite sa zapísať do tabuľky.
Príklad na prácu s textovými súbormi
- Prácu s textovými súbormi si zopakujeme na nasledujúcom príklade.
- Hlavný vstupný súbor vstup.txt má na prvom riadku názov výstupného súboru.
- Každý z niekoľkých ďalších riadkov obsahuje názov jedného vstupného súboru nasledovaný počtom čísel, ktoré z neho chceme načítať.
- Úlohou je prekopírovať z každého súboru zadaný počet čísel.
Napríklad vstup.txt
vystup.txt a.txt 2 b.txt 1 a.txt 3
Súbor a.txt
1 2 3 4 5 6 7 8 9
Súbor b.txt
10 20 30 40 50 60 70 80 90
Výsledný súboru vystup.txt
1 2 10 1 2 3
Program uvedený nižšie pracuje v nasledujúcich krokoch:
- Otvorí hlavný vstupný súbor vstup.txt a prečíta z neho názov výstupného súboru.
- Otvorí výstupný súbor.
- Následne opakovane prečíta názov súboru a počet čísel N.
- Otvorí súbor s práve načítaným názvom, prekopíruje z neho N čísel do výstupného súboru a následne tento súbor zatvorí.
- Zatvorí hlavný vstupný súbor aj výstupný súbor.
Dĺžka načítavaných reťazcov bude vo volaniach funkcie fscanf obmedzená na 19 znakov
- to teda je maximálna dĺžka názvu súboru, s ktorou bude program vedieť pracovať
#include <cstdio>
#include <cassert>
using namespace std;
int main() {
FILE *fr_main, *fr_part, *fw;
int N, r, num;
fr_main = fopen("vstup.txt", "r");
assert(fr_main != NULL);
char filename[20];
r = fscanf(fr_main, "%19s", filename);
assert(r == 1);
fw = fopen(filename, "w");
assert(fw != NULL);
while (!feof(fr_main)) {
r = fscanf(fr_main, "%19s %d ", filename, &N);
assert(r == 2);
fr_part = fopen(filename, "r");
assert(fr_part != NULL);
for (int i = 0; i < N; i++) {
r = fscanf(fr_part, "%d ", &num);
assert(r == 1);
fprintf(fw, "%d ", num);
}
fclose(fr_part);
}
fclose(fw);
fclose(fr_main);
}
Čítanie a zapisovanie po znakoch
Knižnica cstdio obsahuje aj funkcie na čítanie a zapisovanie súboru po znakoch.
- Funkcia int getc(FILE *f) načíta a vráti jeden znak zo súboru
- Ak načítanie neprebehne úspešne, výslekdom je špeciálna konštanta EOF, ktorá je vždy rôzna od ľubovoľnej hodnoty typu char
- Neukladajte výstupnú hodnotu funkcie getc do premennej typu char, lebo nebudet vedieť rozoznať koniec súboru.
- Funkcia int getchar() je skratka pre getc(stdin), načíta teda jeden znak z konzoly
- Avšak rovnako ako pri scanf sa vstup začne spracovávať až potom, ako používateľ stlačí Enter, nie je takto možné reagovať priamo na stlačenie nejakej klávesy.
- Funkcia int putc(int c, FILE *f) zapíše znak c do súboru.
- Funkcia int putchar(int c) je skratkou pre putc(c, stdout), vypíše teda daný znak na konzolu.
Príklad: kopírovanie súboru
Nasledujúci program skopíruje obsah súboru original.txt do súboru kopia.txt.
#include <cstdio>
using namespace std;
int main() {
FILE *fr = fopen("original.txt", "r");
FILE *fw = fopen("kopia.txt", "w");
int c = getc(fr);
while (c != EOF) {
putc(c, fw);
c = getc(fr);
}
fclose(fr);
fclose(fw);
}
Cvičenie: čo robí nasledujúci program?
- výsledkom priradenia c = getc(fr) je hodnota priradená do premennej c
#include <cstdio>
using namespace std;
int main() {
FILE *fr;
int c;
fr = fopen("vstup.txt", "r");
while ((c = getc(fr)) != '\n') {
putchar(c);
}
putchar(c);
fclose(fr);
}
Funkcia ungetc
- Často sa stáva, že pri načítavaní znakov nájdeme koniec práve načítavaného úseku až po načítaní znaku, ktorý už nie je žiadúce prečítať.
- Vtedy je užitočné posunúť sa v načítavaní o jeden krok nazad.
- Túto úlohu realizuje funkcia int ungetc(int c, FILE * f).
- Väčšinou ako c použijeme posledne načítaným znak zo súboru f
- Môžeme však použiť aj iný znak, ktorý bude virtuálne pridaný na začiatok neprečítanej časti súboru. Súbor sa reálne nemení, ale pri nasledujúcom čítaní z neho sa ako prvý prečíta znak c.
- V prípade úspechu ungetc(c,f) vráti hodnotu c; v prípade neúspechu je výstupom EOF.
- Takéto správanie funkcie ungetc je však garantované len ak sa táto funkcia nevolá viackrát za sebou.
Príklad č. 1: Nasledujúci kus programu skonvertuje reťazec pozostávajúci zo znakov '0' až '9' na zodpovedajúcu číselnú hodnotu. Keď narazí na prvý znak, ktorý nie je cifra, vráti ho, aby sa dal použiť pri ďalšom spracovávaní.
int hodnota = 0;
int c = getchar();
while (c >= '0' && c <= '9') {
hodnota = hodnota * 10 + (c - '0');
c = getchar();
}
ungetc(c, stdin);
Príklad č. 2: Nasledujúci program prečíta číslo pomocou funkcie fscanf, predtým však musí prečítať neznámy počet znakov '$'.
#include <cstdio>
using namespace std;
int main() {
FILE *fr = fopen("vstup.txt", "r");
int c = getc(fr);
while (c == '$') {
c = getc(fr);
}
ungetc(c, fr);
int hodnota;
fscanf(fr, "%d", &hodnota);
printf("%d\n", hodnota);
fclose(fr);
}
Čítanie a zapisovanie po riadkoch
Riadok vieme načítať zo súboru nasledujúcou funkciou
char *fgets(char *str, int n, FILE * f);
Jej argumenty sú
- Pole znakov str, do ktorého sa v prípade úspechu riadok načíta.
- Číslo n je typicky dĺžka poľa str
- Funkcia do poľa str z daného riadku súboru načíta a uloží najviac n-1 znakov a reťazec str následne ukončí znakom 0.
- Smerník f na súbor, z ktorého sa má riadok prečítať.
- Funkcia fgets teda načítava znaky dovtedy, kým narazí na koniec riadku (\n) alebo koniec súboru alebo kým zo súboru neprečíta n-1 znakov.
- Prípadný znak \n na konci riadku sa nezahodí, ale pridá sa na koniec reťazca str (pokiaľ nebolo načítaných príliš veľa znakov).
- Výstupom funkcie je v prípade načítania aspoň jedného znaku načítaný reťazec str; inak je výstupom NULL a reťazec str ostáva nezmenený.
Funkcia int fputs(const char *str, FILE *f) vypíše reťazec str do súboru
- str môže obsahovať hocikoľko koncov riadkov (aj nula)
- pri chybe vráti EOF, inak vráti nezáporné celé číslo
Príklad: nasledujúci program spočíta počet riadkov v súbore vstup.txt (za predpokladu, že žiaden z týchto riadkov nie je dlhší ako 100 znakov vrátane znaku \n na konci riadku):
#include <cstdio>
using namespace std;
const int maxN = 101;
int main() {
char str[maxN];
int num = 0;
FILE *fr = fopen("vstup.txt", "r");
while (fgets(str, maxN, fr) != NULL) {
num++;
}
fclose(fr);
printf("Pocet riadkov je %d\n", num);
}
Cvičenie:
- Zistite, ako sa správa uvedený program, keď posledným znakom v súbore je resp. nie je znak \n.
- Zistite, čo program vypíše na výstup pre súbor, ktorý obsahuje jediný riadok o 200 znakoch.
Prístupy k spracovaniu textového vstupu
Časté schémy spracovania textového súboru:
- Pomocou fscanf načítavame jednotlivé čísla, slová a pod. (vhodné, keď všetky biele znaky považujeme za ekvivalentné oddeľovače)
- Čítame po znakoch pomocou getc (pomerne univerzálne, ale niekedy prácne)
- Čítame po riadkoch pomocou fgets do reťazca, potom reťazec spracovávame (vhodné, keď riadok je ucelená časť súboru, ktorá nás zaujíma)
Niekedy je užitočné tieto prístupy aj kombinovať.
Príklad: chceme nájsť dĺžku najdlhšieho riadku v súbore
- Prvá možnosť je čítanie riadkov do reťazca a ich spracovanie (problém, ak je riadok príliš dlhý)
- Druhá možnosť je čítať súbor po znakoch, pričom si potrebujeme udržiavať "stav": koľko písmen sme už videli v aktuálnom riadku
#include <cstdio>
#include <cstring>
using namespace std;
const int maxN = 100;
int main() {
FILE *fr = fopen("vstup.txt", "r");
int maxDlzka = 0;
char str[maxN];
while (fgets(str, maxN, fr) != NULL) {
int dlzka = strlen(str);
if (dlzka > maxDlzka) {
maxDlzka = dlzka;
}
}
fclose(fr);
printf("Najdlhsi riadok ma dlzku %d\n", maxDlzka);
}
#include <cstdio>
using namespace std;
int main() {
FILE *fr = fopen("vstup.txt", "r");
int maxDlzka = 0;
int dlzka = 0;
int c = getc(fr);
while (c != EOF) {
dlzka++;
if (c == '\n') {
if (dlzka > maxDlzka) {
maxDlzka = dlzka;
}
dlzka = 0;
}
c = getc(fr);
}
if (dlzka > maxDlzka) { // Posledny riadok nemusi koncit symbolom \n.
maxDlzka = dlzka;
}
fclose(fr);
printf("Najdlhsi riadok ma dlzku %d\n", maxDlzka);
}
Cvičenie: čo ak chceme zistiť, koľký riadok v súbore bol ten najdlhší?
Príklad 2: máme súbor s číslami oddelenými bielymi znakmi (medzery, tabulátory, konce riadkov,...), pričom medzi dvoma číslami môže byť aj viac ako jeden oddeľovač. Chceme spočítať súčet čísel na každom riadku.
- Nepríjemná kombinácia rozlišovania koncov riadku od iných bielych znakov a čítania formátovaných hodnôt (čísel)
- Môžeme prečítať riadok do reťazca a rozložiť na čísla (napr. funkciou sscanf a so špecifikáciou konverzie %n, ktorá uloží počet načítaných znakov).
- Program nižšie však používa kombináciu getc, ungetc a fscanf
- Biele znaky spracúva pomocou funkcie getc. Ak je niektorý z týchto znakov koncom riadku, vypíše zistený súčet čísel.
- Po nájdení nebieleho znaku ho vráti do vstupného prúdu funkciou ungetc, prečíta číslo pomocou funkcie fscanf a aktualizuje súčet.
- Na zistenie, či je prečítaný znak biely, využíva program funkciu isspace z knižnice cctype.
- Program predpokladá, že aj posledný riadok vstupného súboru je ukončený symbolom \n.
#include <cstdio>
#include <cctype>
using namespace std;
int main(void) {
FILE *fr = fopen("vstup.txt", "r");
int sucet = 0;
int hodnota;
while (!feof(fr)) {
int c = getc(fr);
// Precitaj biele znaky po najblizsi nebiely.
while (c != EOF && isspace(c)) {
if (c == '\n') { // Na konci riadku vypis sucet.
printf("Sucet %d\n", sucet);
sucet = 0;
}
c = getc(fr);
}
if (c == EOF) { // Koniec suboru
break;
}
ungetc(c, fr);
fscanf(fr, "%d", &hodnota);
sucet += hodnota;
}
fclose(fr);
}
Cvičenia:
- Čo program spraví, ak vstup obsahuje aj prázdne riadky?
- Upravte program, aby pracoval správne aj v prípade, že posledný riadok nie je ukončený symbolom \n.
- Čo vlastne chceme považovať za posledný riadok?
- Upravte program, aby na výstupe vypisoval aj čísla na riadkoch oddelené medzerami.
Jednoduché šifrovanie
Prácu so súbormi si teraz precvičíme na dvoch jednoduchých šifrách.
Caesarova šifra
Caesarova šifra je šifra, pri ktorej sa každé písmeno vstupného reťazca posunie cyklicky o K miest v abecednom poradí, kde K je zadaný parameter šifry.
- Napríklad pre K=2 sa písmeno A zmení na C, písmeno b sa zmení na d a písmeno Z sa zmení na B.
- Ukážeme si jej použitie pre anglickú abecedu (t. j. znaky 'a' až 'z' a 'A' až 'Z' bez diakritiky); je ju ale možné upraviť napríklad aj tak, aby pracovala s ASCII kódmi.
Napríklad pre K=3:
Pôvodný text: HelloWorld Šifrovaný text: KhoorZruog
Nasledujúci program zašifruje súbor.
#include <cstdio>
#include <cassert>
using namespace std;
void encryptCaesar(FILE *fr, FILE *fw, int shift) {
assert(shift >= 0 && shift <= 25);
int c;
while ((c = getc(fr)) != EOF) {
if ((c >= 'A') && (c <= 'Z')) {
c = c + shift;
if (c > 'Z') {
c -= 26;
}
} else if ((c >= 'a') && (c <= 'z')) {
c = c + shift;
if (c > 'z') {
c -= 26;
}
}
putc(c, fw);
}
}
int main() {
int shift;
scanf("%d", &shift); // nacitame parameter o kolko posuvat pismena
FILE *fr = fopen("plaintext.txt", "r");
FILE *fw = fopen("ciphertext.txt", "w");
encryptCaesar(fr, fw, shift);
fclose(fr);
fclose(fw);
}
- Čo program spraví so znakmi, ktoré nie sú písmená?
- Dešifrovanie by fungovalo podobne, akurát by sa posun odpočítaval a ako špeciálny prípad by sa riešilo, keďnový znak má kód menší ako 'a'. Môžeme ale tiež použiť program na 3ifrovanie a posun 26-K, kde K je posun použitý na šifrovanie.
Vigenèrova šifra
Vigenèrova šifra je veľmi podobná Caesarovej; posun však nie je konštantný, ale podľa kľúča.
- Kľúč je reťazec zložený z písmen A až Z, pričom tieto predstavujú posuny o 0 až 25 pozícií v abecede.
- Prvý symbol otvoreného textu je zašifrovaný podľa prvého symbolu kľúča, druhý symbol podľa druhého symbolu kľúča, atď. Po vyčerpaní celého kľúča sa pokračuje cyklicky, opäť od jeho začiatku.
Napríklad pre heslo AHOJ:
Pôvodný text: HelloWorld Heslo: AHOJAHOJAH Šifrovaný text: HlzuoDcalk
Očíslované písmená abecedy:
0:A, 1:B, 2:C, 3:D, 4:E, 5:F, 6:G 7:H, 8:I, 9:J, 10:K, 11:L, 12:M, 13:N 14:O, 15:P, 16:Q, 17:R, 18:S, 19:T, 20:U 21:V, 22:W, 23:X, 24:Y, 25:Z
Nasledujúci program zašifruje súbor.
#include <cstdio>
using namespace std;
const int maxKeyLength = 100;
void encryptVigenere(FILE *fr, FILE *fw, char *key) {
int c;
int i = 0;
while ((c = getc(fr)) != EOF) {
if ((c >= 'A') && (c <= 'Z')) {
c = c + (key[i] - 'A');
if (c > 'Z') {
c -= 26;
}
i++;
} else if ((c >= 'a') && (c <= 'z')) {
c = c + (key[i] - 'A');
if (c > 'z') {
c -= 26;
}
i++;
}
if (key[i] == 0) {
i = 0;
}
putc(c, fw);
}
}
int main() {
// nacitame kluc z konzoly
char key[maxKeyLength];
scanf("%s", key);
// otvorime subory
FILE *fr = fopen("plaintext.txt", "r");
FILE *fw = fopen("ciphertext.txt", "w");
// sifrujeme
encryptVigenere(fr, fw, key);
// zatvorime subory
fclose(fr);
fclose(fw);
}
Nasledujúci program potom dešifruje súbor.
#include <cstdio>
#include <cassert>
using namespace std;
const int maxKeyLength = 100;
void decryptVigenere(FILE *fr, FILE *fw, char *key) {
int c;
int i = 0;
while ((c = getc(fr)) != EOF) {
if ((c >= 'A') && (c <= 'Z')) {
c = c - (key[i] - 'A');
if (c < 'A') {
c += 26;
}
i++;
} else if ((c >= 'a') && (c <= 'z')) {
c = c - (key[i] - 'A');
if (c < 'a') {
c += 26;
}
i++;
}
if (key[i] == 0) {
i = 0;
}
putc(c, fw);
}
}
int main() {
char key[maxKeyLength];
scanf("%s", key);
FILE *fr = fopen("ciphertext.txt", "r");
FILE *fw = fopen("plaintext2.txt", "w");
decryptVigenere(fr, fw, key);
fclose(fr);
fclose(fw);
}
- Caesarova aj Vigenèrova šifra s krátkym kľúčom sa dajú ľahko prelomiť
- O šifrách, ktoré sa v súčasnosti používajú, sa môžete dozvedieť vo vyšších ročníkoch na predmete Kryptológia
Zhrnutie práce so súbormi
- Ukázali sme si prácu so súbormi pomocou knižnice cstdio z jazyka C.
- Súbor je reprezentovaný smerníkom typu FILE *.
- Na otváranie a zatváranie súborov slúžia funkcie fopen, fclose.
- Na vypísanie kombinácie čísel a textov slúži funkcia fprintf, čísla a slová načítavame pomocou fscanf.
- Po znakoch pracujeme funkciami putc a getc, niekedy sa zíde aj ungetc.
- Po riadkoch pracujeme pomocou fgets a fputs.
- V programoch, ktoré sa majú reálne používať, je vhodné kontrolovať, či tieto operácie úspešne zbehli. Tiež pozor na to, aby pri načítaní reťazcov nenastalo pretečenie poľa.
- K niektorým funkciám existujú aj verzie pre konzolu, napr. printf a scanf, putchar, getchar.
- S konzolou tiež môžeme pracovať pomocou premenných stdin, stdout.
Ďalšie možnosti
- Okrem textových súborv existujú aj binárne, kde nie je číslo zapísané ako postupnosť cifier, ale priamo ako bajty.
- Binárne súbory majú často menšiu veľkosť a rýchlejšie sa s nimi pracuje, ťažšie však skontrolujete, čo v súbore je.
- V knižnici cstdio existujú na prácu s binárnymi súbormi funkcie fwrite a fread.
- V C++ sa dá so súbormi pracovať podobne, ako sme používali cin a cout. Potrebné funkcie nájdete v knižnici fstream.
- V jednom programe nekombinujte prácu s konzolou pomocou cstdio a iostream, môže dôjsť k strate dát.
- V mnohých programovacích jazykoch existujú knižnice na načítavanie a zapisovanie často používaných formátov súborov.
Prednáška 17
Oznamy
- Budúci týždeň budú cvičenia v utorok a v piatok iba online, nebude rozcvička, iba príklady, ktoré môžete riešiť do ďalšieho utorka
- Na testovači pribudlo zadanie tretej (a poslednej) domácej úlohy s odovzdaním do 6. decembra, 22:00.
- Tento piatok sa ešte dá prísť na cvičenia osobne, v prípade záujmu si dajte pozor, aby ste boli zapísaní v tabuľke
- Blíži sa semestrálny test
- Treba z neho získať aspoň 50% bodov, inak známka Fx
- Opravný termín bude v januári (iba jeden)
- Pôvodne bola písomka ohlásená na stredu 8.12. večer, ale presúvame ju na piatok 10.12. počas doplnkových cvičení o 11:30
- Ak máte s týmto presunom problém, dajte nám vedieť dnes alebo zajtra
- Večerné termíny bývajú pre študentov náročné
- Ak bude umožnená prezenčná výučba, písomka bude na fakulte, inak online
Abstraktný dátový typ
Abstraktný dátový typ (ADT) je abstrakcia dátovej štruktúry nezávislá od samotnej implementácie.
- Býva zadaný pomocou množiny operácií (hlavičiek funkcií), ktoré poskytuje
- Jeden abstraktný dátový typ môže byť implementovaný pomocou viacerých dátových štruktúr.
Témou 14. prednášky bol napríklad abstraktný dátový typ dynamická množina, ktorý poskytuje tri základné operácie:
- Zistenie príslušnosti prvku do množiny (contains).
- Pridanie prvku do množiny (add).
- Odobranie prvky z množiny (remove).
Videli sme implementácie (pre jednoduchosť bez operácie remove) pomocou neutriedeného poľa, utriedeného poľa, spájaného zoznamu, priameho adresovania a hašovania.
Podobne by sa za ADT dalo považovať dynamické pole s operáciami add, length, get a set.
Výhodou abstraktných dátových typov je oddelenie implementácie dátovej štruktúry od programu, ktorý ju používa.
- Napríklad program pracujúci s dynamickou množinou prostredníctvom funkcií contains, add a remove možno rovnako dobre použiť pri implementácii množiny pomocou neutriedených polí, ako pri jeho implementácii pomocou hešovania.
Témou dnešnej prednášky sú dva nové abstraktné dátové typy.
Rad a zásobník
- Zásobník (angl. stack) a rad alebo front (angl. queue) sú jednoduché abstraktné dátové typy, ktoré udržiavajú postupnosť nejakých prvkov.
- Typicky ide o úlohy alebo dáta čakajúce na spracovanie.
- Rad aj zásobník poskytujú funkciu, ktorá vkladá nový prvok.
- Druhou základnou funkciou je výber jedného prvku, pričom rad sa od zásobníka líši tým, ktorý prvok sa vyberá.
Prvky radu a zásobníka môžu byť ľubovoľného typu. Namiesto konkrétneho typu (ako napríklad int alebo char) tak budeme pracovať so všeobecným typom, ktorý nazveme dataType. Za ten možno dosadiť ľubovoľný konkrétny typ – napríklad int dosadíme za dataType takto:
typedef int dataType;
- Pri využití tohto prístupu tak napríklad bude možné získať z radu prvkov typu int rad prvkov typu char zmenou v jedinom riadku programu.
- Taká istá úprava by sa dala spraviť aj pri ADT množina a dynamické pole.
Rad
- Z radu sa zakaždým vyberie ten jeho prvok, ktorý doň bol vložený ako prvý spomedzi jeho aktuálnych prvkov.
- Možno ho tak pripodobniť k radu pri pokladni v obchode.
- Takáto metóda manipulácie s dátami sa v angličtine označuje skratkou FIFO, podľa first in, first out.
Abstraktný dátový typ pre rad poskytuje tieto operácie (kde queue je názov štruktúry reprezentujúcej rad):
/* Inicializuje prazdny rad */
void init(queue &q);
/* Zisti, ci je rad prazdny */
bool isEmpty(queue &q);
/* Prida prvok item na koniec radu */
void enqueue(queue &q, dataType item);
/* Odoberie prvok zo zaciatku radu a vrati jeho hodnotu */
dataType dequeue(queue &q);
/* Vrati prvok zo zaciatku radu, ale necha ho v rade */
dataType peek(queue &q);
/* Uvolni pamat */
void destroy(queue &q);
Zásobník
- Zo zásobníka sa naopak zakaždým vyberie ten prvok, ktorý doň bol vložený ako posledný.
- Môžeme si ho predstaviť ako stĺpec tanierov, kde umyté taniere dávame na vrch stĺpca a tiež z vrchu aj berieme taniere na použitie.
- Táto metóda manipulácie s dátami sa v angličtine označuje skratkou LIFO, podľa last in, first out.
Abstraktný dátový typ pre zásobník poskytuje tieto operácie (stack je názov štruktúry reprezentujúcej zásobník):
/* Inicializuje prazdny zasobnik */
void init(stack &s);
/* Zisti, ci je zasobnik prazdny */
bool isEmpty(stack &s);
/* Prida prvok item na vrch zasobnika */
void push(stack &s, dataType item);
/* Odoberie prvok z vrchu zasobnika a vrati jeho hodnotu */
dataType pop(stack &s);
/* Vrati prvok na vrchu zasobnika, ale necha ho v zasobniku */
dataType peek(stack &s);
/* Uvolni pamat */
void destroy(stack &s);
Programy využívajúce rad a zásobník
Bez ohľadu na samotnú implementáciu vyššie uvedených funkcií vieme písať programy, ktoré ich využívajú. Napríklad nasledujúci program pracuje s radom:
#include <iostream>
using namespace std;
typedef int dataType;
/* Sem pride definicia struktury queue a vsetkych potrebnych funkcii. */
int main() {
queue q;
init(q);
enqueue(q, 1);
enqueue(q, 2);
enqueue(q, 3);
cout << dequeue(q) << endl; // Vypise 1
cout << dequeue(q) << endl; // Vypise 2
cout << dequeue(q) << endl; // Vypise 3
destroy(q);
}
Podobne nasledujúci program pracuje so zásobníkom:
#include <iostream>
using namespace std;
typedef int dataType;
/* Sem pride definicia struktury stack a vsetkych potrebnych funkcii. */
int main() {
stack s;
init(s);
push(s, 1);
push(s, 2);
push(s, 3);
cout << pop(s) << endl; // Vypise 3
cout << pop(s) << endl; // Vypise 2
cout << pop(s) << endl; // Vypise 1
destroy(s);
}
Poznámka:
- V objektovo-orientovanom programovaní (budúci semester) sa namiesto napr. push(s,10) píše niečo ako s.push(10)
Implementácia zásobníka a radu
Zásobník pomocou poľa
- Na úvod implementujeme zásobník pomocou poľa items, ktoré budeme alokovať na fixnú dĺžku maxN (rovnako dobre by sme však mohli použiť aj dynamické pole).
- Spodok zásobníka pritom bude v tomto poli uložený na pozícii 0 a jeho vrch na pozícii top.
- V prípade, že je zásobník prázdny, bude hodnota premennej top rovná -1.
#include <cassert>
typedef int dataType;
const int maxN = 1000;
struct stack {
// Alokovane pole prvkov zasobnika.
dataType *items;
// Index vrchu zasobnika v poli items, -1 ak prazdny
int top;
};
/* Inicializuje prazdny zasobnik */
void init(stack &s) {
s.items = new dataType[maxN];
s.top = -1;
}
/* Zisti, ci je zasobnik prazdny */
bool isEmpty(stack &s) {
return s.top == -1;
}
/* Prida prvok item na vrch zasobnika */
void push(stack &s, dataType item) {
assert(s.top <= maxN - 2);
s.top++;
s.items[s.top] = item;
}
/* Odoberie prvok z vrchu zasobnika a vrati jeho hodnotu */
dataType pop(stack &s) {
assert(!isEmpty(s));
s.top--;
return s.items[s.top + 1];
}
/* Vrati prvok na vrchu zasobnika, ale necha ho v zasobniku */
dataType peek(stack &s) {
assert(!isEmpty(s));
return s.items[s.top];
}
/* Uvolni pamat */
void destroy(stack &s) {
delete[] s.items;
}
Rad pomocou poľa
- Rad sa od zásobníka líši tým, že prvky sa z neho vyberajú z opačnej strany, než sa doň vkladajú.
- Keby sa prvý prvok radu udržiaval na pozícii 0, museli by sa po každom výbere prvku tie zvyšné posunúť o jednu pozíciu doľava, čo je časovo neefektívne.
- Rad teda implementujeme tak, aby jeho začiatok mohol byť na ľubovoľnej pozícii first poľa items.
- Pole items pritom budeme chápať ako cyklické – prvky s indexom menším ako first budeme interpretovať ako nasledujúce za posledným prvkom poľa.
#include <cassert>
typedef int dataType;
const int maxN = 1000;
struct queue {
dataType *items; // Alokovane pole obsahujuce prvky radu.
int first; // Index prveho prvku radu v poli items.
int count; // Pocet prvkov v rade.
};
/* Inicializuje prazdny rad */
void init(queue &q) {
q.items = new dataType[maxN];
q.first = 0;
q.count = 0;
}
/* Zisti, ci je rad prazdny */
bool isEmpty(queue &q) {
return q.count == 0;
}
/* Prida prvok item na koniec radu */
void enqueue(queue &q, dataType item) {
assert(q.count < maxN);
int index = (q.first + q.count) % maxN;
q.items[index] = item;
q.count++;
}
/* Odoberie prvok zo zaciatku radu a vrati jeho hodnotu */
dataType dequeue(queue &q) {
assert(!isEmpty(q));
dataType result = q.items[q.first];
q.first = (q.first + 1) % maxN;
q.count--;
return result;
}
/* Vrati prvok zo zaciatku radu, ale necha ho v rade */
dataType peek(queue &q) {
assert(!isEmpty(q));
return q.items[q.first];
}
/* Uvolni pamat */
void destroy(queue &q) {
delete[] q.items;
}
Zásobník pomocou spájaného zoznamu
- Zásobník teraz interpretujeme pomocou spájaného zoznamu.
- Na rozdiel od implementácie pomocou poľa bude výhodnejšie uchovávať vrch zásobníka ako prvý prvok zoznamu.
- Pri jednosmerne spájaných zoznamoch je totiž jednoduchšie vkladať a odoberať prvky na jeho začiatku.
- Výhoda tohto prístupu oproti implementácii pomocou poľa je v tom, že maximálny počet prvkov v zásobníku nebude obmedzený konštantou maxN. Podobný efekt je možné docieliť aj dynamického poľa, tam však dochádza k realokácii.
#include <cassert>
typedef int dataType;
struct node {
dataType data;
node *next;
};
struct stack {
node *top; // Smernik na vrch zasobnika (zaciatok spajaneho zoznamu). Ak je zasobnik prazdny, ma hodnotu NULL.
};
/* Inicializuje prazdny zasobnik */
void init(stack &s) {
s.top = NULL;
}
/* Zisti, ci je zasobnik prazdny */
bool isEmpty(stack &s) {
return s.top == NULL;
}
/* Prida prvok item na vrch zasobnika */
void push(stack &s, dataType item) {
node *tmp = new node;
tmp->data = item;
tmp->next = s.top;
s.top = tmp;
}
/* Odoberie prvok z vrchu zasobnika a vrati jeho hodnotu */
dataType pop(stack &s) {
assert(!isEmpty(s));
dataType result = s.top->data;
node *tmp = s.top->next;
delete s.top;
s.top = tmp;
return result;
}
/* Vrati prvok na vrchu zasobnika, ale necha ho v zasobniku */
dataType peek(stack &s) {
assert(!isEmpty(s));
return s.top->data;
}
/* Uvolni pamat */
void destroy(stack &s) {
while (!isEmpty(s)) {
pop(s);
}
}
Rad pomocou spájaného zoznamu
- Pri implementácii radu pomocou spájaného zoznamu rozšírime spájané zoznamy zo 14. prednášky o smerník last na posledný prvok zoznamu.
- Bude tak možné efektívne vkladať prvky na koniec zoznamu, ako aj odoberať prvky zo začiatku zoznamu.
- Výhodou oproti implementácii radu pomocou poľa je, podobne ako pri zásobníkoch, eliminácia obmedzenia na maximálny počet prvkov v rade.
#include <cassert>
typedef int dataType;
struct node {
dataType data;
node *next;
};
struct queue {
// Smernik na prvy uzol. Ak je rad prazdny, ma hodnotu NULL.
node *first;
// Smernik na posledny uzol. Ak je rad prazdny, ma hodnotu NULL.
node *last;
};
/* Inicializuje prazdny rad */
void init(queue &q) {
q.first = NULL;
q.last = NULL;
}
/* Zisti, ci je rad prazdny */
bool isEmpty(queue &q) {
return q.first == NULL;
}
/* Prida prvok item na koniec radu */
void enqueue(queue &q, dataType item) {
node *tmp = new node;
tmp->data = item;
tmp->next = NULL;
if (isEmpty(q)) {
q.first = tmp;
q.last = tmp;
} else {
q.last->next = tmp;
q.last = tmp;
}
}
/* Odoberie prvok zo zaciatku radu a vrati jeho hodnotu */
dataType dequeue(queue &q) {
assert(!isEmpty(q));
dataType result = q.first->data;
node *tmp = q.first->next;
delete q.first;
if (tmp == NULL) {
q.first = NULL;
q.last = NULL;
} else {
q.first = tmp;
}
return result;
}
/* Vrati prvok zo zaciatku radu, ale necha ho v rade */
dataType peek(queue &q) {
assert(!isEmpty(q));
return q.first->data;
}
/* Uvolni pamat */
void destroy(queue &q) {
while (!isEmpty(q)) {
dequeue(q);
}
}
Použitie zásobníka a radu
Zásobník aj rad často uchovávajú dáta určené na spracovanie, zoznamy úloh, atď. Rad sa zvyčajne používa v prípadoch, keď je žiadúce zachovať ich poradie. Typicky môže ísť o situácie, keď jeden proces generuje úlohy spracúvané iným procesom, napríklad:
- Textový procesor pripravuje strany na tlač a vkladá ich do radu, z ktorého ich tlačiareň (resp. jej ovládač) postupne vyberá.
- Sekvenčne vykonávané výpočtové úlohy čakajú v rade na spustenie.
- Zákazníci čakajú na zákazníckej linke na voľného operátora.
- Pasažieri na standby čakajú na voľné miesto v lietadle.
Zásobník sa, ako o niečo implementačne jednoduchší koncept, zvyčajne používa v situáciách, keď na poradí spracúvania nezáleží, alebo keď je žiadúce vstupné poradie obrátiť. Najvýznamnejší príklad situácie druhého typu je nasledujúci:
- Operačný systém ukladá lokálne premenné volaných funkcií na tzv. zásobníku volaní (angl. call stack), čo umožňuje používanie rekurzie.
- Rekurzívne programy sa dajú prepísať na nerekurzívne pomocou „ručne vytvoreného” zásobníka (neskôr si napríklad ukážeme nerekurzívnu verziu triedenia Quick Sort).
Príklad: kontrola uzátvorkovania
Ako jednoduchý príklad na použitie zásobníka uvažujme nasledujúcu situáciu: na vstupe je daný reťazec pozostávajúci (okrem prípadných ďalších znakov, ktoré možno ignorovať) zo zátvoriek (,),[,],{,}. Úlohou je zistiť, či je tento reťazec dobre uzátvorkovaný. To znamená, že:
- Pre každú uzatváraciu zátvorku musí byť posledná dosiaľ neuzavretá otváracia zátvorka rovnakého typu, pričom musí existovať aspoň jedna dosiaľ neuzavretá zátvorka.
- Každá otváracia zátvorka musí byť niekedy neskôr uzavretá.
Príklady očakávaného vstupu a výstupu:
()
Retazec je dobre uzatvorkovany
nejaky text bez zatvoriek
Retazec je dobre uzatvorkovany
[((({}[])[]))]()
Retazec je dobre uzatvorkovany
[[))
Retazec nie je dobre uzatvorkovany
())(
Retazec nie je dobre uzatvorkovany
((
Retazec nie je dobre uzatvorkovany
((cokolvek
Retazec nie je dobre uzatvorkovany
- Nasledujúci program postupne prechádza cez vstupný reťazec, pričom pre každú otváraciu zátvorku si na zásobník pridá uzatváraciu zátvorku rovnakého typu.
- Ak narazí na uzatváraciu zátvorku, výraz môže byť dobre uzátvorkovaný len v prípade, že je na zásobníku aspoň jedna zátvorka, pričom zátvorka na vrchu zásobníka sa zhoduje so zátvorkou na vstupe.
- V prípade úspešného prechodu cez celý vstup je reťazec dobre uzátvorkovaný práve vtedy, keď na zásobníku nezostala žiadna zátvorka.
#include <iostream>
#include <cassert>
using namespace std;
typedef char dataType;
/* Sem pride definicia struktury stack a vsetkych potrebnych funkcii. */
int main() {
char vyraz[100];
cin.getline(vyraz, 100);
stack s;
init(s);
bool dobre = true;
for (int i = 0; vyraz[i] != 0; i++) {
switch (vyraz[i]) {
case '(':
push(s, ')');
break;
case '[':
push(s, ']');
break;
case '{':
push(s, '}');
break;
case ')':
case ']':
case '}':
if (isEmpty(s)) {
dobre = false;
} else {
char c = pop(s);
if (c != vyraz[i]) {
dobre = false;
}
}
break;
}
}
dobre = dobre && isEmpty(s);
destroy(s);
if (dobre) {
cout << "Retazec je dobre uzatvorkovany." << endl;
} else {
cout << "Retazec nie je dobre uzatvorkovany." << endl;
}
}
Cvičenie: Prepíšte program na kontrolu zátvoriek do rekurzívnej podoby. Použite pritom iba premenné typu char; špeciálne nepoužívajte žiadne polia. Reťazec načítavajte pomocou funkcií getc a ungetc. Môžete predpokladať, že je ukončený koncom riadku.
Prednáška 18
Opakovanie: zásobník a rad
- Zásobník (angl. stack) a rad alebo front (angl. queue) sú abstraktné dátové typy, ktoré udržiavajú postupnosť nejakých prvkov.
- Obidva typy podporujú vloženie prvku a výber prvky
- Zo zásobníka sa vyberá prvok, ktorý v ňom pobudol najkratšie, z radu prvok, ktorý v ňom bol najdlhšie
- Zásobník tak pripomína stĺpec čistých tanierov v reštaurácii, rad pripomína rad pri pokladni
Konkrétne funkcie hlavičky funkcií
void init(stack &s); bool isEmpty(stack &s); void push(stack &s, dataType item); // vlozenie prvku dataType pop(stack &s); // vyber prvku dataType peek(stack &s); void destroy(stack &s); void init(queue &q); bool isEmpty(queue &q); void enqueue(queue &q, dataType item); // vlozenie prvku dataType dequeue(queue &q); // vyber prvku dataType peek(queue &q); void destroy(queue &q);
- Pre obidva typy sme videli implementáciu v poli aj v spájanom zozname
- Hlavné funkcie vkladania a vyberania sú v obidvoch implementáciách rýchle a jednoduché
Videli sme tiež, že obidve štruktúry sa dajú použiť na ukladanie dát alebo úloh, ktoré ešte treba vyriešiť
- Dnes uvidíme ďalšie príklady
Použitie zásobníka a radu: nerekurzívny Quick Sort
Pripomeňme si triedenie Quick Sort z 11. prednášky:
void swap (int &x, int &y) {
int tmp = x;
x = y;
y = tmp;
}
int partition(int a[], int left, int right) {
int pivot = a[left];
int lastSmaller = left;
for (int unknown = left + 1; unknown <= right; unknown++) {
if (a[unknown] < pivot) {
lastSmaller++;
swap(a[unknown], a[lastSmaller]);
}
}
swap(a[left],a[lastSmaller]);
return lastSmaller;
}
void quicksort(int a[], int left, int right) {
if (left >= right) {
return;
}
int middle = partition(a, left, right);
quicksort(a, left, middle-1);
quicksort(a, middle+1, right);
}
int main() {
// ...
quicksort(a, 0, N-1);
// ...
}
Namiesto rekurzie môžeme použiť aj zásobník úsekov, ktoré ešte treba dotriediť.
struct usek {
int left;
int right;
};
typedef usek dataType;
/* Sem pride definicia struktury stack a vsetkych potrebnych funkcii. */
/* Sem pridu funkcie swap a partition rovnake ako vyssie. */
void quicksort(int a[], int n) {
stack s;
init(s);
usek u;
u.left = 0;
u.right = n-1;
push(s,u);
while (!isEmpty(s)) {
u = pop(s);
// vynechame useky dlzky 0 a 1
if (u.left >= u.right) {
continue;
}
int middle = partition(a, left, right);
usek u1;
u1.left = u.left;
u1.right = middle - 1;
usek u2;
u2.left = middle + 1;
u2.right = u.right;
push(s,u2);
push(s,u1);
}
destroy(s);
}
int main() {
// ...
quicksort(a, N);
// ...
}
- Tento program triedi úseky v rovnakom poradí, ako rekurzívny Quick Sort, lebo po rozdelení poľa na dve časti dá na vrch zásobníka úsek zodpovedajúci jeho ľavej časti. Až keď sa táto ľavá časť a všetky podúlohy, ktoré z nej vzniknú, spracuje, dôjde na spracovanie pravej časti poľa.
- Pri triedení Quick Sort však na tomto poradí nezáleží, takže by sme mohli jednotlivé úseky vkladať na zásobník aj v opačnom poradí.
- Alebo by sme namiesto zásobníka mohli použiť rad. Potom by najskôr rozdelil ľavú aj pravú časť na ďalšie podčasti a potom by delil každú z týchto podčastí atď.
Na zamyslenie: ako by mohla vyzerať nerekurzívna verzia triedenia Merge Sort? Prečo sa nedá použiť rovnaký prístup ako pri triedení Quick Sort?
Vyfarbovanie súvislých oblastí
Uvažujme obrazec daný obdĺžnikovou maticou o m riadkoch a n stĺpcoch. Obdĺžnikové plátno je v takom prípade rozdelené na m krát n „štvorčekov” určitej konštantnej veľkosti, pričom jednotlivé prvky matice zodpovedajú farbám jednotlivých týchto štvorčekov. V našom jednoduchom príklade budeme pracovať iba s piatimi farbami, ktoré budeme reprezentovať číslami 0,..,4 podľa nasledujúceho poľa (napríklad číslo 0 teda reprezentuje bielu farbu):
const char *farby[5] = {"white", "blue", "black", "yellow", "red"};
Napríklad obrazec

tak môže byť reprezentovaný nasledujúcim textovým súborom obsahujúcim najprv rozmery matice (čísla m a n) a za nimi samotné prvky matice:
11 17 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 1 1 1 1 1 1 1 1 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 1 0 0 0 0 0 2 2 1 2 2 2 2 0 0 0 0 1 0 0 0 0 0 2 0 1 0 0 0 2 0 0 2 2 2 2 2 2 2 0 2 2 1 2 2 2 2 0 0 2 0 1 0 0 0 2 0 0 0 1 0 0 0 0 0 0 2 0 1 0 0 0 2 0 0 0 1 0 1 1 1 1 0 2 0 1 1 1 1 2 1 1 1 1 0 1 0 0 1 0 2 0 0 0 0 0 2 0 0 0 0 0 1 1 1 1 0 2 2 2 2 2 2 2 0 0 0 0 0 0 0 0 0
Zameriame sa teraz na nasledujúci problém: používateľ zvolí (zadá na konzolu) súradnice niektorého „štvorčeka” a cieľom je ofarbiť nejakou farbou (napríklad červenou) celú súvislú oblasť rovnakej farby obsahujúcu daný štvorček. Napríklad pre obrazec vyššie a vstupné súradnice (2,1) – to znamená pre „štvorček” v treťom riadku a druhom stĺpci, keďže matica sa bude indexovať od nuly – by mal byť výstupom nasledujúci obrazec:

Podobný problém je napríklad často potrebné riešiť v rôznych nástrojoch na prácu s grafikou (kde sa namiesto „štvorčekov” ofarbujú pixely) a podobne.
Základ programu
Funkciu na vyfarbovanie súvislých oblastí budeme dorábať do nasledujúcej kostry programu, ktorá obsahuje funkcie na inicializáciu matice, jej načítanie zo súboru, vykresľovanie jednotlivých štvorčekov a celej matice, ako aj uvoľnenie pamäte. Všetky tieto funkcie pracujú podobne ako pri príklade s výškovou mapou z prednášky č. 13. Nasledujúca kostra tiež obsahuje funkciu main, ktorá načíta maticu zo súboru vstup.txt a následne zatiaľ len vykreslí ňou reprezentovaný obrazec do súboru matica.svg.
#include "SVGdraw.h"
#include <cstdio>
#include <cassert>
const char *farby[5] = {"white", "blue", "black", "yellow", "red"};
const int stvorcek = 40; // velkost stvorceka v pixeloch
const int hrubkaCiary = 2; // hrubka ciary v pixeloch
/* Vytvori maticu s n riadkami a m stlpcami. */
int **vytvorMaticu(int m, int n) {
int **a;
a = new int *[m];
for (int i = 0; i <= m - 1; i++) {
a[i] = new int[n];
}
return a;
}
/* Uvolni pamat matice a s n riadkami a m stlpcami. */
void zmazMaticu(int m, int n, int **a) {
for (int i = 0; i <= m - 1; i++) {
delete[] a[i];
}
delete[] a;
}
/* Vykresli stvorcek v riadku i a stlpci j s farbou vyplne farba a farbou ciary farbaCiary. */
void vykresliStvorcek(int i, int j, const char *farba, const char *farbaCiary, SVGdraw &drawing) {
drawing.setLineColor(farbaCiary);
drawing.setLineWidth(hrubkaCiary);
drawing.setFillColor(farba);
drawing.drawRectangle(j * stvorcek, i * stvorcek, stvorcek, stvorcek);
}
/* Vykresli maticu a s n riadkami a m stlpcami. */
void vykresliMaticu(int m, int n, int **a, SVGdraw &drawing) {
for (int i = 0; i <= m - 1; i++) {
for (int j = 0; j <= n - 1; j++) {
vykresliStvorcek(i, j, farby[a[i][j]], "lightgray", drawing);
}
}
}
/* Nacita z textoveho suboru, na ktory ukazuje fr, prvky matice a s n riadkami a m stlpcami. */
void nacitajMaticu(FILE *fr, int m, int n, int **a) {
assert(fr != NULL);
for (int i = 0; i <= m - 1; i++) {
for (int j = 0; j <= n - 1; j++) {
fscanf(fr, "%d", &a[i][j]);
}
}
}
int main(void) {
FILE *fr = fopen("vstup.txt", "r");
assert(fr != NULL);
int m, n;
fscanf(fr, "%d", &m); // nacitaj rozmery matice
fscanf(fr, "%d", &n);
int **a = vytvorMaticu(m, n);
nacitajMaticu(fr, m, n, a); // nacitaj jednotlive prvky matice
fclose(fr);
SVGdraw drawing(n * stvorcek, m * stvorcek, "matica.svg");
vykresliMaticu(m, n, a, drawing);
drawing.finish();
zmazMaticu(m, n, a);
return 0;
}
Rekurzívne vyfarbovanie
Vyfarbovanie súvislých oblastí potom môžeme realizovať napríklad nasledujúcou rekurzívnou funkciou vyfarbi, ktorá vždy na cieľovú farbu farba prefarbí políčko so súradnicami (riadok, stlpec) a následne sa rekurzívne zavolá pre všetkých susedov tohto políčka, ktoré sú zafarbené pôvodnou farbou prefarbovanej oblasti.
Za každým vyfarbením „štvorčeka” navyše voláme funkciu drawing.wait s parametrom pauza, čo je konštanta, ktorú na úvod nastavíme na 0,3 sekundy. Výsledný SVG súbor tak bude obsahovať animáciu postupného vyfarbovania jednotlivých políčok. Farbou „rámika” okolo políčka budeme navyše rozlišovať, či už bolo dané políčko úplne spracované (t. j. či sa už ukončilo rekurzívne volanie funkcie vyfarbi pre toto políčko).
const double pauza = 0.3; // pauza po kazdom kroku vyfarbovania v sekundach
/* Prefarbi suvislu jednofarebnu oblast obsahujucu poziciu (riadok,stlpec) na farbu s cislom farba. */
void vyfarbi(int m, int n, int **a, int riadok, int stlpec, int farba, SVGdraw &drawing) {
int staraFarba = a[riadok][stlpec];
if (staraFarba == farba) {
return;
}
a[riadok][stlpec] = farba;
vykresliStvorcek(riadok, stlpec, farby[farba], "brown", drawing);
drawing.wait(pauza);
if (riadok - 1 >= 0 && a[riadok - 1][stlpec] == staraFarba) {
vyfarbi(m, n, a, riadok - 1, stlpec, farba, drawing);
}
if (riadok + 1 <= m - 1 && a[riadok + 1][stlpec] == staraFarba) {
vyfarbi(m, n, a, riadok + 1, stlpec, farba, drawing);
}
if (stlpec - 1 >= 0 && a[riadok][stlpec - 1] == staraFarba) {
vyfarbi(m, n, a, riadok, stlpec - 1, farba, drawing);
}
if (stlpec + 1 <= n - 1 && a[riadok][stlpec + 1] == staraFarba) {
vyfarbi(m, n, a, riadok, stlpec + 1, farba, drawing);
}
vykresliStvorcek(riadok, stlpec, farby[farba], "lightgray", drawing);
drawing.wait(pauza);
}
Funkcia main potom môže vyzerať napríklad nasledovne:
int main(void) {
FILE *fr = fopen("vstup.txt", "r");
assert(fr != NULL);
int m, n;
fscanf(fr, "%d", &m); // nacitaj rozmery matice
fscanf(fr, "%d", &n);
int **a = vytvorMaticu(m, n);
nacitajMaticu(fr, m, n, a); // nacitaj jednotlive prvky matice
fclose(fr);
SVGdraw drawing(n * stvorcek, m * stvorcek, "matica.svg");
vykresliMaticu(m, n, a, drawing);
int riadok, stlpec;
scanf("%d", &riadok);
scanf("%d", &stlpec);
vyfarbi(m, n, a, riadok, stlpec, 4, drawing);
drawing.finish();
zmazMaticu(m, n, a);
return 0;
}
Počítanie ostrovov
Obrazec, s ktorým sme pracovali vyššie, môže reprezentovať napríklad jednoduchú mapu súostrovia, kde more je znázornené modrou farbou a pevnina je znázornená žltou farbou. Úlohou môže byť zistiť počet ostrovov. Ten môžeme zistiť napríklad takto:
- Prechádzame postupne všetky políčka mapy.
- Ak narazíme na pevninu (t. j. žlté políčko), zvýšime doposiaľ nájdený počet ostrovov o 1 a ofarbíme celý ostrov (napríklad) na červeno.
- Ak narazíme na ďalšie žlté políčko, opäť urobíme to isté.
- Toto robíme, až kým prejdeme cez všetky políčka mapy.
Príklad mapy a jej zobrazenie pred začiatkom hľadania ostrovov, po nájdení prvých troch ostrovov a po nájdení všetkých ostrovov:
11 17 1 1 1 1 1 1 3 1 1 1 1 1 1 1 1 1 1 1 1 1 3 3 3 3 1 1 3 1 1 1 1 3 3 1 1 1 1 3 3 1 1 1 1 1 1 1 1 1 3 3 1 1 1 3 3 1 1 1 1 1 3 3 1 3 3 3 3 1 1 1 1 3 3 1 1 1 1 3 1 1 3 3 3 3 1 1 3 3 3 3 1 3 3 1 3 3 1 3 3 3 3 1 1 1 3 3 1 1 1 3 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 3 3 3 1 1 3 3 3 1 1 1 1 1 1 1 1 1 3 3 3 1 1 3 1 3 1 1 1 1 3 3 3 3 1 3 1 1 1 1 3 3 3 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1



Do programu z vyššia teda dorobíme funkciu
int najdiOstrovy(int m, int n, int **a, SVGdraw &drawing) {
int ostrovov = 0;
for (int i = 0; i <= m - 1; i++) {
for (int j = 0; j <= n - 1; j++) {
if (a[i][j] == 3) {
ostrovov++;
vyfarbi(m, n, a, i, j, 4, drawing);
}
}
}
return ostrovov;
}
a funkciu main môžeme zmeniť napríklad takto:
int main(void) {
FILE *fr = fopen("ostrovy.txt", "r");
assert(fr != NULL);
int m, n;
fscanf(fr, "%d", &m);
fscanf(fr, "%d", &n);
int **a = vytvorMaticu(m, n);
nacitajMaticu(fr, m, n, a);
fclose(fr);
SVGdraw drawing(n * stvorcek, m * stvorcek, "mapa.svg");
vykresliMaticu(m, n, a, drawing);
int pocetOstrovov = najdiOstrovy(m, n, a, drawing);
printf("Pocet ostrovov je %d.\n", pocetOstrovov);
drawing.finish();
zmazMaticu(m, n, a);
return 0;
}
Cvičenie: upravte funkciu najdiOstrovy tak, aby ešte navyše zistila, či má niektorý z ostrovov jazero.
Vyfarbovanie s použitím zásobníka
S použitím niektorej implementácie zásobníka z minulej prednášky môžeme napísať aj nerekurzívnu verziu funkcie vyfarbi. Tá zakaždým vyberie zo zásobníka niektoré políčko. Ak ešte nebolo ofarbené, ofarbí ho a vloží na zásobník všetkých jeho susedov, ktorých je ešte potrebné ofarbiť.
Drobnou zmenou bude, že súradnice jednotlivých susedov budeme počítať s použitím cyklu for a polí deltaStlpec a deltaRiadok, ktoré pre i = 0,1,2,3 obsahujú posuny jednotlivých súradníc i-teho suseda oproti práve spracúvanému políčku.
struct policko {
int riadok, stlpec;
};
typedef policko dataType;
/* Sem pride definicia struktury pre zasobnik a funkcii poskytovanych zasobnikom. */
const int deltaRiadok[4] = {0, 0, 1, -1};
const int deltaStlpec[4] = {1, -1, 0, 0};
/* Prefarbi suvislu jednofarebnu oblast obsahujucu poziciu (riadok,stlpec) na farbu s cislom farba. */
void vyfarbi(int m, int n, int **a, int riadok, int stlpec, int farba, SVGdraw &drawing) {
int staraFarba = a[riadok][stlpec];
if (staraFarba == farba) {
return;
}
stack s;
init(s);
policko p;
p.riadok = riadok;
p.stlpec = stlpec;
push(s, p);
while (!isEmpty(s)) {
p = pop(s);
if (a[p.riadok][p.stlpec] == farba) {
continue;
}
a[p.riadok][p.stlpec] = farba;
vykresliStvorcek(p.riadok, p.stlpec, farby[farba], "lightgrey", drawing);
drawing.wait(pauza);
for (int i = 0; i <= 3; i++) {
policko sused;
sused.riadok = p.riadok + deltaRiadok[i];
sused.stlpec = p.stlpec + deltaStlpec[i];
if (sused.riadok >= 0 && sused.riadok <= m - 1 && sused.stlpec >= 0 && sused.stlpec <= n - 1 &&
a[sused.riadok][sused.stlpec] == staraFarba) {
push(s, sused);
}
}
}
destroy(s);
}
Vyfarbovanie s použitím radu
Namiesto zásobníka môžeme použiť aj rad – obrazec sa potom bude vyfarbovať v poradí podľa vzdialenosti od počiatočného políčka. Pôjde o takzvané prehľadávanie do šírky, kým rekurzívna verzia a verzia so zásobníkom zodpovedajú takzvanému prehľadávaniu do hĺbky.
struct policko {
int riadok, stlpec;
};
typedef policko dataType;
/* Sem pride definicia struktury pre rad a funkcii poskytovanych radom. */
const int deltaRiadok[4] = {0, 0, 1, -1};
const int deltaStlpec[4] = {1, -1, 0, 0};
/* Prefarbi suvislu jednofarebnu oblast obsahujucu poziciu (riadok,stlpec) na farbu s cislom farba. */
void vyfarbi(int m, int n, int **a, int riadok, int stlpec, int farba, SVGdraw &drawing) {
int staraFarba = a[riadok][stlpec];
if (staraFarba == farba) {
return;
}
queue q;
init(q);
policko p;
p.riadok = riadok;
p.stlpec = stlpec;
enqueue(q, p);
while (!isEmpty(q)) {
p = dequeue(q);
if (a[p.riadok][p.stlpec] == farba) {
continue;
}
a[p.riadok][p.stlpec] = farba;
vykresliStvorcek(p.riadok, p.stlpec, farby[farba], "lightgrey", drawing);
drawing.wait(pauza);
for (int i = 0; i <= 3; i++) {
policko sused;
sused.riadok = p.riadok + deltaRiadok[i];
sused.stlpec = p.stlpec + deltaStlpec[i];
if (sused.riadok >= 0 && sused.riadok <= m - 1 && sused.stlpec >= 0 && sused.stlpec <= n - 1 &&
a[sused.riadok][sused.stlpec] == staraFarba) {
enqueue(q, sused);
}
}
}
destroy(q);
}
Program potom môžeme upraviť aj tak, aby do každého ofarbeného políčka vypísal jeho vzdialenosť od počiatočného políčka:
struct policko {
int riadok, stlpec, vzd;
};
typedef policko dataType;
/* Sem pride definicia struktury pre rad a funkcii poskytovanych radom. */
void vypisVzdialenost(int i, int j, int vzd, const char *farbaTextu, SVGdraw &drawing) {
drawing.setLineColor(farbaTextu);
drawing.setFontSize(20);
char text[15];
sprintf(text, "%d", vzd);
drawing.drawText((j + 0.5) * stvorcek, (i + 0.5) * stvorcek, text);
}
const int deltaRiadok[4] = {0, 0, 1, -1};
const int deltaStlpec[4] = {1, -1, 0, 0};
/* Prefarbi suvislu jednofarebnu oblast obsahujucu poziciu (riadok,stlpec) na farbu s cislom farba. */
void vyfarbi(int m, int n, int **a, int riadok, int stlpec, int farba, SVGdraw &drawing) {
int staraFarba = a[riadok][stlpec];
if (staraFarba == farba) {
return;
}
queue q;
init(q);
policko p;
p.riadok = riadok;
p.stlpec = stlpec;
p.vzd = 0;
enqueue(q, p);
while (!isEmpty(q)) {
p = dequeue(q);
if (a[p.riadok][p.stlpec] == farba) {
continue;
}
a[p.riadok][p.stlpec] = farba;
vykresliStvorcek(p.riadok, p.stlpec, farby[farba], "lightgrey", drawing);
vypisVzdialenost(p.riadok, p.stlpec, p.vzd, "white", drawing);
drawing.wait(pauza);
for (int i = 0; i <= 3; i++) {
policko sused;
sused.riadok = p.riadok + deltaRiadok[i];
sused.stlpec = p.stlpec + deltaStlpec[i];
sused.vzd = p.vzd + 1;
if (sused.riadok >= 0 && sused.riadok <= m - 1 && sused.stlpec >= 0 && sused.stlpec <= n - 1 &&
a[sused.riadok][sused.stlpec] == staraFarba) {
enqueue(q, sused);
}
}
}
destroy(q);
}
Prednáška 19
Oznamy
- Na budúci týždeň bude semestrálna písomka.
- Tretiu domácu úlohu treba odovzdať do 6. decembra, 22:00.
- V piatok budú doplnkové cvičenia, online.
Aritmetické výrazy
Nejaký čas sa teraz budeme venovať spracovaniu aritmetických výrazov pozostávajúcich z reálnych čísel, operácií +,-,*,/ a zátvoriek (,). Prakticky najdôležitejšou úlohou tu je vyhodnotenie daného výrazu; napríklad pre výraz
(65 – 3 * 5) / (2 + 3)
chceme vedieť povedať, že jeho hodnota je 10. K tejto úlohe sa však dostaneme až časom. Najprv zavedieme a zľahka preskúmame dva alternatívne spôsoby zápisu aritmetických výrazov, z ktorých jeden nám vyhodnocovanie výrazov značne uľahčí.
Infixová notácia
Bežný spôsob zápisu aritmetických výrazov v matematike sa zvykne nazývať aj infixovou notáciou (prípadne infixovou formou alebo infixovým zápisom). Toto pomenovanie odkazuje na skutočnosť, že binárne operátory (ako napríklad +,-,*,/) sa v tejto notácii píšu medzi svojimi dvoma operandmi. Poradie vykonávania jednotlivých operácií sa pritom riadi zátvorkami a prioritou operácií.
Napríklad
(65 – 3 * 5) / (2 + 3)
je infixový výraz s hodnotou 10.
Prefixová notácia
Pri takzvanej prefixovej notácii (často podľa jej pôvodcu Jana Łukasiewicza nazývanej aj poľskou notáciou) sa každý operátor v aritmetickom výraze zapisuje pred svojimi dvoma operandmi.
Napríklad výraz (65 – 3 * 5) / (2 + 3) má prefixový zápis
/ - 65 * 3 5 + 2 3
Postfixová notácia
Pri postfixovej notácii (často nazývanej aj obrátenou poľskou notáciou) je situácia opačná: operátor sa zapisuje bezprostredne za svojimi dvoma operandmi.
Výraz (65 – 3 * 5) / (2 + 3) má teda postfixový zápis
65 3 5 * - 2 3 + /
Postfixová a prefixová notácia sú pre človeka o niečo ťažšie čitateľné, než bežná notácia infixová (čo môže byť aj otázkou zvyku). Uvidíme však, že najmä výrazy v postfixovej notácii sa dajú pomerne jednoducho vyhodnocovať. Postfixová a prefixová notácia majú oproti infixovej notácii ešte jednu výhodu – nepotrebujú zátvorky.
Nevýhodou naopak je, že tieto notácie nie sú konštruované na používanie unárneho operátora -. Ľahko napríklad vidieť, že prefixový výraz - - 2 3 by mohol zodpovedať ako výrazu -2 - 3, tak aj výrazu -(2 - 3). V nasledujúcom teda budeme predpokladať, že výrazy neobsahujú unárne mínus. Tento nedostatok nie je nijak závažný – každý infixový podvýraz typu -cokolvek možno totiž ekvivalentne prepísať ako (0 - 1) * cokolvek. (Alternatívne by sme v prefixových a postfixových výrazoch mohli pre unárne mínus zaviesť nejaký nový symbol.)
Vyhodnocovanie aritmetických výrazov v postfixovej notácii
Na vyhodnocovanie výrazov v postfixovej forme budeme používať zásobník, do ktorého budeme postupne vkladať jednotlivé operandy. Využijeme pritom vlastnosť, že operátor má v postfixovom zápise obidva operandy pred sebou. Keď teda narazíme na operátor, jeho operandy sme už prečítali a spracovali. Ide navyše o posledné dve prečítané alebo vypočítané hodnoty.
Výraz budeme postupne čítať zľava doprava:
- Keď pritom narazíme na operand, vložíme ho na zásobník.
- Keď narazíme na operátor:
- Vyberieme zo zásobníka jeho dva operandy.
- Prvé z týchto čísel je pritom druhým operandom a druhé z nich je prvým operandom.
- Vykonáme s týmito operandmi danú operáciu a výsledok tejto operácie vložíme naspäť na zásobník.
- Tento postup opakujeme, až kým neprídeme na koniec výrazu. V tom okamihu by sme mali mať na zásobníku jediný prvok – výslednú hodnotu výrazu.
#include <cstdio>
#include <cctype>
#include <cassert>
using namespace std;
typedef double dataType;
/* Sem pride definicia struktury pre zasobnik a funkcii poskytovanych zasobnikom. */
int main(void) {
FILE *fr = stdin;
stack s;
init(s);
while (true) {
int c = getc(fr);
while (c != EOF && c != '\n' && isspace(c)) {
c = getc(fr);
}
if (c == EOF || c == '\n') {
break;
} else if (isdigit(c)) {
ungetc(c, fr);
double num;
fscanf(fr, "%lf", &num);
push(s, num);
} else {
double num2 = pop(s); // druhy operand vyberieme ako prvy ...
double num1 = pop(s); // ... a prvy operand ako druhy
switch (c) {
case '+':
push(s, num1 + num2);
break;
case '-':
push(s, num1 - num2);
break;
case '*':
push(s, num1 * num2);
break;
case '/':
push(s, num1 / num2);
break;
}
}
}
printf("%f\n", pop(s));
assert(isEmpty(s));
destroy(s);
return 0;
}
Nasledujúca alternatívna implementácia vyhodnocovania postfixových výrazov sa od predchádzajúcej líši tým, že vstupný výraz najprv uloží do reťazca, ktorý následne vyhodnotí prostredníctvom funkcie evaluatePostfix. Drobnou nevýhodou tohto prístupu je, že dĺžka vstupného reťazca je obmedzená konštantou; funkcia vyhodnocujúca výraz uložený v reťazci sa nám však neskôr zíde.
#include <cstdio>
#include <cctype>
#include <cassert>
using namespace std;
typedef double dataType;
/* Sem pride definicia struktury pre zasobnik a funkcii poskytovanych zasobnikom. */
double evaluatePostfix(char *expr) {
stack s;
init(s);
int i = 0;
while (true) {
while (expr[i] != 0 && expr[i] != '\n' && isspace(expr[i])) {
i++;
}
if (expr[i] == 0 || expr[i] == '\n') {
break;
} else if (isdigit(expr[i])) {
double num;
sscanf(&expr[i], "%lf", &num);
push(s, num);
while (isdigit(expr[i]) || expr[i] == '.') {
i++;
}
} else {
double num2 = pop(s); // druhy operand vyberieme ako prvy ...
double num1 = pop(s); // ... a prvy operand ako druhy
switch (expr[i]) {
case '+':
push(s, num1 + num2);
break;
case '-':
push(s, num1 - num2);
break;
case '*':
push(s, num1 * num2);
break;
case '/':
push(s, num1 / num2);
break;
}
i++;
}
}
double result = pop(s);
assert(isEmpty(s));
destroy(s);
return result;
}
int main(void) {
FILE *fr = stdin;
char expr[100];
fgets(expr, 100, fr);
printf("%f\n", evaluatePostfix(expr));
return 0;
}
Prevod výrazu z infixovej notácie do postfixovej
Oveľa zaujímavejšou a dôležitejšou úlohou, než vyhodnocovanie postfixových výrazov, je vyhodnocovanie výrazov v klasickej infixovej notácii. V nasledujúcom túto úlohu vyriešime tým, že napíšeme program realizujúci prevod aritmetického výrazu z infixovej notácie do postfixovej. Výraz v infixovej notácii teda budeme môcť vyhodnotiť tak, že ho najprv prevedieme do postfixovej notácie a tento postfixový výraz následne vyhodnotíme algoritmom popísaným vyššie. (Elegantnejšie prístupy k vyhodnocovaniu aritmetických výrazov vyžadujú istú dávku teórie, s ktorou sa typický študent informatiky zoznámi vo vyšších ročníkoch štúdia.)
Algoritmus pre infixové výrazy neobsahujúce unárne mínus
Začneme tým, že prevod do postfixovej notácie realizujeme pre infixové výrazy neobsahujúce unárny operátor mínus – ako sme už totiž videli, prítomnosť unárneho mínusu vo výslednom postfixovom výraze by mohla viesť k nejednoznačnostiam.
Uvažujme najprv výrazy bez zátvoriek. Tie pozostávajú z čísel a binárnych operátorov +, -, *, /, kde * a / majú vyššiu prioritu (precedenciu) ako + a -. Všetky tieto operátory sú navyše zľava asociatívne. Na prevod takéhoto jednoduchého výrazu do postfixového tvaru ním teda stačí prejsť zľava doprava a všimnúť si dve skutočnosti:
- Poradie jednotlivých čísel v postfixovom výraze je rovnaké, ako v pôvodnom infixovom výraze.
- Napríklad výraz 1 + 2 + 3 * 4 - 5 má postfixový tvar 1 2 + 3 4 * + 5 -.
- Z toho vyplýva, že pri prechádzaní vstupným infixovým výrazom možno čísla priamo vypisovať do výstupného postfixového výrazu bez toho, aby nás ďalej zaujímali.
- Každý operátor treba presunúť spomedzi jeho dvoch argumentov za jeho druhý argument.
- Ak teda vo vstupnom infixovom výraze narazíme na operátor, nevypíšeme ho hneď do výstupného výrazu, ale uložíme ho pre neskorší výpis na správnej pozícii.
- Uložený operátor potom treba vypísať za jeho druhým argumentom. Ak pritom aj samotný tento argument obsahuje nejaké ďalšie operátory, určite musia byť vypísané skôr. Operátory teda budeme ukladať na zásobníku.
- Zakaždým, keď vo vstupnom infixovom výraze narazíme na operátor, je možné, že tesne pred ním končí argument jedného alebo niekoľkých operátorov uložených na zásobníku. Vďaka ľavej asociatívnosti pritom ide o práve všetky operátory na vrchu zásobníka, ktoré majú vyššiu alebo rovnakú prioritu, ako nájdený operátor. Všetky tieto operátory teda postupne vyberieme zo zásobníka a vypíšeme ich do výstupného reťazca. Až následne na zásobník vložíme nájdený operátor.
- Podobnú činnosť treba vykonať aj na konci vstupného reťazca – v takom prípade musíme vypísať všetky operátory na zásobníku.
Z technických dôvodov budeme na spodku zásobníka uchovávať „umelé dno” #, ktoré budeme chápať ako symbol s nižšou prioritou ako všetky operátory. Situáciu, keď pri vyberaní operátorov zo zásobníka narazíme na jeho dno tak budeme môcť riešiť konzistentne so situáciou, keď narazíme na operátor s nižšou prioritou – v oboch prípadoch chceme s vyberaním prestať.
Na vstupnom výraze 1 + 2 + 3 * 4 - 5 bude práve popísaný algoritmus pracovať nasledovne:
Krok Vstupný symbol Výstupný reťazec Zásobník (dno naľavo)
------------------------------------------------------------------------------------------------------------------------
1 1 # vypíš číslo 1 na výstup
1 #
2 + 1 # # má nižšiu prioritu ako +, nevyberaj ho
+ 1 # vlož + na zásobník
1 # +
3 2 1 # + vypíš číslo 2 na výstup
1 2 # +
4 + 1 2 # + + má rovnakú prioritu ako +, vyber ho a vypíš
+ 1 2 + # # má nižšiu prioritu ako +, nevyberaj ho
+ 1 2 + # vlož + na zásobník
1 2 + # +
5 3 1 2 + # + vypíš číslo 3 na výstup
1 2 + 3 # +
6 * 1 2 + 3 # + + má nižšiu prioritu ako *, nevyberaj ho
* 1 2 + 3 # + vlož * na zásobník
1 2 + 3 # + *
7 4 1 2 + 3 # + * vypíš číslo 4 na výstup
1 2 + 3 4 # + *
8 - 1 2 + 3 4 # + * * má vyššiu prioritu ako -, vyber ho a vypíš
- 1 2 + 3 4 * # + + má rovnakú prioritu ako -, vyber ho a vypíš
- 1 2 + 3 4 * + # # má nižšiu prioritu ako -, nevyberaj ho
- 1 2 + 3 4 * + # vlož - na zásobník
1 2 + 3 4 * + # -
9 5 1 2 + 3 4 * + # - vypíš číslo 5 na výstup
1 2 + 3 4 * + 5 # -
10 [koniec vstupu] 1 2 + 3 4 * + 5 # - vyber a vypíš operátory na zásobníku
1 2 + 3 4 * + 5 - # <-- VÝSLEDNÝ POSTFIXOVÝ VÝRAZ
Do tejto schémy je už jednoduché zapracovať aj zátvorky:
- Zakaždým, keď vo vstupnom infixovom reťazci narazíme na ľavú zátvorku, vložíme ju do zásobníka. Podobne ako pri # ju budeme považovať za symbol s nižšou prioritou, než majú všetky binárne operátory (argument operátora spred tejto zátvorky totiž určite nemôže končiť v jej vnútri).
- Keď naopak narazíme na pravú zátvorku, potrebujeme vypísať všetky doposiaľ nevypísané operátory uzatvorené touto zátvorkou. Preto v takom prípade vyberieme a vypíšeme na výstup všetky operátory zo zásobníka až po prvú ľavú zátvorku (ktorú zo zásobníka taktiež vyberieme).
Funkcia infixToPostfix, realizujúca prevod z infixovej do postfixovej notácie, tak môže vyzerať napríklad nasledovne:
#include <cstdio>
#include <cassert>
#include <cctype>
using namespace std;
typedef char dataType;
/* Sem pride definicia struktury pre zasobnik a funkcii poskytovanych zasobnikom. */
int precedence(char op) {
switch (op) {
case '#':
case '(':
return 0;
break;
case '+':
case '-':
return 1;
break;
case '*':
case '/':
return 2;
break;
}
return -1; // specialne pre biele znaky vrati -1
}
/* Skonvertuje infixovy vyraz infix to postfixovej formy a vysledok ulozi do retazca postfix */
void infixToPostfix(const char *infix, char *postfix) {
stack s;
init(s);
push(s, '#');
int j = 0; // index do vystupneho retazca
for (int i = 0; infix[i] != 0; i++) {
if (isdigit(infix[i]) || infix[i] == '.') {
postfix[j++] = infix[i];
}
switch (infix[i]) {
case '(':
push(s, '(');
break;
case ')':
char c;
while ((c = pop(s)) != '(') {
postfix[j++] = ' ';
postfix[j++] = c;
}
break;
default:
int p = precedence(infix[i]);
if (p == -1) { // predovsetkym biele znaky
break;
}
postfix[j++] = ' ';
while (p <= precedence(peek(s))) {
postfix[j++] = pop(s);
postfix[j++] = ' ';
}
push(s, infix[i]);
break;
}
}
while (!isEmpty(s)) {
char c = pop(s);
if (c != '#') {
postfix[j++] = ' ';
postfix[j++] = c;
}
}
postfix[j] = 0;
destroy(s);
}
const int maxN = 100;
int main(void) {
char infix[maxN];
char postfix[2 * maxN];
fgets(infix, maxN, stdin);
infixToPostfix(infix, postfix);
printf("Postfixovy tvar vyrazu: %s\n", postfix);
return 0;
}
Cvičenie: Rozšírte program vyššie o operáciu umocňovania ^ s prioritou vyššou ako * (dajte si pritom pozor na fakt, že umocňovanie je narozdiel od operácií +, -, *, / sprava asociatívne).
Rozšírenie na infixové výrazy obsahujúce unárne mínus
Pri prevode infixového výrazu do postfixového tvaru sme predpokladali, že neobsahuje žiadny výskyt unárneho operátora -. V nasledujúcom tento nedostatok napravíme: napíšeme funkciu normalise, ktorá v danom infixovom výraze in nahradí všetky výskyty unárneho mínusu reťazcom (0-1)* a výsledok uloží do (opäť infixového) výrazu out. Mínus je pritom v korektnom infixovom výraze unárny práve vtedy, keď (modulo biele znaky, ktoré budeme ignorovať) nenasleduje za číslom, ani za pravou zátvorkou.
void normalise(const char *in, char *out) {
int j = 0; // index do vystupneho retazca
bool hasOperand = false;
for (int i = 0; in[i] != 0; i++) {
if (in[i] == '-' && !hasOperand) {
out[j++] = '(';
out[j++] = '0';
out[j++] = '-';
out[j++] = '1';
out[j++] = ')';
out[j++] = '*';
} else if (isdigit(in[i]) || in[i] == '.' || in[i] == ')') {
out[j++] = in[i];
hasOperand = true;
} else if (isspace(in[i])) {
out[j++] = in[i];
} else {
out[j++] = in[i];
hasOperand = false;
}
}
out[j] = 0;
}
Prevod infixového výrazu s unárnymi mínusmi do postfixového tvaru teda môžeme realizovať tak, že najprv zavoláme funkciu normalise a následne funkciu infixToPostfix. (O niečo krajším riešením by bolo nahradenie unárnych mínusov nejakým novým špeciálnym znakom – v takom prípade by sa však musela zmeniť aj funkcia infixToPostfix.) Následne môžeme výsledný výraz aj vyhodnotiť pomocou funkcie evaluatePostfix.
const int maxN = 100;
int main(void) {
char infix1[maxN];
char infix2[6 * maxN];
char postfix[12 * maxN];
fgets(infix1, maxN, stdin);
normalise(infix1, infix2);
printf("Vyraz po odstraneni unarnych minusov: %s\n", infix2);
infixToPostfix(infix2, postfix);
printf("Vyraz v postfixovom tvare: %s\n", postfix);
printf("Hodnota vyrazu: %f\n", evaluatePostfix(postfix));
return 0;
}
Pri implementácii uvedeného programu sa však treba mať na pozore: kým totiž funkcia evaluatePostfix využíva zásobník prvkov typu double, funkcia infixToPostfix využíva zásobník prvkov typu char. Pri pokuse o skopírovanie kódu pre zásobník do zdrojového súboru tohto programu tak stojíme pred voľbou medzi
typedef char dataType;
a
typedef double dataType;
V tomto prípade ešte môžeme zvoliť druhú možnosť a za dataType považovať double; o zvyšok sa postará automatické pretypovanie znakov (čiže špeciálnych celých čísel) na reálne čísla a naopak. Toto riešenie má však ďaleko od ideálneho a pre iné dvojice typov nemusí riešenie tohto druhu existovať vôbec. (Ozaj elegantný prístup k tomuto problému vyžaduje pokročilejšie programátorské techniky z letného semestra.)
Prednáška 20
Oznamy
- Tretiu domácu úlohu treba odovzdať do dnes, 6. decembra, 22:00.
- Semestrálny test bude v piatok 10.12. 11:30 počas doplnkových cvičení na MS Teams.
- Viac informácií k testu na zvláštnej stránke.
- Dnes po prednáške sa už objavia príklady na ďalšie cvičenia, aby ste mohli v prípade záujmu trénovať nové učivo pred testom.
- V stredu budú na začiatku prednášky informácie k skúške a rady k skúškovému obdobiu všeobecne.
Aritmetické stromy

Aritmetické výrazy možno reprezentovať aj vo forme stromu nazývaného aj aritmetickým stromom:
- Operátory a čísla tvoria tzv. uzly stromu.
- Operátory tvoria tzv. vnútorné uzly stromu – každý z nich má dvoch synov zodpovedajúcich podvýrazom pre jednotlivé operandy.
- Čísla tvoria tzv. listy aritmetického stromu – tie už nemajú žiadnych synov.
- Strom obsahuje jediný uzol, ktorý nie je synom žiadneho iného uzla – to je tzv. koreň stromu a reprezentuje celý aritmetický výraz.
- Informatici stromy väčšinou kreslia „hore nohami”, s koreňom na vrchu.
Uzol aritmetického stromu tak môžeme reprezentovať napríklad nasledujúcou štruktúrou:
struct treeNode {
double val; // ciselna hodnota (zmysluplna len v listoch)
char op; // operator (zmysluplny len vo vnutornych uzloch, pre listy vzdy rovny medzere)
treeNode *left; // smernik na koren podstromu reprezentujuceho lavy podvyraz
treeNode *right; // smernik na koren podstromu reprezentujuceho pravy podvyraz
};
Pre vnútorné uzly stromu (zodpovedajúce operátorom) pritom:
- Smerníky left a right budú ukazovať na korene podstromov reprezentujúcich ľavý resp. pravý podvýraz.
- Znak op bude zodpovedať danému operátoru (napríklad '+').
- Hodnota val ostane nevyužitá.
Pre listy (zodpovedajúce číselným hodnotám) naopak:
- Smerníky left a right budú mať hodnotu NULL.
- Znak op bude medzera ' ' (podľa op teda môžeme rozlišovať, či ide o číslo alebo o operátor).
- Vo val bude uložená hodnota daného čísla.
Celý strom pritom budeme reprezentovať jeho koreňom.
Ide tu o jednoduchú, no nie veľmi elegantnú reprezentáciu aritmetických stromov, keďže viaceré položky štruktúry treeNode môžu byť nevyužité. S využitím objektového programovania (letný semester) možno aritmetické stromy reprezentovať omnoho krajšie.
Vytvorenie uzlu aritmetického stromu
Nasledujúce funkcie vytvoria nový vnútorný uzol (pre operátor) resp. nový list (pre číslo):
treeNode *createOp(char op, treeNode *left, treeNode *right) {
treeNode *v = new treeNode;
v->left = left;
v->right = right;
v->op = op;
return v;
}
treeNode *createNum(double val) {
treeNode *v = new treeNode;
v->left = NULL;
v->right = NULL;
v->op = ' ';
v->val = val;
return v;
}
„Ručne” teraz môžeme vytvoriť strom pre výraz (65 – 3 * 5)/(2 + 3):
treeNode *root = createOp('/',
createOp('-',
createNum(65),
createOp('*', createNum(3), createNum(5))),
createOp('+', createNum(2), createNum(3)));
Alebo po častiach:
treeNode *v65 = createNum(65);
treeNode *v3 = createNum(3);
treeNode *v5 = createNum(5);
treeNode *v2 = createNum(2);
treeNode *v3b = createNum(3);
treeNode *vKrat = createOp('*', v3, v5);
treeNode *vMinus = createOp('-', v65, vKrat);
treeNode *vPlus = createOp('+', v2, v3b);
treeNode *vDeleno = createOp('/', vMinus, vPlus);
Uvoľnenie pamäte
Nasledujúca funkcia uvoľní z pamäte celý strom s koreňom root:
void destroyTree(treeNode *root) {
if (root != NULL) {
destroyTree(root->left);
destroyTree(root->right);
delete root;
}
}
Vyhodnotenie výrazu reprezentovaného stromom
Nasledujúca rekurzívna funkcia vypočíta hodnotu aritmetického výrazu reprezentovaného stromom s koreňom root:
double evaluateTree(treeNode *root) {
assert(root != NULL);
if (root->op == ' ') {
return root->val;
} else {
double valLeft = evaluateTree(root->left);
double valRight = evaluateTree(root->right);
switch (root->op) {
case '+':
return valLeft + valRight;
break;
case '-':
return valLeft - valRight;
break;
case '*':
return valLeft * valRight;
break;
case '/':
return valLeft / valRight;
break;
default:
assert(false);
break;
}
}
return 0; // realne nedosiahnutelny prikaz
}
Vypísanie výrazu reprezentovaného stromom v rôznych notáciách
Infixovú, prefixovú, resp. postfixovú reprezentáciu aritmetického výrazu reprezentovaného stromom s koreňom root možno získať pomocou nasledujúcich funkcií:
void printInorder(FILE *fw, treeNode *root) {
if (root->op == ' ') {
fprintf(fw, "%.2f", root->val);
} else {
fprintf(fw, "(");
printInorder(fw, root->left);
fprintf(fw, " %c ", root->op);
printInorder(fw, root->right);
fprintf(fw, ")");
}
}
void printPreorder(FILE *fw, treeNode *root) {
if (root->op == ' ') {
fprintf(fw, "%.2f ", root->val);
} else {
fprintf(fw, "%c ", root->op);
printPreorder(fw, root->left);
printPreorder(fw, root->right);
}
}
void printPostorder(FILE *fw, treeNode *root) {
if (root->op == ' ') {
fprintf(fw, "%.2f ", root->val);
} else {
printPostorder(fw, root->left);
printPostorder(fw, root->right);
fprintf(fw, "%c ", root->op);
}
}
Vytvorenie stromu z postfixového výrazu
Pripomeňme si z minulej prednášky funkciu na vyhodnocovanie postfixového výrazu:
typedef double dataType;
/* Sem pride definicia struktury pre zasobnik a vsetkych funkcii poskytovanych zasobnikom. */
double evaluatePostfix(char *expr) {
stack s;
init(s);
int i = 0;
while (true) {
while (expr[i] != 0 && expr[i] != '\n' && isspace(expr[i])) {
i++;
}
if (expr[i] == 0 || expr[i] == '\n') {
break;
} else if (isdigit(expr[i])) {
double num;
sscanf(&expr[i], "%lf", &num);
push(s, num);
while (isdigit(expr[i]) || expr[i] == '.') {
i++;
}
} else {
double num2 = pop(s);
double num1 = pop(s);
switch (expr[i]) {
case '+':
push(s, num1 + num2);
break;
case '-':
push(s, num1 - num2);
break;
case '*':
push(s, num1 * num2);
break;
case '/':
push(s, num1 / num2);
break;
}
i++;
}
}
double result = pop(s);
assert(isEmpty(s));
destroy(s);
return result;
}
Túto funkciu možno jednoducho prepísať tak, aby namiesto vyhodnocovania výrazu konštruovala zodpovedajúci aritmetický strom. Namiesto hodnôt jednotlivých podvýrazov stačí na zásobníku uchovávať korene stromov, ktoré tieto podvýrazy reprezentujú. Aplikácii aritmetickej operácie potom bude zodpovedať „spojenie” dvoch podstromov do jedného stromu:
typedef treeNode *dataType;
/* Sem pride definicia struktury pre zasobnik a vsetkych funkcii poskytovanych zasobnikom. */
treeNode *parsePostfix(char *expr) {
stack s;
init(s);
int i = 0;
while (true) {
while (expr[i] != 0 && expr[i] != '\n' && isspace(expr[i])) {
i++;
}
if (expr[i] == 0 || expr[i] == '\n') {
break;
} else if (isdigit(expr[i])) {
double num;
sscanf(&expr[i], "%lf", &num);
push(s, createNum(num));
while (isdigit(expr[i]) || expr[i] == '.') {
i++;
}
} else {
treeNode *right = pop(s);
treeNode *left = pop(s);
push(s, createOp(expr[i], left, right));
i++;
}
}
treeNode *result = pop(s);
assert(isEmpty(s));
destroy(s);
return result;
}
Ukážkový program pracujúci s aritmetickými stromami
Nasledujúci program prečíta z konzoly aritmetický výraz v postfixovom tvare, skonštruuje jeho aritmetický strom a následne preň zavolá funkcie na výpočet hodnoty výrazu a jeho výpis v rôznych notáciách:
int main(void) {
char expr[100];
fgets(expr, 100, stdin);
treeNode *root = parsePostfix(expr);
printf("Hodnota vyrazu je: %.2f\n", evaluateTree(root));
printf("Vyraz v infixovej notacii: ");
printInorder(stdout, root);
printf("\n");
printf("Vyraz v prefixovej notacii: ");
printPreorder(stdout, root);
printf("\n");
printf("Vyraz v postfixovej notacii: ");
printPostorder(stdout, root);
printf("\n");
destroyTree(root);
return 0;
}
Binárne stromy
Aritmetické stromy sú špeciálnym prípadom binárnych stromov. V informatike nachádzajú binárne stromy množstvo rozličných uplatnení – zameriame sa preto na všeobecnú dátovú štruktúru binárneho stromu. V tomto všeobecnejšom kontexte sa pritom znova objavia niektoré techniky, ktoré sme používali v špeciálnom prípade aritmetických stromov.
Terminológia stromov
Pod stromom budeme rozumieť množinu vrcholov pospájaných hranami tak, aby každá dvojica vrcholov bola spojená práve jednou postupnosťou hrán (vrcholy teda nemôžu byť pospájané cyklicky). Navyše nás na tomto predmete budú zaujímať iba zakorenené stromy, ktoré obsahujú práve jeden špeciálny vrchol nazývaný koreňom. Vždy, keď budeme hovoriť o stromoch, budeme mať na mysli zakorenené stromy. V súvislosti s nimi budeme o vrcholoch väčšinou hovoriť ako o uzloch.
Poznámka. Takáto definícia stromov nie je úplne matematicky presná (ide o „popularizáciu” ozajstnej definície). Poriadne definície pojmov súvisiacich so stromami patria do náplne predmetu Úvod do kombinatoriky a teórie grafov (letný semester).
Každý uzol u zakoreneného stromu okrem koreňa je spojený hranou s práve jedným otcom (alebo rodičom; angl. parent), ktorým je nejaký uzol v (ide o jediný vrchol stromu spojený hranou s uzlom u, ktorý je bližšie ku koreňu, než uzol u). Naopak potom hovoríme, že uzol u je synom (alebo dieťaťom; angl. child resp. son) uzla v. Vo všeobecnom zakorenenom strome pritom môže mať každý uzol ľubovoľný prirodzený (a teda aj nulový) počet synov. Na tomto predmete budeme navyše predpokladať, že pre každý vrchol je dané nejaké úplné usporiadanie jeho synov (možno teda rozlišovať medzi „najľavejším” synom, synom druhým zľava, atď.). Strom je binárny, ak má každý uzol najviac dvoch synov. Budeme pritom rozlišovať medzi pravým a ľavým synom – každý uzol má najviac jedného ľavého a najviac jedného pravého syna.
Na tomto predmete budeme odteraz pod stromom vždy rozumieť zakorenený binárny strom s rozlišovaním medzi pravými a ľavými synmi.
Predkom uzla u nazveme ľubovoľný uzol v rôzny od u ležiaci na nejakej ceste z u do koreňa stromu. Naopak potom hovoríme, že u je potomkom uzla v. Uzly zakoreneného stromu, ktoré nemajú žiadneho syna, nazývame listami; zvyšné uzly potom nazývame vnútornými uzlami.
Podstromom stromu T zakoreneným v nejakom uzle v stromu T budeme rozumieť strom s koreňom v pozostávajúci z uzla v, všetkých jeho potomkov a všetkých hrán stromu T vedúcich medzi týmito uzlami.
Každý binárny strom je teda buď prázdny, alebo je tvorený jeho koreňom a dvoma podstromami – ľavým a pravým.
Štruktúra pre uzol binárneho stromu
V nasledujúcom budeme pracovať výhradne s binárnymi stromami. Štruktúra pre uzol všeobecného binárneho stromu je podobná, ako pri aritmetických stromoch – namiesto operátora alebo hodnoty si však v každom uzle môžeme pamätať hodnotu ľubovoľného typu dataType.
Keďže neskôr budeme binárne stromy vypisovať, budeme predpokladať, že pre hodnoty typu dataType máme k dispozícii funkciu printDataType, ktorá ich v nejakom vhodnom formáte vypisuje. Nasledujúci kus kódu zodpovedá situácii, keď dataType je int.
#include <cstdio>
using namespace std;
// ...
/* Typ prvkov ukladanych v uzloch binarneho stromu -- moze byt prakticky lubovolny */
typedef int dataType;
/* Funkcia pre vypis hodnoty typu dataType */
void printDataType(dataType d) {
printf("%d ", d); // pre int
}
// ...
/* Uzol binarneho stromu */
struct node {
dataType data; // hodnota ulozena v danom uzle
node *left; // smernik na laveho syna (NULL, ak tento syn neexistuje)
node *right; // smernik na praveho syna (NULL, ak tento syn neexistuje)
};
Vytvorenie binárneho stromu
Nasledujúca funkcia vytvorí uzol binárneho stromu s dátami data, ľavým podstromom zakoreneným v uzle *left a pravým podstromom zakoreneným v uzle *right (parametre left a right sú teda smerníkmi na uzly). Ako výstup funkcia vráti smerník na novovytvorený uzol.
/* Vytvori uzol binarneho stromu */
node *createNode(dataType data, node *left, node *right) {
node *v = new node;
v->data = data;
v->left = left;
v->right = right;
return v;
}
Nasledujúca volanie tak napríklad vytvorí binárny strom so šiestimi uzlami zakorenený v uzle *root.
node *root = createNode(1,
createNode(2,
createNode(3, NULL, NULL),
createNode(4,NULL,NULL)),
createNode(5,
NULL,
createNode(6, NULL, NULL)));
Cvičenie: nakreslite binárny strom vytvorený predchádzajúcim volaním.
Likvidácia binárneho stromu
Nasledujúca rekurzívna funkcia zlikviduje celý podstrom zakorenený v uzle *root (t. j. pouvoľňuje pamäť pre všetky jeho uzly).
/* Zlikviduje podstrom s korenom *root (pouvolnuje pamat) */
void destroyTree(node *root) {
if (root != NULL) {
destroyTree(root->left);
destroyTree(root->right);
delete root;
}
}
Výška binárneho stromu
Hĺbkou uzla binárneho stromu nazveme jeho vzdialenosť od koreňa. Koreň má teda hĺbku 0, jeho synovia majú hĺbku 1, atď. Výškou binárneho stromu (niekedy nazývanou aj jeho hĺbkou) potom nazveme maximálnu hĺbku niektorého z jeho vrcholov. Strom s jediným vrcholom má teda hĺbku 0; pre ostatné stromy je ich výška daná ako 1 plus maximum z výšok ľavého a pravého podstromu.
Nasledujúca funkcia počíta výšku stromu (kvôli elegancii zápisu pritom pracuje s rozšírením definície výšky stromu na prázdne stromy, za ktorých výšku sa považuje číslo -1).
/* Spocita vysku podstromu s korenom *root. Pre root == NULL vrati -1. */
int height(node *root) {
if (root == NULL) {
return -1;
}
int hLeft = height(root->left); // rekurzivne spocita vysku laveho podstromu
int hRight = height(root->right); // rekurzivne spocita vysku praveho podstromu
if (hLeft >= hRight) { // vrati max(hLeft, hRight) + 1
return hLeft + 1;
} else {
return hRight + 1;
}
}
Pre výšku h stromu s n uzlami pritom platia nasledujúce vzťahy:
- Určite h ≤ n-1. Tento prípad nastáva, ak sú všetky uzly „navešané jeden pod druhý”.
- Strom s výškou h má najviac
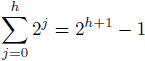
- uzlov (ako možno ľahko dokázať indukciou vzhľadom na h).

- Z toho h ≥ log2(n+1)-1.
- Dostávame teda log2(n+1)-1 ≤ h ≤ n-1.
- Napríklad strom s milión vrcholmi má teda hĺbku medzi 19 a 999999.
Prehľadávanie stromov a vypisovanie ich uzlov
Často je potrebné prejsť celý strom a spracovať (napríklad vypísať) hodnoty vo všetkých uzloch. Toto prehľadávanie možno, podobne ako pri aritmetických stromoch, realizovať v troch základných poradiach: preorder, inorder a postorder.
/* Vypise podstrom s korenom *root v poradi preorder */
void printPreorder(node *root) {
if (root == NULL) {
return;
}
printDataType(root->data);
printPreorder(root->left);
printPreorder(root->right);
}
/* Vypise podstrom s korenom *root v poradi inorder */
void printInorder(node *root) {
if (root == NULL) {
return;
}
printInorder(root->left);
printDataType(root->data);
printInorder(root->right);
}
/* Vypise podstrom s korenom *root v poradi postorder */
void printPostorder(node *root) {
if (root == NULL) {
return;
}
printPostorder(root->left);
printPostorder(root->right);
printDataType(root->data);
}
Príklad: plné binárne stromy
Binárny strom výšky h s maximálnym počtom vrcholov 2h+1-1 sa nazýva plný binárny strom. Nasledujúca funkcia createFullTree vytvorí takýto strom a vráti smerník na jeho koreň. Jeho uzlom pritom priradí po dvoch rôzne hodnoty typu int (predpokladáme teda, že dataType je int) podľa globálnej premennej count.
// ...
int count;
/* Vytvori plny binarny strom vysky height s datami uzlov count, count + 1, ... */
node *createFullTree(int height) {
if (height == -1) {
return NULL;
}
node *v = createNode(count++, NULL, NULL);
v->left = createFullTree(height - 1);
v->right = createFullTree(height - 1);
return v;
}
int main(void) {
count = 1;
node *root = createFullTree(3);
printf("Vyska: %d\n", height(root));
printf("Inorder: ");
printInorder(root);
printf("\n");
printf("Preorder: ");
printPreorder(root);
printf("\n");
printf("Postorder: ");
printPostorder(root);
printf("\n");
destroyTree(root);
return 0;
}
Cvičenie: opíšte poradie, v ktorom sa v uvedenom programe jednotlivým uzlom priraďujú ich hodnoty.
Prednáška 21
Oznamy
Plán prednášok a cvičení na zvyšok semestra:
- Dnes informácia o skúškach, detaily skúšky z programovania, pokračujeme v učive o stromoch
- Tento piatok 10.12. cez cvičenia semestrálny test.
- V pondelok 13.12. bude bežná prednáška, pokračujú stromy.
- V stredu 15.12. dokončíme stromy, potom nepovinná prednáška o nepreberaných črtách jazykov C a C++ (táto nepovinná časť učiva nebude vyžadovaná na skúške, ale môžete ju použiť).
- V utorok 14.12. v rámci cvičení tréning na skúšku.
- Už dnes po prednáške sa na testovači objavia tréningové príklady na skúšku. Za niektoré budete môcť získať bonusový bod, ak ich vyriešite do 12.1. (ako tréning sa dajú riešiť aj neskôr). V utorok na cvičeniach pribudne ešte jeden tréningový príklad za 4 body. Ak prídete na cvičenia a odovzdáte na konci aspoň rozumne rozrobenú verziu programu, získate jeden bonusový bod, aj keď ho nestihnete dokončiť.
- V piatok 17.12. od 12:00 predtermín skúšky, doplnkové cvičenia nebudú
Binárne vyhľadávacie stromy

Stromy sa v informatike často používajú. Ďalším príkladom sú binárne vyhľadávacie stromy, ktoré slúžia na ukladanie množiny prvkov. Prvky množiny teda nemáme v poli, ani v spájanom zozname, ale vo vrcholoch binárneho stromu.
- V binárnom vyhľadávacom strome má každý vrchol 0,1 alebo 2 deti
- V každom vrchole máme položku s dátami (pre jednoduchosť typu int)
- Pre každý vrchol v stromu platí:
- Každý vrchol v ľavom podstrome v má hodnotu data menšiu ako vrchol v
- Každý vrchol v pravom podstrome v má hodnotu data väčšiu ako vrchol v
- Z toho vyplýva, že ak vypíšeme strom v inorder poradí, dostaneme prvky usporiadané
- Pre danú množinu kľúčov existuje veľa vyhľadávacích stromov
Cvičenie: nájdite všetky binárne vyhľadávacie stromy pozostávajúce z troch uzlov s kľúčmi 1, 2, 3.
Definícia dátových štruktúr
Vrchol typu node
- Položka data typu int
- Smerník na ľavé a pravé dieťa
- Na niektoré úlohy (napr. mazanie vrcholu) sa hodí aj smerník na rodiča (ten má hodnotu NULL v koreni)
Celý strom je štruktúra obsahujúca iba smerník na koreň
- Pre prázdny strom je to NULL.
struct node {
/* vrchol binárneho vyhľadávacieho stromu */
int data; /* hodnota */
node * parent; /* rodič vrchola, NULL v koreni */
node * left; /* ľavé dieťa, NULL ak neexistuje */
node * right; /* pravé dieťa, NULL ak neexistuje */
};
/* Samotná štruktúra binárneho vyhľadávacieho stromu (obal pre používateľa). */
struct binarySearchTree {
node *root; /* koreň stromu, NULL pre prázdny strom */
};
Inicializácia prázdneho binárneho vyhľadávacieho stromu
/** Funkcia inicializuje prázdny binárny vyhľadávací strom */
void bstInit(binarySearchTree &t) {
t.root = NULL;
}
Likvidácia binárneho vyhľadávacieho stromu
Likvidáciu podstromu zakoreneného v danom uzle root realizujeme funkciou destroy, obdobne ako pri všeobecných binárnych stromoch. Používateľovi navyše dáme k dispozícii aj funkciu bstDestroy, ktorá zlikviduje binárny vyhľadávací strom t tak, že zavolá funkciu destroy na jeho koreň.
/* Uvolni pamat pre podstrom s korenom *root. */
void destroy(node *root) {
if (root != NULL) {
destroy(root->left);
destroy(root->right);
delete root;
}
}
/* Zlikviduje strom t (uvolni pamat). */
void bstDestroy(binarySearchTree &t) {
destroy(t.root);
}
Hľadanie v binárnom vyhľadávacom strome
Funkcia findNode v podstrome s koreňom root hľadá uzol, ktorého položka dáta obsahuje hľadaný kľúč key. Vráti takýto uzol alebo NULL ak neexistuje
- Najskôr porovná hľadaný kľúč s dátami v koreni
- Ak sa rovnajú, končíme (našli sme, čo hľadáme)
- Ak je hľadaná hodnota menšia ako dáta v koreni, musí byť v ľavom podstrome, ak je väčšia v pravom
- V príslušnom podstrome sa rozhodujeme podľa tých istých pravidiel
- Keď narazíme na prázdny podstrom, dáta sa v strome nenachádzajú
- Dá sa zapísať rekurzívne alebo cyklom, lebo vždy ideme iba do jedného podstromu
Funkcia bstFind zavolá funkciu findNode pre koreň daného binárneho vyhľadávacieho stromu t a pomocou nej zistí, či tento strom obsahuje uzol s kľúčom key.
/* Ak v strome s korenom root existuje uzol s klucom key,
* vrati ho na vystupe. Inak vrati NULL. */
node * findNode(node *root, int key) {
node * v = root;
while (v != NULL && v->data != key) {
if (key < v->data) {
v = v->left;
} else {
v = v->right;
}
}
return v;
}
/** Rekurzívna verzia */
node *findNodeR(node *root, int key) {
if (root == NULL || key == root->data) {
return root;
} else if (key < root->data) {
return findNodeR(root->left, key);
} else { // key > root->data
return findNodeR(root->right, key);
}
}
/* Zisti, ci strom t obsahuje uzol s klucom key. */
bool bstFind(binarySearchTree &t, int key) {
return findNode(t.root, key) != NULL;
}
Čas výpočtu je v najhoršom prípade úmerný výške stromu.
Prednáška 22
Oznamy
Plán prednášok a cvičení na zvyšok semestra:
- Dnes pokračujeme stromy.
- V utorok 14.12. v rámci cvičení tréning na skúšku.
- Na testovači už sú tréningové príklady na skúšku. Za niektoré budete môcť získať bonusový bod, ak ich vyriešite do 12.1. (ako tréning sa dajú riešiť aj neskôr). V utorok na cvičeniach pribudne ešte jeden tréningový príklad za 4 body. Ak prídete na cvičenia a odovzdáte na konci aspoň rozumne rozrobenú verziu programu, získate jeden bonusový bod, aj keď ho nestihnete dokončiť.
- V stredu 15.12. ak treba dokončíme stromy, potom nepovinná prednáška o nepreberaných črtách jazykov C a C++ (táto nepovinná časť učiva nebude vyžadovaná na skúške, ale môžete ju použiť).
- V piatok 17.12. od 12:00 predtermín skúšky, doplnkové cvičenia nebudú
Nezabudnite hlásiť čím skôr prípadné konflikty termínov skúšky s inými predmetmi.
Binárne vyhľadávacie stromy
Opakovanie
Binárny vyhľadávací strom (binary search tree) je dátová štruktúra určená na ukladanie dynamickej množiny prvkov.
- V binárnom vyhľadávacom strome má každý vrchol 0, 1 alebo 2 deti
- V každom vrchole máme položku s dátami (pre jednoduchosť typu int)
- Pre každý vrchol v stromu platí:
- Každý vrchol v ľavom podstrome v má hodnotu data menšiu ako vrchol v
- Každý vrchol v pravom podstrome v má hodnotu data väčšiu ako vrchol v
struct node {
/* vrchol binárneho vyhľadávacieho stromu */
int data; /* hodnota */
node * parent; /* rodič vrchola, NULL v koreni */
node * left; /* ľavé dieťa, NULL ak neexistuje */
node * right; /* pravé dieťa, NULL ak neexistuje */
};
/* Samotná štruktúra binárneho vyhľadávacieho stromu (obal pre používateľa). */
struct binarySearchTree {
node *root; /* koreň stromu, NULL pre prázdny strom */
};
Videli sme vyhľadávanie prvku v binárnom vyhľadávacom strome. Čas výpočtu je v najhoršom prípade úmerný výške stromu.
Vkladanie do binárneho vyhľadávacieho stromu
Nasledujúca funkcia insertNode vloží uzol *v na správne miesto podstromu zakoreneného v *root ako jeho list.
- Predpokladáme, že prvok v strome nie je.
- Putujeme po strome podobne ako pri vyhľadávaní prvku, až kým nenarazíme na nulový smerník.
- Na tomto mieste by mal byť nový prvok, takže ho tam pridáme ako nový list
- Uvádzame rekurzívnu verziu, dá sa aj cyklom, podobne ako pri hľadaní
- Funkcia bstInsert vytvorí uzol s daným kľúčom key a pomocou funkcie insertNode ho vloží do binárneho vyhľadávacieho stromu t.
/* Vloží uzol v na správne miesto podstromu zakoreneného v root */
void insertNode(node *root, node *v) {
assert(root != NULL && v != NULL);
if (v->data < root->data) {
if (root->left == NULL) {
root->left = v;
v->parent = root;
} else {
insertNode(root->left, v);
}
} else {
if (root->right == NULL) {
root->right = v;
v->parent = root;
} else {
insertNode(root->right, v);
}
}
}
/* Vloží do stromu t nový uzol s kľúčom key. */
void bstInsert(binarySearchTree &t, int key) {
node *v = new node;
v->data = key;
v->left = NULL;
v->right = NULL;
v->parent = NULL;
if (t.root == NULL) {
t.root = v;
} else {
insertNode(t.root, v);
}
}
Čas vkladania je tiež v najhoršom prípade úmerný hĺbke stromu.
Cvičenia
- Napíšte nerekurzívny variant funkcie insertNode.
- Napíšte funkciu treeSort, ktorá z poľa celých čísel a pomocou volaní funkcie bstInsert vytvorí binárny vyhľadávací strom a následne pomocou prehľadávania tohto stromu v poradí inorder pole a utriedi.
- Ako bude vyzerať strom po nasledujúcej postupnosti operácií?
binarySearchTree t;
bstInit(t);
bstInsert(t, 2);
bstInsert(t, 5);
bstInsert(t, 3);
bstInsert(t, 10);
bstInsert(t, 7);
Minimum a následník
Uvedieme teraz dve funkcie, ktoré sa zídu pri mazaní prvku zo stromu, ale môžu sa zísť aj inokedy.
Prvá funkcia minNode nájde vo vyhľadávacom strome uzol, v ktorom je uložená najmenšia hodnota.
- Všetky prvky menšie ako koreň sú v ľavom podstrome, bude tam zrejme aj minimum.
- Tá istá úvaha platí pre koreň ľavého podstromu.
- Ideme teda doľava kým sa dá, posledný vrchol vrátime (list alebo vrchol, ktorý má iba pravé dieťa).
- Nie je treba teda prechádzať celý strom a nemusíme sa ani pozerať na položku data v uzloch.
- Dá sa napísať cyklom aj rekurzívne.
- Obalom pre používateľa bude funkcia bstMin, ktorá pomocou funkcie minNode nájde minimálny kľúč v danom binárnom vyhľadávacom strome t.
/* Vrati uzol s minimalnou hodnotou data v podstrome s korenom v. */
node *minNode(node *v) {
assert(v != NULL);
while (v->left != NULL) {
v = v->left;
}
return v;
}
/* Vrati minimalny kluc uzla v strome t. */
int bstMin(binarySearchTree &t) {
assert(t.root != NULL);
return minNode(t.root)->data;
}
Cvičenia:
- Napíšte rekurzívny variant funkcie minNode.
- Ako by bolo treba funkciu zmeniť, aby hľadala maximum?
Funkcia successorNode nájde pre daný uzol v jeho následníka (angl. successor) v binárnom vyhľadávacom strome, čiže uzol, ktorý vo vzostupnom poradí podľa kľúčov nasleduje bezprostredne za uzlom v.
- Ak má uzol v pravé dieťa, následník uzla v bude vrchol s minimálnou hodnotou data v pravom podstrome
- V opačnom prípade môže byť následníkom uzla v jeho rodič, ak v je jeho ľavé dieťa.
- Ak je v pravým dieťaťom svojho rodiča, môže to byť jeho prarodič (ak je rodič uzla v ľavým dieťaťom tohto prarodiča), atď.
- Vo všeobecnosti teda ide o najbližšieho predka uzla v takého, že v patrí do jeho ľavého podstromu.
- V strome existuje práve jeden uzol bez následníka (najväčší prvok).
- Ako presne sa bude funkcia nižšie pre tento prvok správať?
/* Vrati uzol, ktory vo vzostupnom poradi uzlov podla klucov nasleduje za v.
* Ak taky uzol neexistuje, vrati NULL. */
node *successorNode(node *v) {
assert(v != NULL);
if (v->right != NULL) {
return minNode(v->right);
}
while (v->parent != NULL && v == v->parent->right) {
v = v->parent;
}
return v->parent;
}
Mazanie z binárneho vyhľadávacieho stromu
Nasledujúca funkcia bstRemove zmaže z binárneho vyhľadávacieho stromu t uzol s kľúčom key (ak sa taký uzol v strome vyskytuje).
- Najprv pomocou funkcie findNode nájde uzol v s kľúčom key.
- Ak je v list, jednoducho ho zmažeme.
- Ak má v jedno dieťa, toto dieťa prevesíme priamo pod rodiča v a v zmažeme.
- Ak má v dve deti, nájdeme nasledovníka v, t.j. minimum v pravom podstrome v.
- Tento nasledovník nemá ľavé dieťa, vieme ho teda zmazať.
- Jeho údaje presunieme do vrcholu v.
- Tiež treba dať pozor na mazanie koreňa.
/* Zmaze zo stromu t uzol s klucom key, ak tam taky je. */
void bstRemove(binarySearchTree &t, int key) {
// Najde uzol v s hodnotou, ktoru treba vymazat.
node *v = findNode(t.root, key);
if (v == NULL) {
return;
}
// Najde uzol *rm stromu t, ktory sa napokon realne zmaze.
node *rm;
if (v->left == NULL || v->right == NULL) {
rm = v;
} else {
rm = successorNode(v);
}
// Ak rm != v, presunie kluc uzla *rm do uzla *v.
if (rm != v) {
v->data = rm->data;
}
// ak ma uzol rm dieta, jeho rodicom bude rodic rm
node *child;
if (rm->left != NULL) {
child = rm->left;
} else {
child = rm->right;
}
if (child != NULL) {
child->parent = rm->parent;
}
if (rm->parent == NULL) {
t.root = child;
} else if (rm == rm->parent->left) {
rm->parent->left = child;
} else if (rm == rm->parent->right) {
rm->parent->right = child;
}
// rm uz nie je v strome, uvolnime jeho pamat
delete rm;
}
Zložitosť jednotlivých operácií
- Časová zložitosť operácií bstFind(t), bstInsert(t) aj bstRemove(t) je úmerná výške stromu t, ktorú označíme h.
- Predminule sme ukázali, že pre strom s n uzlami máme log2(n+1)-1 ≤ h ≤ n-1.
- Zložitosť uvedených operácií je teda v najhoršom prípade lineárna od počtu uzlov stromu (tento prípad nastane, ak prvky vkladáme od najmenšieho po najväčší alebo naopak).
- Dá sa však ukázať, že ak sa prvky vkladajú v náhodnom poradí, výška stromu bude v priemere logaritmická od počtu uzlov.
- Na predmete Algoritmy a dátové štruktúry (druhý ročník) sa tieto tvrdenia dokazujú poriadne a preberajú sa tam aj varianty vyhľadávacích stromov, pre ktoré je zložitosť uvedených operácií logaritmická aj v najhoršom prípade.
Lexikografické stromy

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Lexikografické stromy (niekde tiež prefixové stromy; angl. trie zo slova retrieval) sú dátová štruktúra na uchovávanie množiny reťazcov. Ide o stromy, ktoré nemusia byť binárne:
- Uzol lexikografického stromu má najviac toľko detí, koľko je znakov v uvažovanej abecede. Každé dieťa je označené iným znakom abecedy. Graficky si môžeme predstaviť tento znak prislúchajúci k hrane spájajúcej ridiča a dieťa.
- Koreň lexikografického stromu zodpovedá prázdnemu reťazcu.
- Uzol v hĺbke k zodpovedá reťazcu dĺžky k, ktorý dostaneme prečítaním písmen na ceste z koreňa do daného uzla.
- Každý uzol lexikografického stromu obsahuje logickú hodnotu vyjadrujúcu, či k nemu prislúchajúci reťazec patrí do množiny reprezentovanej týmto lexikografickým stromom.
- V korektnom lexikografickom strome všetky listy zodpovedajú reťazcom z reprezentovanej množiny.
- Vnútorné vrcholy môžu zodpovedať reťazcu z množiny alebo iba prefixu jedného alebo viacerých takých reťazcov.
Uzly lexikografickéeho stromu budeme reprezentovať šruktúrou node
- Uzol obsahuje obsahuje booleovskú premennú isWord, v ktorej je uložená informácia o tom, či reťazec prislúchajúci k danému uzlu patrí alebo nepatrí do reprezentovanej množiny a pole children smerníkov na jednotlivé deti daného uzla.
- Veľkosť alphSize tohto poľa je rovná veľkosti uvažovanej abecedy.
- V ukážkovom programe uvažujeme abecedu 'a'..'z'.
const int alphSize = 'z' - 'a' + 1;
struct node {
// pole smernikov na deti
node *children[alphSize];
// udava, ci uzol prislucha k slovu z reprezentovanej mnoziny
bool isWord;
};
Samotný lexikografický strom je potom daný iba smerníkom na svoj koreň:
struct trie {
node *root;
};
Inicializácia a likvidácia lexikografického stromu
Nasledujúca funkcia inicializuje prázdny lexikografický strom t:
void trieInit(trie &t) {
t.root = NULL;
}
Uvoľnenie pamäte alokovanej pre podstrom zakorenený v uzle root realizujeme obdobne ako pri binárnych vyhľadávacích stromoch. Jediný rozdiel spočíva v potenciálne väčšom počte detí uzla root.
void destroySubtree(node *root) {
if (root != NULL) {
for (int i = 0; i < alphSize; i++) {
destroySubtree(root->children[i]);
}
delete root;
}
}
Nasledujúca funkcia potom zlikviduje celý lexikografický strom t:
void trieDestroy(trie &t) {
destroySubtree(t.root);
}
Hľadanie v lexikografickom strome
Funkcia trieFind pre daný lexikografický strom t a reťazec word zistí, či slovo word patrí do množiny reprezentovanej stromom t.
- Postupuje po písmenách reťazca word. Kým nedôjde na koniec slova, snaží sa ísť po hranách, ktoré zodpovedajú jednotlivým písmenám.
- V prípade, že v niektorom bode narazí na NULL, slovo word sa v strome nenachádza.
- V opačnom prípade toto slovo dočíta v nejakom uzle v. V takom prípade slovo word patrí do reprezentovanej množiny práve vtedy, keď v->isWord má hodnotu true.
bool trieFind(trie &t, const char *word) {
node *v = t.root;
if (v == NULL) {
return false;
}
for (int i = 0; word[i] != 0; i++) {
int c = word[i] - 'a';
assert(c >= 0 && c < alphSize);
v = v->children[c];
if (v == NULL) {
return false;
}
}
return v->isWord;
}
Vkladanie do lexikografického stromu
Pri vkladaní reťazca do množiny realizovanej lexikografickým stromom často vznikne potreba vytvárať nové uzly tohto stromu. Túto podúlohu realizuje funkcia createNode, ktorá vytvorí nový uzol s hodnotou isWord danou jej argumentom a so všetkými smerníkmi na deti nastavenými na NULL.
node *createNode(bool isWord) {
node *v = new node;
for (int i = 0; i < alphSize; i++) {
v->children[i] = NULL;
}
v->isWord = isWord;
return v;
}
Vloženie reťazca word do lexikografického stromu t potom realizuje funkcia trieInsert, ktorá pracuje nasledovne:
- Začne v koreni stromu, odkiaľ postupuje nižšie smerom k listom.
- V každom uzle sa pozrie na ďalšie písmeno slova word. Ak danému uzlu chýba dieťa pre toto písmeno, vytvorí ho pomocou funkcie createNode. Následne sa presunie do tohto dieťaťa.
- Ak v nejakom uzle v príde na koniec slova word, nastaví hodnotu v->isWord na true.
void trieInsert(trie &t, const char *word) {
if (t.root == NULL) {
t.root = createNode(false);
}
node *v = t.root;
for (int i = 0; word[i] != 0; i++) {
int c = word[i] - 'a';
assert(c >= 0 && c < alphSize);
if (v->children[c] == NULL) {
v->children[c] = createNode(false);
}
v = v->children[c];
}
v->isWord = true;
}
Vymazávanie z lexikografického stromu
Vymazávanie slov z množiny reprezentovanej lexikografickým stromom budeme realizovať prostredníctvom pomocnej rekurzívnej funkcie removeFromSubtree.
- Funkcia z podstromu zakorenenom v uzle root vymaže sufix reťazca word začínajúci na pozícii index.
- Funkcia vráti booleovskú hodnotu podľa toho, či sa pri tomto vymazaní sufixu z daného podstromu vymazal jeho koreň root.
- Ak sa slovo word v reprezentovanej množine nenachádza, funkcia removeFromSubtree vyhlási chybu pomocou funkcie assert.
Funkcia removeFromSubtree pracuje nasledovne:
- Ak je sufix reťazca word začínajúci na indexe index prázdny, nastaví hodnotu root->isWord na false.
- V opačnom prípade funkcia removeFromSubtree zavolá rekurzívne samú seba pre dieťa zodpovedajúce písmenu na pozícii index reťazca word. Ak toto volanie dané dieťa zmaže, prestaví smerník na toto dieťa na NULL.
- V prípade, že po vykonaní jednej z predchádzajúcich dvoch operácií nemá uzol root žiadne dieťa a súčasne má root->isWord hodnotu false, uvoľní pamäť alokovanú pre uzol root a informáciu o jeho zmazaní vráti na výstupe.
bool removeFromSubtree(node *root, const char *word, int index) {
assert(root != NULL);
if (word[index] == 0) {
assert(root->isWord);
root->isWord = false;
} else {
int c = word[index] - 'a';
bool deleted = removeFromSubtree(root->children[c], word, index + 1);
if (deleted) {
root->children[c] = NULL;
}
}
int numChildren = 0;
for (int i = 0; i < alphSize; i++) {
if (root->children[i] != NULL) {
numChildren++;
}
}
if (numChildren == 0 && !root->isWord) {
delete root;
return true;
} else {
return false;
}
}
Samotné odstránenie reťazca word z množiny reprezentovanej stromom t potom realizuje funkcia trieRemove.
void trieRemove(trie &t, const char *word) {
// zavolame rekurziu pre koren stromu
bool rootRemoved = removeFromSubtree(t.root, word, 0);
// ak bol koren odstraneny, nastavime t.root na NULL
if (rootRemoved) {
t.root = NULL;
}
}
Výška lexikografického stromu
Nasledujúca funkcia vypočíta výšku podstromu zakoreneného v uzle root:
int subtreeHeight(node *root) {
if (root == NULL) {
return -1;
}
int maxHeight = -1;
for (int i = 0; i < alphSize; i++) {
int height = subtreeHeight(root->children[i]);
if (height > maxHeight) {
maxHeight = height;
}
}
return maxHeight + 1;
}
Výšku samotného lexikografického stromu t potom spočíta nasledujúca funkcia:
int trieHeight(trie &t) {
return subtreeHeight(t.root);
}
Vypisovanie slov reprezentovaných lexikografickým stromom
Nasledujúca funkcia printSubtree prehľadáva podstrom zakorenený v uzle root a v reťazci s postupne generuje všetky slová z reprezentovanej množiny, ktoré zároveň vypisuje na konzolu. V parametri index dostane hĺbku aktuálneho vrcholu, t.j. pozíciu, v reťazci, na ktorú pridáme ďalší znak.
void printSubtree(node *root, char *s, int index) {
if (root == NULL) {
return;
}
if (root->isWord) {
s[index] = 0; // ukoncenie retazca pred vypisom
printf("%s\n", s);
}
for (int i = 0; i < alphSize; i++) {
s[index] = 'a' + i;
printSubtree(root->children[i], s, index + 1);
}
}
Funkcia triePrint vypisujúca všetky slová v množine reprezentovanej lexikografickým stromom t najprv spočíta výšku stromu t, ktorá je rovná dĺžke najdlšieho reťazca tejto množiny. Následne dynamicky alokuje reťazec dostatočnej dĺžky na uchovanie každého slova množiny a zavolá funkciu printSubtree pre koreň stromu t.
void triePrint(trie &t) {
int height = trieHeight(t);
if (height >= 0) {
char *s = new char[height + 1];
printSubtree(t.root, s, 0);
delete[] s;
}
}
V akom poradí budú slová vypísané?
Ukážka programu s lexikografickým stromom
Na vstupe máme text pozostávajúci zo slov s malými písmenami a pre každé slovo v texte chceme spočítať, koľkokrát sa tam nachádza.
- Jednotlivé slová uložíme pomocou lexikografického stromu a v každom uzle si pamätáme namiesto hodnoty isWord počítadlo count, ktoré udáva, koľkokrát sme príslušné slovo videli na vstupe.
- Počítadlo má hodnotu nula pre prefixy vstupných slov, ktoré samé zatiaľ ako slovo na vstupe neboli.
- Namiesto funkcie treeInsert máme funkciu treeIncrement, ktorá dostane slovo a zvýši jeho počítadlo, pričom ak slovo zatiaľ v strome nebolo, tak ho pridá.
- Podobne by sme na tento účel vedeli upraviť aj implementáciu množiny pomocou binárneho vyhľadávacieho stromu, hašovacej tabuľky, poľa alebo zoznamu.
- Pozor, ak sú kľúče reťazce, na ich porovnanie musíme v týchto implementáciách použiť strcmp, nie ==, < a pod.
Abstraktný dátový typ, ktorý si okrem množiny kľúčov ku každému kľúču pamätá aj ďalšie dáta, sa zvykne nazývať slovník (angl. dictionary, map).
- Tu boli kľúče slová a ďalšie dáta počet výskytov.
- Iný príklad je zoznam kontaktov, kde kľúčom je meno osoby a pre dané meno chceme vrátiť kontaktné údaje danej osoby (emailová adresa, telefón a pod.)
#include <cstdio>
#include <cassert>
#include <cstring>
using namespace std;
const int alphSize = 'z' - 'a' + 1;
// uzol lexikografickeho stromu
struct node {
// pole smernikov na deti
node *children[alphSize];
// pocet vyskytov slova prisluchajuceho uzlu
int count;
};
// cely lexikograficky strom
struct trie {
node *root;
};
// inicializacia prazdneho stormu
void trieInit(trie &t) {
t.root = NULL;
}
// mazanie podstromu s korenom root
void destroySubtree(node *root) {
if (root != NULL) {
for (int i = 0; i < alphSize; i++) {
destroySubtree(root->children[i]);
}
delete root;
}
}
// uvolnenie pamate celeho stromu
void trieDestroy(trie &t) {
destroySubtree(t.root);
}
// vytvorenie noveo uzlu bez deti a s nula vyskytmi
node *createNode() {
node *v = new node;
for (int i = 0; i < alphSize; i++) {
v->children[i] = NULL;
}
v->count = 0;
return v;
}
// zvysenie pocitadla pre slovo word
// ak slovo este nie je v strome, je pridane
void trieIncrement(trie &t, const char *word) {
if (t.root == NULL) {
t.root = createNode();
}
node *v = t.root;
for (int i = 0; word[i] != 0; i++) {
int c = word[i] - 'a';
assert(c >= 0 && c < alphSize);
if (v->children[c] == NULL) {
v->children[c] = createNode();
}
v = v->children[c];
}
v->count++;
}
// vyska podstromu s korenom root
int subtreeHeight(node *root) {
if (root == NULL) {
return -1;
}
int maxHeight = -1;
for (int i = 0; i < alphSize; i++) {
int height = subtreeHeight(root->children[i]);
if (height > maxHeight) {
maxHeight = height;
}
}
return maxHeight + 1;
}
// vyska stromu. t.j. dlzka najdlsieho slova
int trieHeight(trie &t) {
return subtreeHeight(t.root);
}
// vypisanie slov v podstrome lexikografickeho stromu
void printSubtree(node *root, char *s, int index) {
if (root == NULL) {
return;
}
if (root->count > 0) {
s[index] = 0; // ukoncenie retazca pred vypisom
printf("%s %d\n", s, root->count);
}
for (int i = 0; i < alphSize; i++) {
s[index] = 'a' + i;
printSubtree(root->children[i], s, index + 1);
}
}
// vypisanie slov lexikografickeho stromu
void triePrint(trie &t) {
int height = trieHeight(t);
if (height >= 0) {
char *s = new char[height + 1];
printSubtree(t.root, s, 0);
delete[] s;
}
}
int main() {
// inicializacia stromu
trie t;
trieInit(t);
// postupne nacitavanie slov
char word[100];
while (true) {
int count = scanf("%99s", word);
if (count < 1) { // koniec vstupu
break;
}
// pridanie slova resp. zvysenie pocitadla
trieIncrement(t, word);
}
// vypis a uvolnenie pamate
triePrint(t);
trieDestroy(t);
}
Sylaby predmetu
Základy
Konštrukcie jazyka C
- premenné typov int, double, char, bool, konverzie medzi nimi
- podmienky (if, else, switch), cykly (for, while)
- funkcie (a parametre funkcií - odovzdávanie hodnotou, referenciou, smerníkom)
void f1(int x){} //hodnotou
void f2(int &x){} //referenciou
void f3(int* x){} //smerníkom
void f(int a[], int n){} //polia bez & (ostanú zmeny)
void kresli(Turtle &t){} //korytnačky, SVGdraw a pod. s &
Polia, reťazce (char[])
int A[4]={3, 6, 8, 10};
int B[4];
B[0]=3; B[1]=6; B[2]=8; B[3]=10;
char C[100] = "pes";
char D[100] = {'p', 'e', 's', 0};
- funkcie strlen, strcpy, strcmp, strcat
Súbory, spracovanie vstupu
- cin, cout alebo printf, scanf
- fopen, fclose, feof
- fprintf, fscanf
- getc, putc, ungetc, fgets, fputs
- spracovanie súboru po znakoch, po riadkoch, po číslach alebo slovách
Smerníky, dynamicky alokovaná pamäť, dvojrozmerné polia
int i; // „klasická“ celočíselná premenná
int *p; // ukazovateľ na celočíselnú premennú
p = &i; // spravne
p = &(i + 3); // zle i+3 nie je premenna
p = &15; // zle konstanta nema adresu
i = *p; // spravne ak p bol inicializovany
int * cislo = new int; // alokovanie jednej premennej
*cislo = 50;
..
delete cislo;
int a[4];
int *b = a; // a,b su teraz takmer rovnocenne premenne
int *A = new int[n]; // alokovanie 1D pola danej dlzky
..
delete[] A;
int **a; // alokovanie 2D matice
a = new int *[n];
for (int i = 0; i < n; i++) a[i] = new int[m];
..
for (int i = 0; i < n; i++) delete[] a[i];
delete[] a;
Abstraktné dátové typy
Abstraktný dátový typ dynamické pole (rastúce pole)
- operácie init, add, get, set, length
Abstraktný dátový typ dynamická množina (set)
- operácie init, contains, add, remove
- implementácie pomocou
- neutriedeného poľa
- utriedeného poľa
- spájaných zoznamov
- hašovacej tabuľky
- binárnych vyhľadávacích stromov
- lexikografického stromu (ak kľúč je reťazec)
Abstraktné dátové typy rad a zásobník
- operácie pre rad (frontu, queue): init, isEmpty, enqueue, dequeue, peek
- operácie pre zásobník (stack): init, isEmpty, push, pop
- implementácie: v poli alebo v spájanom zozname
- využitie: ukladanie dát na spracovanie, odstránenie rekurzie
- kontrola zátvoriek a vyhodnocovanie výrazov pomocou zásobníka
Dátové štruktúry
Spájané zoznamy
struct node {
int data;
node* next;
};
struct linkedList {
node* first;
};
void insertFirst(linkedList &z, int d){
/* do zoznamu z vlozi na zaciatok novy prvok s datami d */
node* p = new node; // vytvoríme nový prvok
p->data = d; // naplníme dáta
p->next = z.first; // uzol ukazuje na doterajší začiatok
z.first = p; // tento prvok je novým začiatkom
}
Binárne stromy
struct node {
/* vrchol stromu */
dataType data;
node * left; /* lave dieta */
node * right; /* prave dieta */
};
node * createNode(dataType data, node *left, node *right) {
node *v = new node;
v->data = data;
v->left = left;
v->right = right;
return v;
}
- prehľadávanie inorder, preorder, postorder
- použitie na uloženie aritmetických výrazov
Binárne vyhľadávacie stromy
- vrcholy vľavo od koreňa menší kľúč, vpravo od koreňa väčší
- insert, find, remove v čase závisiacom od hĺbky stromu
Lexikografické stromy
- ukladajú množinu reťazcov
- nie sú binárne: vrchol môže mať veľa detí
- insert, find, remove v čase závisiacom od dĺžky kľúča, ale nie od počtu kľúčov, ktoré už sú v strome
struct node { // uzol lexikografickeho stromu
bool isWord; // je tento uzol koncom slova?
node* next[Abeceda]; // pole smernikov na deti
};
Hašovanie
- hašovacia tabuľka veľkosti m
- kľúč k premietneme nejakou funkciou na index v poli (0,...,m-1}
- každé políčko hašovacej tabuľky spájaný zoznam prvkov, ktoré sa tam zahašovali
- v ideálnom prípade sa prvky rozhodia pomerne rovnomerne, zoznamy krátke, rýchle hľadanie, vkladenie, mazanie
- v najhoršom prípade všetky prvky v jednom zozname, pomalé hľadanie a mazanie
int hash(int k, int m){ // veľmi jednoduchá hašovacia funkcia, v praxi väčšinou zložitejšie
return abs(k) % m;
}
struct node {
int data;
node* next;
};
struct set {
node** data;
int m;
};
Algoritmy
Rekurzia
- Rekurzívne funkcie
- Vykresľovanie fraktálov
- Prehľadávanie s návratom (backtracking)
- Vyfarbovanie
- Prehľadávanie stromov
Triedenia
- nerekurzívne: Bubblesort, Selectionsort, Insertsort
- rekurzívne: Mergesort, Quicksort
- súvisiace algoritmy: binárne vyhľadávanie
Matematické úlohy
- Euklidov algoritmus, Eratostenovo sito
- Práca s aritmetickými výrazmi: vyhodnocovanie postfixovej formy, prevod z infixovej do postfixovej, reprezentácia vo forme stromu
Prednáška 23
Nepreberané črty jazykov C a C++
Dnešná prednáška bude venovaná (pomerne plytkému) prehľadu rôznych čŕt jazykov C a C++, ktoré sa počas semestra nepreberali. Tento prehľad by mal poslúžiť ako pomôcka pri štúdiu existujúcich programov, resp. ako inšpirácia pre ďalšie samoštúdium.
Znalosť materiálu z tejto prednášky nebude vyžadovaná na skúške. Rovnako nie je odporúčané na skúške tento materiál využívať bez dôkladného samostatného oboznámenia sa s ním.
Táto prednáška nepokrýva objektovo-orientované programovanie v jazyku C++. Objektovo-orientované programovanie (v jazyku Java) bude hlavnou náplňou druhého semestra programovania.
Rozdiely medzi jazykmi C a C++
Jazyk C vznikol okolo roku 1972 na podporu vývoja operačného systému Unix; jazyk C++ okolo roku 1985. Programy v jazyku C sú väčšinou súčasne aj korektnými programami v jazyku C++ (ide ale o isté zjednodušenie). Obidva tieto jazyky existujú vo viacerých štandardoch, v ktorých sa postupne pridávali nové črty.
V priebehu semestra sme programovali v jazyku C++. Veľká časť konštrukcií, ktoré sme v programoch využívali, však pochádza už z jazyka C. Výnimkami sú však napríklad nasledujúce črty jazyka C++, ktoré v jazyku C nie sú k dispozícii:
- V jazyku C nie je možné predávanie parametrov funkcií referenciou. Namiesto toho je potrebné používať smerníky.
- V jazyku C nefungujú operátory new a delete. Namiesto nich treba použiť funkcie popísané nižšie.
- Na používanie typu bool a konštánt true a false je potrebná knižnica stdbool (t. j. #include <stdbool.h>). Zabudovaný booleovský typ má názov _Bool a nadobúda hodnoty 0 a 1.
- Štandardnými knižnicami jazyka C sú spomedzi štandardných knižníc jazyka C++ v zásade tie začínajúce písmenom c, napríklad cstdio. Namiesto #include <cstdio> potom v C píšeme #include <stdio.h>.
- V jazyku C špeciálne nie je možné používať knižnicu iostream a v nej definované štandardné vstupno-výstupné prúdy cin a cout.
- V jazyku C je potrebné pri deklarácii premennej typu struct struktura písať aj kľúčové slovo struct.
- V starších verziách jazyka C nefungujú mnohé konštrukcie jazyka C++, ktoré sme bežne používali – napríklad komentáre vo forme //, deklarácie premenných inde ako na začiatku funkcie, atď.
Nepreberané črty jazyka C (použiteľné aj v C++)
Enumerované typy
Enumerované typy pozostávajú z vymenovania niekoľkých hodnôt, ktoré sa stanú celočíselnými konštantami. To je občas užitočné na sprehľadnenie zdrojového kódu.
Príklad:
#include <iostream>
using namespace std;
int main(void) {
enum farba {biela, modra, cervena, zelena, cierna}; // definicia enumerovaneho typu farba
farba f = biela; // definicia premennej typu farba
f = zelena; // priradenie do premennej typu farba
cout << f << endl; // vypise 3
return 0;
}
Zložený typ (union)
Zložený typ umožňuje na jednom mieste pamäte uchovávať hodnotu, ktorá môže byť viacerých dátových typov (narozdiel od štruktúr však vždy ide o práve jednu hodnotu). Definuje sa podobne ako štruktúra, avšak s použitím kľúčového slova union namiesto struct.
Príklad:
#include <iostream>
#include <cstring>
using namespace std;
union zlozenyTyp {
int n;
char s[100];
};
int main() {
zlozenyTyp z;
z.n = 10;
cout << z.n << endl; // vypise 10
strcpy(z.s, "abcd");
cout << z.s << endl; // vypise abcd
cout << z.n << endl; // vypise nejaky nezmysel
}
Napríklad pri aritmetických stromoch by použitie zloženého typu umožnilo ušetriť trochu pamäte tým, že by sme si v každom uzle pamätali buď jeho hodnotu, alebo operátor, pričom typ uzla by sme rozlišovali podľa toho, či sú smerníky na oboch synov rovné NULL.
Operátory
Okrem operátorov, ktoré sme používali, existuje niekoľko ďalších, ako napríklad nasledujúce:
- Bitové operátory pracujú s celým číslom ako s poľom bitov (vhodnejšie sú unsigned typy):
- << a >> posúvajú bity doľava a doprava, zodpovedajú násobeniu a deleniu mocninami dvojky.
- & (and po bitoch), | (or po bitoch), ^ (xor po bitoch), ~ (negácia po bitoch).
- Ternárny operátor ? s použitím (podmienka)?(hodnota pre true):(hodnota pre false), napríklad cout << x << " je " << ((x%2==0) ? "parne" : "neparne") << endl;
Cyklus do-while
Cyklus do-while je obdobou cyklu while s vyhodnocovaním podmienky na konci iterácie. Nasledujúce dva spôsoby písania cyklu sú viac-menej ekvivalentné:
do {
prikazy;
} while(podmienka);
while (true) {
prikazy;
if (!podmienka) break;
}
Makrá a konštanty
Konštantu možno zadefinovať napríklad aj takto:
#define MAXN 100
Narozdiel od konštanty s definíciou
const int maxN = 100;
sa tu konštantná premenná MAXN reálne nevytvára (nevyhradzuje sa pre ňu pamäťové miesto); všetky výskyty MAXN sú preprocesorom kompilátora nahradené „ešte v zdrojovom kóde” konštantou 100.
Okrem konštánt možno definovať aj zložitejšie makrá s parametrami:
/* Definicia makra: */
#define MIN(X,Y) ((X) < (Y) ? (X) : (Y))
/* Priklad pouzitia: */
cout << MIN(a*a, b+5);
/* Preprocesor vykona substituciu za MIN, ktorou dostane: */
cout << ((a*a) < (b+5) ? (a*a) : (b+5));
- Bez dostatočného množstva zátvoriek by pri použití makra MIN mohlo dôjsť k „interakcii s okolím”.
- Vo všeobecnosti je odporúčané vyvarovať sa použitia makier.
Delenie programu na súbory
Väčšie programy je zvyčajne žiadúce rozdeliť na viacero zdrojových súborov. Často sa tiež môže zísť vytvorenie vlastnej knižnice.
Kompilátory, ako napríklad g++, spravidla umožňujú skompilovať viacero zdrojových súborov naraz. Pri volaní g++ z príkazového riadku môžeme písať napríklad
g++ -o program subor1.cpp subor2.cpp subor3.cpp
Takéto volanie ale môže byť úspešné len za dvoch podmienok:
- Funkciu main musí obsahovať práve jeden z kompilovaných zdrojových súborov.
- Ak sa v niektorom súbore suborA.cpp využíva funkcia f z iného súboru suborB.cpp, musí byť funkcia f v súbore suborA.cpp zadeklarovaná (t. j. uvedie sa hlavička funkcie f nasledovaná bodkočiarkou, bez samotného tela – čiže definície – funkcie f).
V súbore lib.cpp môžeme mať napríklad definície dvoch funkcií f a g:
/* Subor lib.cpp */
int f(int n) {
return n + 1;
}
int g(int n) {
return n*2;
}
Môžeme teraz do súboru prog.cpp napísať program, ktorý tieto funkcie deklaruje a následne využíva:
/* Subor prog.cpp */
#include <iostream>
using namespace std;
int f(int n);
int g(int n);
int main(void) {
int n;
cin >> n;
cout << f(n) << " " << g(n) << endl;
return 0;
}
Program potom možno skompilovať volaním
g++ -o prog prog.cpp lib.cpp
Manuálne deklarovanie všetkých funkcií môže byť obzvlášť pri veľkých knižniciach a programoch pozostávajúcich z veľkého množstva súborov ťažkopádne. Typickým riešením je preto presunutie všetkých deklarácií do špeciálneho hlavičkového súboru (angl. header file), v našom prípade napríklad lib.h. Direktíva #include "lib.h" potom prekopíruje do súboru, ktorý ju obsahuje, kompletný obsah súboru lib.h, čím sa vlastne deklarujú všetky funkcie z knižnice lib.cpp.
Pre náš príklad vyššie tak teraz máme 3 súbory. Súbor lib.cpp je rovnaký ako vyššie, súbor lib.h obsahuje
/* Subor lib.h */
int f(int n);
int g(int n);
a súbor prog.cpp obsahuje
/* Subor prog.cpp */
#include "lib.h"
#include <iostream>
using namespace std;
int main(void) {
int n;
cin >> n;
cout << f(n) << " " << g(n) << endl;
return 0;
}
Program skompilujeme rovnako ako vyššie:
g++ -o prog prog.cpp lib.cpp
Rozdiel medzi direktívami #include "lib.h" a #include <lib.h> spočíva v tom, že kým v prvom prípade sa hlavičkový súbor hľadá najprv v aktuálnom adresári, v druhom prípade sa prehľadávajú iba adresáre, ktoré sú na danom systéme predvolené (typicky ide o adresáre obsahujúce hlavičky štandardných knižníc).
Zopár užitočných funkcií
Alokácia pamäte
- V jazyku C nie sú definované operátory new a delete, resp. new[] a delete[].
- Pamäť sa alokuje funkciou malloc, ktorá alokuje kus pamäte s daným počtom bajtov.
- V prípade neúspechu vráti NULL.
- V prípade úspechu vráti smerník na void, ktorý je následne nutné pretypovať.
- Uvoľnenie pamäte realizuje funkcia free.
- Pri výpočte veľkosti potrebnej pamäte sa zvyčajne používa operátor sizeof.
#include <cstdlib> // resp. #include <stdlib.h> v C
/* vytvorime pole 100 int-ov */
int *a = (int *)malloc(sizeof(int) * 100);
/* odalokujeme pole a */
free(a);
Triedenie
- Funkcia qsort z knižnice stdlib.h.
- Dostane pole, počet jeho prvkov, veľkosť každého prvku a funkciu, ktorá porovná dva prvky.
- Funkciu teda posielame ako parameter.
- Táto porovnávacia funkcia dostane dva smerníky typu void * (na dva prvky poľa).
- Vráti záporné číslo, ak prvý prvok je menší, nulu, ak sú rovnaké a kladné číslo, ak je prvý väčší.
- Ak si napíšeme porovnávaciu funkciu, môžeme triediť prvky hocijakého typu.
int compare(const void *a, const void *b) {
return (*(int*)a - *(int*)b);
}
int a[] = {5, 3, 2, 4, 1};
qsort(a, 5, sizeof(int), compare);
- Existuje napríklad aj funkcia bsearch na binárne vyhľadávanie v utriedenom poli.
Nepreberané črty jazyka C++
Generické funkcie
Občas sa zíde napísať algoritmus, ktorý by mohol pracovať na dátach rôznych typov. Napríklad triediť môžeme celé alebo desatinné čísla, reťazce, zložitejšie štruktúry s určitým kľúčom a pod.
V C++ sa dajú písať takzvané generické funkcie, ktoré možno „parametrizovať” podľa typu:
#include <iostream>
using namespace std;
template <typename T>
T vratPrvok(T *a, int k) {
T result = a[k];
return result;
}
int main() {
int a[5] = {1,2,3,4,5};
cout << vratPrvok(a, 1) << endl; // vypise 2
}
- Viac v letnom semestri.
Preťaženie operátorov
Pre novovytvorené typy je možné štadardným operátorom jazyka C++ priradiť novú sémantiku pomocou tzv. preťaženia. Napríklad v nasledujúcom príklade definujeme operátor < na menách, ktorý najprv porovnáva podľa priezviska a následne podľa krstného mena.
struct meno {
char *krstne, *priezvisko;
};
bool operator < (const meno &x, const meno &y) {
return strcmp(x.priezvisko, y.priezvisko) < 0
|| strcmp(x.priezvisko, y.priezvisko) == 0
&& strcmp(x.krstne, y.krstne) < 0;
}
- Podobne môžeme zadefinovať napríklad operátory + a * pre štruktúry reprezentujúce polynómy alebo komplexné čísla...
- cout << "Hello" používa preťažený operátor << pre výstupný prúd na ľavej strane a reťazec na pravej strane.
Reťazce typu string
- V C++ je možné okrem klasických C-čkových reťazcov použiť aj typ string z C++.
- Jeho použitie je elegantnejšie, sám si určuje potrebnú veľkosť pamäte.
- Reťazce tohto typu sú objekty, do funkcií ich odovzdávame väčšinou referenciou.
- K jednotlivým znakom pristupujeme pomocou [] (ako u polí) alebo pomocou metódy at.
#include <string>
#include <iostream>
using namespace std;
int main() {
char cstr[100] = "Ahoj\n";
string str = "Ako sa mas?\n";
string str2;
/* Do str mozno pomocou operatora = korektne priradit konstantne retazce,
C-ckove retazce (polia znakov), aj ine premenne typu string. */
str2 = "Ahoj\n";
str2 = cstr;
str2 = str;
/* Meranie dlzky retazca: */
cout << "Dlzka je: " << str.length() << endl;
/* Funguje porovnanie pomocou ==, !=, <, ...
* (bud dvoch C++ stringov, alebo C++ stringu a C stringu)
* Pomocou operatora + mozno realizovat zretazenie. */
str2 = cstr + str;
str2.push_back('X'); // prida jeden symbol na koniec retazca
str2.push_back('\n');
cout << str2 << endl;
if (str < str2) {
cout << "Prvy je mensi" << endl;
} else if (str == str2) {
cout << "Rovnaju sa" << endl;
} else {
cout << "Druhy je mensi" << endl;
}
}
- Pomocou metódy c_str() možno získať z reťazca typu string premennú typu const char*.
Dátová štruktúra vector
Súčasťou štandardnej knižnice jazyka C++ je viacero rôznych dátových štruktúr. Ide pritom o generické štruktúry, ktoré môžu uchovávať dáta rôznych typov (čo je o poznanie elegantnejšie riešenie, ako to naše s dataType; v jednom programe napríklad môžeme mať štruktúry uchovávajúce rôzne typy).
Na tomto mieste spomeňme dátovú štruktúru vector [1]:
- O niečo podarenejšia verzia dynamických polí z prednášky.
- Deklarovať ho možno jedným z nasledujúcich spôsobov:
vector<int> a; // vytvori pole celych cisel
vector<int> a(10); // vytvori pole 10 celych cisel, ktore vsetky nastavi na vychodziu hodnotu
vector<int> a(5,1); // vytvori pole 5 celych cisel, ktore nastavi na 1
- Prístup k prvkom vector-u je možný dvoma spôsobmi:
- Klasicky pomocou a[index] – podobne ako pri poliach sa ale v takom prípade nekontroluje rozsah.
- Alternatívne možno použiť a.at(index) – v prípade indexu mimo rozsahu program hneď spadne (presnejšie vyhodí výnimku) a nenarobí chaos v pamäti.
- V obidvoch prípadoch môžeme aj priraďovať: a[index] = value; a.at(index) = value;
- Ďalšie metódy na prácu s vector-mi:
- a.push_back(x) vloží hodnotu x ako nový prvok na koniec poľa, podľa potreby pritom pole realokuje a pod.
- a.size() vráti počet prvkov v poli.
- a.resize(n) alebo a.resize(n, value) zmení počet prvkov v poli na n, pričom buď zahodí nadbytočné prvky alebo pridá nové – tie budú mať hodnotu value alebo východziu hodnotu.
#include <vector>
#include <iostream>
using namespace std;
int main() {
vector<int> a;
for (int i = 0; i <= 10; i++) {
a.push_back(i);
}
for (int i = 0; i < a.size(); i++) {
cout << a[i] << endl; // alebo a.at(i)
}
}
Algoritmus na triedenie:
- V knižnici <algorithm>
//triedime normalne pole
int A[6] = {1, 4, 2, 8, 5, 7};
sort(A, A + 6);
//triedime vektor
vector <int> A;
sort(A.begin(), A.end());
//triedime podla nasej porovnavacej funkcie, napr. podla absolutnej hodnoty
struct cmp {
bool operator()(int x, int y) { return abs(x) < abs(y); }
};
cmp c;
sort(A.begin(), A.end(), c);
Range-based for loop
- Špeciálny cyklus cez prvky vektora a pod.
- nepotrebujeme zavádzať premennú pre index
- podobný for cyklus uvidíte podrobnejšie v Jave
#include <iostream>
#include <vector>
using namespace std;
void vypis(const vector<int> &a) {
// vypise vsetky prvky vektora a
for (const int &value : a) {
cout << value << ' ';
}
cout << '\n';
}
int main() {
vector<int> a;
// do vektora a vlozi prvky 0,..,5
for(int value : {0,1,2,3,4,5}) {
a.push_back(value);
}
vypis(a); // vypise 0 1 2 3 4 5
// zvysi kazdy prvok vektora o 1
for (int &value : a) {
value++;
}
vypis(a); // vypise 1 2 3 4 5 6
}